近期,深度求索(DeepSeek)发布第二代开源模型。其创新的模型结构,引发了市场对于算力需求究竟将如何演进的广泛讨论。我们认为,公司在模型架构侧的创新表观上实现了推理时大幅降低KV Cache访存开销且不增加额外计算量,看似对硬件有“降规”指引,但是,更低的推理成本会在中长期维度激发更多需求,反哺算力硬件市场增长。同时,我们认为大模型厂商推理环节的盈利能力正逐步改善,算力硬件需求持续性较高。
摘要
MLA创新架构使推理任务中占用的KV Cache大幅降低,提高硬件利用效率。在主流Transformer网络结构中,多头注意力机制Multi-Head Attention(MHA)是重要的组成部分。为了大幅简化无效重复计算,一般采用缓存MHA中Key和Value的方法(KV Cache)来优化推理任务效率。但随着输入上下文窗口长度的增加,传统MHA中的KV Cache数据量会大幅增长,给推理任务访存制造了瓶颈。DeepSeek-V2模型通过引入Multi-Head Latent Attention(MLA)将KV矩阵压缩到潜在空间来大幅降低所需缓存的数据量,且并不引入额外计算开销,巧妙的降低了推理成本,但在训练端,我们认为MLA结构会引入额外计算。针对优化训练成本和效率的问题,DeepSeek-V2则是在前馈网络中引入并改进了MoE架构。
大模型厂商推理环节的盈利能力正向改善,驱动生成式AI商业闭环落地。针对推理环节,虽然大模型厂商API的收费标准有所下降,但算力硬件表现提升(TCO的下降)叠加算法工程优化正同步发生,根据我们测算,大模型厂商在推理侧的盈利能力整体显现正向改善的趋势。展望未来,考虑到前期训练硬件基础设施相对海量的前置成本,我们认为大模型厂商API收费标准下调空间有限,伴随着硬件侧算力的提升以及HBM的持续迭代,以及工程优化手段不断涌现,大模型厂商盈利能力有望逐步转正,进一步推动生成式AI产业实现商业闭环,反哺算力硬件需求。
创新架构可能存在的问题?我们认为MLA架构对于低秩联合压缩KV矩阵的方式是否存在性能损失依然不能给出严肃证明。即对于MLA方法能否实现更长文本支持、能否实现更强的泛化能力尚未给出结论。后续该架构的发展依然值得我们持续关注。而且,当前开源模型参数量高达236B,对在硬件有限情况下部署推理任务产生一定的挑战。
风险
Transformer大模型主流网络结构被取代;大模型厂商竞争加剧。
正文
DeepSeek-V2模型结构上引入了什么创新?
在模型Attention结构中引入MLA机制,大幅降低KV Cache进而降低推理成本
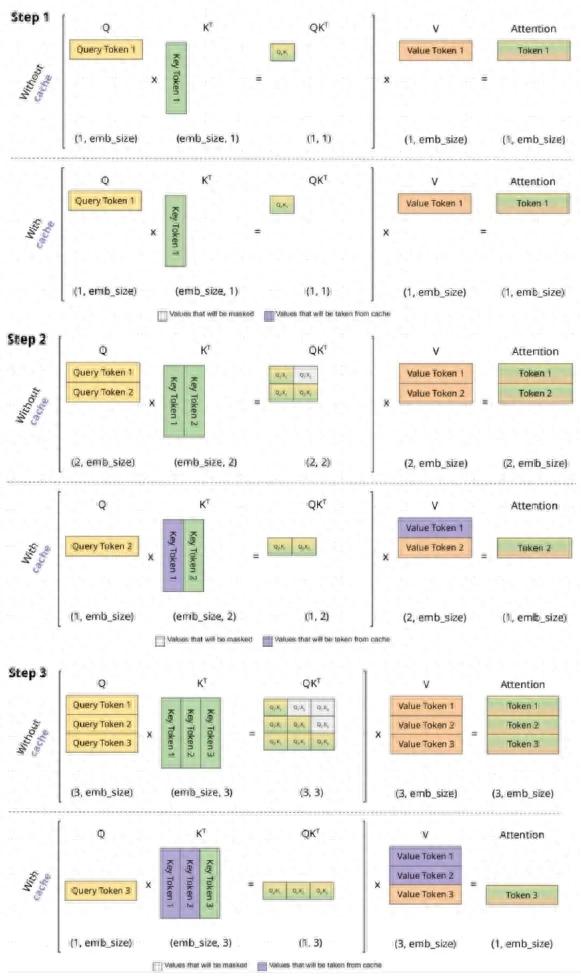
为什么要采用KV Cache,而又为什么要压缩KV Cache?
KV Cache是大模型推理上常用的性能优化技术,通过以存储换计算(或空间换时间)的方式来提升推理性能并优化推理成本。对于自回归类(Decoder Only)大模型,在推理过程中,当输入变量经过embedding层操作后,会得到[b,s,d]维度的矩阵,其中b为batch size,即推理时的任务批量数;s为sequence length,即上下文长度;d为dimension size,即大模型每个Transformer层的隐藏层维度。后续会跟W^Q,W^K,W^V等三个维度为[b,d,d]的方阵相乘,得到Q(Query)、K(Key)、V(Value)三个矩阵。其中V矩阵表示了输入特征,Q、K表示了计算Attention权重的特征。值得注意的是,在采用多头注意力机制(Multi-head Attention,即MHA)的情况下,上述矩阵维度会加上注意力机制头数n_head。
在推理过程中,由于自回归机制的存在,我们发现每一轮自回归过程中,都涉及了当前轮输出token与输入token的拼接,并带入下一轮计算:即第i轮推理时必然包含了第i+1轮的部分计算。KV Cache(即缓存Key、Value)的想法在于可以缓存当前轮推理可重复利用的计算结果,在下一轮推理时可直接读取,这样大大降低了模型推理时的计算量,将每一轮推理的token输入长度都降为1。
在KV Cache存在的环境下,推理的预填充(Prefill)阶段是计算密集型(Compute Bound)应用,解码(Decode)阶段是访存密集型(Memory Bound)应用。在计算首个token的过程中,需要将所有的输入token与每个transformer层进行计算,并初始化KV Cache,计算量要求较大,是计算密集型应用,且无论开启KV Cache与否,这一步计算量均相同;而在计算第二个输出token至最后一个token过程中,此时只要更新当前轮所输出的Key和Value即可,但由于读取KV Cache,此步骤变成了访存密集型应用,内存容量和带宽对整个步骤的性能(时间占用)影响要大于计算本身。
图表:关闭KV Cache与启用KV Cache示意
资料来源:Medium.com,中金公司研究部
KV Cache怎么计算?与数据精度、模型隐藏层维度、模型层数、上下文长度、批量处理数等均有密切关系。在上文中,我们已经阐述了K、V矩阵的计算方式,其维度为[b,s,d]。如果以FP16的数据精度进行KV Cache存储,那么KV Cache所占用显存的大小为2*2*b*s*d*l(其中l为transformer层的数量,第一个系数2代表K Cache和V Cache,第二个系数2代表FP16 数据格式)。如果考虑到多头注意力机制的问题,整个KV Cache公式还可以拆分为与n_head个头相关的形式。我们注意到,KV Cache的数据量会随着模型的复杂度上升,以及上下文窗口长度的增加而呈现线性增长,甚至会超过模型参数本身。Coleman Hopper等人的研究表示 ,对于Llama7B模型来看,当上下文窗口长度仅有512 tokens时,整个显存占用有98%来自于模型权重,仅有2%来自KV Cache;而当上下文窗口长度增加到128K tokens时,整个显存占用有高达84%的比例来自于KV Cache贡献。结合以上分析,我们认为,KV Cache数据量增大可能会对AI芯片显存读取带宽存在较明显挑战,降低GPU使用效率,进而增大GPU使用成本。
图表:KV cache对显存占用会随着长度增加而变大

资料来源:Coleman Hopper et al, KV Quant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization, UC Berkeley, 2023,中金公司研究部
优化KV Cache的出发点在哪里?从以上分析我们可以得知,在模型推理过程中,主要的显存资源占用为weight_size+cache_size*batch_size。由于计算并不是瓶颈,可以增大batch size以提高资源利用率。当KV Cache被优化后,cache size得到明显降低,因此可以大大提升batch_size,即推理任务的并发数,更高的推理服务支持容量即可降低GPU的使用成本(单位时间的利用率是核心指标)。
DeepSeek-V2如何进行KV Cache优化?
对于KV Cache优化,算法工程师也尝试了多种方式。首先是对KV Cache的直接量化。从Coleman等人的研究结果 来看,利用直接量化方式在LLaMA-2-7B及LLaMA-2-70B开源模型上均取得了稳定的输出,在Wikitext-2测试集下,上下文窗口长度在2K-32K之间均能获得不错的困惑度指标。
图表:KV Cache量化后,模型依然能较稳定的输出

资料来源:Coleman Hopper et al, KV Quant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization, UC Berkeley, 2023,中金公司研究部
在多头注意力机制(Multi Head Attention,MHA)的KV Cache优化方面,除了直接量化以外,也存在其他的优化方式。如MQA(Multi Query Attention),通过所有head共用一个Key和Value的方法,抑或是通过GQA(Group Query Attention),即每个多头注意力机制小组内采用MQA,组间采用传统MHA的方法。我们以LLaMA2的实验结果为例,也能看到对推理任务的加速效果优化相对是明显的。
图表:GQA/MQA方式对推理任务的加速效果示例

资料来源:Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288 (2023).,中金公司研究部
但是,以上三种方法多少都可能因量化、合并或分组而丢失细节信息。但是,DeepSeek-V2中采用了名为MLA(Multi-Head Latent Attention)方法,基于尽可能多的原始信息压缩KV Cache。MLA的核心思想是将Key和Value通过投影变换来进行低秩联合压缩(Low-Rank Key-Value Joint Compression),同时也对Query的维度进行低秩压缩,既使得计算量明显降低,同时在显存占用方面,只缓存压缩后潜在空间内的数据,大幅优化了KV Cache的显存消耗。根据DeepSeek-V2技术论文的对比,MLA将单一token对应的KV Cache数据量压缩到了仅MQA的2.25倍,但模型性能依然优秀,且在上下文文本窗口扩展到128K的时候依然保持了良好的性能。
图表:MLA技术可以将KV Cache压缩到更小空间,且实际表现优于其他方法

资料来源:Shao, Zhihong et al. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.” (2024).,中金公司研究部
MLA的代价是什么?
对于具体的推理任务,实行工程化的方式一般都会采用一定的折衷路径。我们在先前《AI浪潮之巅系列:AI端侧落地加速,开启实时互动新纪元》[1]报告中指出,对于计算时间是短板的应用,我们会在不改变硬件的情况下,以“空间换时间”,采用更多的访存来减少计算;而对于访存时间是短板的应用,我们会考虑以“时间换空间”,采用更多的计算来减少访存。
从具体实现逻辑上来看,若KV Cache的空间占用降低,那么对Key和Value的压缩必然会带来额外的计算量:即压缩K/V到潜在空间后,对于Q、K、V的更新均需要C_t^KV与升维矩阵W^UQ,W^UK,W^UV来相乘,而升维操作会增加额外的计算量。但是,DeepSeek-V2论文中指出,在推理过程中,从C_t^KV(潜在空间向量)恢复KV到原空间所需的W^UK矩阵可在计算Attention Score时被合并入W^Q,W^UV可在计算Attention Score时被合并入W^O,因此实际在推理过程中并没有增加计算量。但我们认为,在训练阶段,出于优化梯度更新方式、以及优化模型精度等考虑,训练阶段采用MLA代替MHA,所带来的算力开销还是明显的。
图表:Key和Value的低秩压缩方式

资料来源:Shao, Zhihong et al. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.” (2024).,中金公司研究部
DeepSeek-V2模型对算力硬件性能门槛依然要求较高。DeepSeek-V2参数量达到236B,若以BF16存储数据,单卡内存占用已经接近60GB(我们认为在本身对KV Cache进行空间压缩后,再对数据进行量化可能导致模型输出质量下降),如果上下文长度较长,即便通过MLA结构对KV Cache大幅压缩,我们认为单节点跑通推理难度相对也是比较大的(考虑到A100资源的单卡显存仅为80GB)。但根据DeepSeek-V2论文中的描述,其通过硬件优化、软件工程优化等所带来的吞吐可以很好的覆盖GPU的使用成本。
细颗粒度+共享MOE结构提升计算效率
在训练过程中,DeepSeek-V2在前馈神经网络层FFN中引入混合专家模型MoE,来降低训练成本,提升训练效率。虽然MoE并不属于DeepSeek-V2所独有的创新,但其引入了细粒度专家分割、共享专家隔离等优化方式。
我们看到,伴随Scaling Law的延续,扩大模型参数量以及计算量能够显著提升模型性能,但也意味着更高昂的算力成本支出。在这一背景下,轻量化、稀疏化的混合专家模型(Mixture-of-Experts,MOE)逐渐成为主流趋势。在传统稠密Transformer模型中,前馈神经网络层(Feed-Forward Networks,FFN)参数量占比超过2/3,而针对每次输入,FFN层仅有部分参数被激活,存在一定算力冗余。针对这一问题,MoE模型使用稀疏化的MoE架构替换FFN层 ,以实现针对不同数据的解耦,提升计算效率。
具体来看,MoE架构由专家模型(Experts)和门控系统(Gating Network / Router)构成。专家模型为互相独立的神经网络模型,负责处理输入数据并输出结果,MoE模型中通常有多个专家,擅长处理不同类型的数据或任务,如Switch transformers中使用了四个不同的专家模型。门控系统则根据输入Tokens特点动态地决定其分配去向,在接收数据后,门控系统输出权重,将Tokens分配至权重最高的专家模型处进行处理。相较于稠密模型,稀疏化的MoE架构只需根据输入数据特点调动部分专家模型进行处理,无需复用所有参数,因此MoE架构拥有更高的预训练和推理计算效率,并能够大幅节省算力开支。举例来看,Google在Switch transformers论文中提到,在硬件、单位算力与训练效果相同的前提下,含有64个专家的稀疏模型的训练速度为稠密T5模型的7倍 。
然而,传统的MoE模型也存在知识混合(Knowledge Hybridity)和知识冗余(knowledge redundancy)的问题 。知识混合主要指的是由于当前MoE模型中包含专家数量较少,因此向每个专家输入的数据较为混杂,专家难以基于这样的数据形成专业化、针对性的参数结构。而知识冗余则是指由于某些问题具有共性特征,因此不同专家在处理不同问题时形成了同类知识,导致整体参数的冗余。这两方面的问题致使传统MoE模型的专家在专业化方面难以收敛并难以达到最佳性能。
针对以上问题,DeepSeek提出了DeepSeekMoE架构,这一架构主要采用了两个策略:细粒度专家分割(Fine-Grained Expert Segmentation)、共享专家隔离(Shared Expert Isolation)。细粒度专家分割对应下图中的(b)部分,可以看到,这一策略在保持参数总量不变的前提下,进一步细化专家组合,使得数据划分更加细致,并基于更细颗粒的数据学习为更加准确、专业的专家,更好地解决上文提及的知识混合问题,同时在保持恒定计算成本的情况下激活更多细粒度专家组合,这样灵活的组合也有利于更准确地解决问题。共享专家隔离则对应(c)中的绿框部分,将部分专家单独隔离出来作为共享专家,捕捉上下文的共同知识,解决共性问题,缓解上文提到的知识冗余问题,以达到精简参数、提升计算效率的目的。应用细粒度专家与共享专家的创新,DeepSeekMoE架构能够大幅提升专家的专业化水平与模型整体性能。
图表:DeepSeekMoE采用细粒度专家分割与共享专家隔离策略

资料来源:Dai, Damai, et al. "Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models." arXiv preprint arXiv:2401.06066 (2024).,中金公司研究部
实践同样表明,DeepSeekMoE架构能够在模型激活参数量较小的情况下使模型达到更好性能,并大幅节约预训练成本。在DeepSeekMoE论文[2]的实验中,作者比较了包括DeepSeekMoE在内的多个模型性能表现,其中DeepSeekMoE 16B的性能与LLaMA2 7B相当,而后者的激活参数量和计算量为DeepSeekMoE 16B的2.5倍。根据DeepSeek-V2论文[3],DeepSeek-V2应用了稀疏DeepSeekMoE架构,同样在较小激活参数量与计算量的前提下达到了与Mixtral 8x22B、LLaMA 3 70B等具有其2-3倍激活参数量与计算量模型的相同性能表现。此外,DeepSeek-V2与去年上线的稠密DeepSeek 67B模型相比,在性能提升的同时,节省了42.5%的训练成本。
推理成本快速下降,大模型商业落地时间到来?
当前大模型厂商在推理环节的盈利趋势如何判断?
收入端观察:大模型厂商API收费标准持续下调,以价换量有望打开商业化空间。本章节将站在大模型厂商的视角,观察当前在推理环节的盈利能力趋势。从收入端来看,回溯自2022年11月GPT 3.5发布以来至今,我们认为大模型厂商对于API输入/输出百万Tokens的收费标准整体呈现较为明显的下降态势。据Artificial Analysis,Open AI 在2023年6月发布GPT 4,每百万tokens的API输入/输出价格分别为30/60美元;横向对比2024年5月发布的GPT4o其每百万tokens的API输入/输出价格分别下降至5/15美元(截至2024年5月Artificial Analysis测算价格),在推理速度大幅提升的背景下,API的收费价格明显下降。同时从行业维度看,我们观察到各大模型厂商API输入/输出定价呈加速降低趋势:DeepSeek-V2模型的API价格降至GPT-4的0.5%,智谱AI和火山引擎也相继跟进,进一步压低了GLM-3-Turbo和豆包模型的价格。我们认为大模型厂商的商业模式正逐步迈入以价换量时代,收费标准的价格普遍下降有望吸引更多应用开发者和消费用户,我们看好大模型厂商的市场规模持续增长,商业变现前景广阔。
图表:各大模型厂商API输入定价呈加速降低趋势

资料来源:DeepSeek,Artificial Analysis,各公司官网,中金公司研究部
图表:各大模型厂商API输出定价呈加速降低趋势

资料来源:DeepSeek,Artificial Analysis,中金公司研究部
盈利能力判断:针对推理环节,虽然收费标准有所下降,但算力硬件表现提升叠加算法工程优化,大模型厂商的盈利能力不断正向改善,推理端实现商业闭环值得期待。云端计算包括训练和推理两个过程,首先是对模型的训练,然后用训练出的模型进行推理。由于AI训练相关基础设施建设的前置成本仍在快速提升,本文通过更聚焦地从大模型的推理环节出发,测算当前大模型厂商在推理环节毛利率层面的盈利能力。考虑到相关参数的可得性,提出以下模型和假设条件:
►大模型厂商的收入=input tokens数对应的API价格+ output tokens数对应的API价格;大模型厂商的成本=input/first token latency导致的算力租赁费用+ output/throughput导致的算力租赁费用;
►关键假设:推理属于实时业务,需要响应客户端触发的实际需求,算力需求取决于活跃用户数和设计并发数的级别,因此算力芯片和服务器的投入,会随着模型的商用流行度以及吸引的活跃用户数持续增加。但在具体测算过程中,基于当前数据的可得性和准确性,我们假定了以下的使用条件:
1)单位Tokens的收费标准与Tokens使用数呈现线性关系;
2)成本端:input/first token latency的用时与output/throughput的用时基于Google Cloud's us-central1-a zone的环境模拟产生,假定其使用8卡H100的服务器进行推理;
3)算力租赁价格:据coreweave,截至2024年5月,H100(8卡)租赁价格为15美元/小时;
4)假设均在H100服务器(8卡)中运行推理任务,输入及输出均为10,000个tokens的任务;
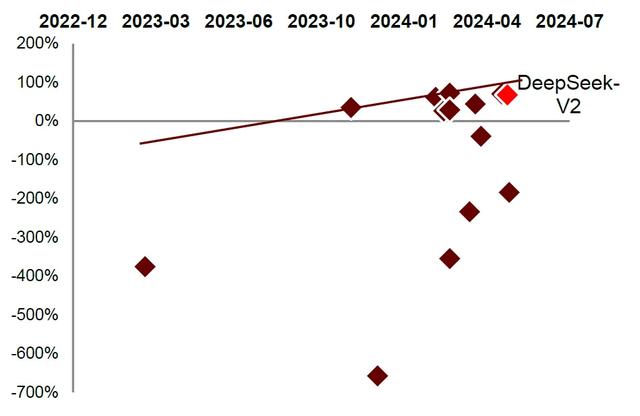
图表:各大模型厂商推理环节的盈利能力(毛利部分)在逐步提升
资料来源:Artificial Analysis,Coreweave,中金公司研究部;
注:以上测算基于多重严格的限制条件,与各厂商实测结果非完全一致,基础假设请参考正文
大模型厂商短期内仍处亏损状态,但推理环节的盈利能力呈现正向提升。根据我们测算,自2022年12月至今,大部分大模型厂商的推理环节盈利能力依然为负向数值,但伴随着单位算力成本的下降以及算法的工程优化,除去少数厂商外,我们看到行业内大部分模型厂商盈利能力正呈现逐步收敛至正向的状态。
短期看,我们认为大模型在推理环节仍然是以流量获取及增加月活用户为主要目的:国际角度看,自2023年以来,ChatGPT月活用户快速破亿,目前以18.6亿月活排名全球AI应用月活榜首,紧随其后的Gemini在5亿左右;同时截至2024年4月,Kimi超越文心一言成为中国大陆AI大模型产品的流量第一,达到2000万。但边际角度看,我们认为经过2023-2024年大模型的蓬勃发展与快速迭代,用户总数增长速率已有所放缓,伴随着大模型厂商推理环节的盈利能力逐步提升,我们认为大模型厂商追求变现的脚步正在变快。
怎样看待大模型厂商变现的时间节点?
考虑到前期训练硬件基础设施的前置成本,API收费标准下调空间有限。大模型训练需要大量资金前期投入,训练较先进大模型的成本已经达到了相对高昂的水平:据斯坦福大学2024年AI指数报告估计,OpenAI的GPT-4训练成本为7800万美元,而谷歌的Gemini Ultra训练成本则高达1.91亿美元。为应对不断增长的训练成本,大模型的融资额也在不断增加;2023年,全球生成式人工智能投资额激增,相较2022年增长近八倍,达到252亿美元。由于目前大模型训练的前置成本仍高昂,我们认为推理侧API收费标准下调空间有限。随着大模型潜在应用的拓展,行业的盈利能力将变得更加关键,我们看好未来大模型厂商通过收入端合理定价,实现更广泛的商业化和可持续发展。
图表:各厂商大模型训练成本逐年增加

资料来源:Stanford Institute for Human-Centered Artificial Intelligence《AI Index Report 2024》,中金公司研究部
图表:2023年全球生成式AI民间投资额激增

资料来源:Stanford Institute for Human-Centered Artificial Intelligence《AI Index Report 2024》,中金公司研究部
硬件-算力芯片:单位算力性价比的提升有望舒缓大模型厂商对于算力租赁成本的压力。根据Epoch AI ,随着时间的推移,GPU FLOP/s(每秒浮点运算次数)的性价比通常每2.5年提高2倍,每8年提高10倍。在GTC大会上,英伟达展示其AI芯片的算力在过去8年里实现了1000倍的增长,意味着AI时代的摩尔定律(算力快速增长和成本快速下降)正在形成。同时,根据英伟达最新发布的NVIDIA GB200 NVL72大型机架系统,其搭配NVIDIA BlueField-3数据处理单元、第五代NVLink互联等技术,对比相同数量H100 Tensor核心的系统,在推理上有高达30倍的性能提升,并将成本和能耗降低了25倍。展望未来,我们认为算力性价比的提升有望给下游大模型公司带来TCO(total cost of ownership)下降,从而释放相关厂商的盈利能力。
硬件-存储:HBM显存带宽速度持续增长,带来推理效率进一步提高。HBM技术通过组成DDR 组合阵列,以实现让更大的模型、更多的参数留在离核心计算更近的地方,从而减少内存和存储解决方案所带来的延迟。例如,Micron推出的HBM3E内存在2024年已经达到每个模块1.2TB/s的峰值内存带宽,对于由 6 个堆栈组成的内存子系统来说,将等效达到7.2 TB/s 的带宽。Micron计划在2026年生产HBM4,将每个堆栈的理论峰值内存带宽提高到 1.5 TB/s 以上,提供更高的带宽和更低的能耗。根据英伟达技术文档,内存带宽对于HPC应用程序至关重要。对于模拟、科学研究和人工智能等内存密集型HPC应用;根据英伟达H200及H100产品的实测结果对比,在算力相当的情形下,HBM参数的提升带动H200在Llama 2 13B/GPT-3 175B/Llama2 70B的环境下推理分别提升1.4/1.6/1.9倍的速度,我们看好内存带宽的技术变革带来推理效率的进一步提高。
图表:每美元的GPU FLOP/s逐年增加

资料来源:Epoch AI,中金公司研究部
图表:英伟达H200相比H100推理性能显著提升

资料来源:英伟达官网,中金公司研究部
算法与工程优化:低精度推理是降低成本、提升推理速度的潜在方向。人工智能处理需要跨硬件和软件平台的全栈创新,以满足神经网络日益增长的计算需求;提高效率的关键之一是使用较低精度的数字格式来提高计算效率、减少内存使用并优化互连带宽。为实现这个目标,行业已从FP32转向FP16/FP8。FP8在硬件和软件之间取得良好的平衡,很大限度地减少了与现有IEEE 754浮点格式的偏差,以提高效率。NVIDIA Hopper架构集成了新的第四代Tensor Core,支持两种新的FP8数据类型:E4M3和E5M2。据英伟达官网, 与FP16相比,FP8的数据类型将Tensor Core吞吐量提高了2倍,并将内存需求降低了2倍。在基准测试MLPerf Inference v2.1中,NVIDIA Hopper通过FP8格式将BERT高精度模型的加速提高了4.5倍,从而在不影响准确性的情况下提高了吞吐量。同时,我们看到行业仍然朝向更低精度的数据类型演进(包括GTC2024引入的FP4数据精度)以提升推理速度。我们看好新的数据精度减少推理耗费时长,从而降低算力使用时长以减少大模型厂商的成本承担。
算法与工程优化:增大批次规格(Batch Size)是提高推理效率的最有效方式之一。同时处理的推理负载的数量被称为Batch Size。据论文Batch Prompting: Efficient Inference with Large Language Model APIs ,在少数样本(few-shot)的上下文学习场景下,推理成本几乎与每批样本的数量成反比。此外,模型并行化通过分散内存和计算占用空间,可以运行更大的模型或更大批量的输入。我们认为在算力系统部署过程中,可以通过将较大的批次传输到GPU进行一次处理,从而更充分地利用可用的计算资源,显著减少LLM的推理词元和时间成本。
风险提示
大模型厂商竞争加剧
据上文所述,当前伴随模型架构优化与工程优化,大模型推理端价格持续下探,行业竞争加剧。大模型产品需要兼具低价与差异化性能优势以抢占市场、回收现金流。然而,兼具高性能与低成本优势的模型需要更加密集的技术与资金投入,竞争壁垒提升,或将导致行业出清加速。
Transformer大模型主流网络结构被取代
Transformer对于长文本的自注意力机制的计算量会随着上下文长度的增加呈平方级增长,因此带来了高昂计算成本和内存占用。我们观察到,为解决Transformer固有的局限性,一些非Transformer架构模型被提出,如Mamba、RWKV、Retnet等架构,通过优化Memory或稀疏化的方式提升计算效率,降低训练与推理的成本,可能对Transformer在大模型领域的领导地位构成威胁。
[1]https://www.research.cicc.com/zh_CN/report?id=340440&entrance_source=search_all_reportlist&page=12&yPosition=143.3
[2]https://arxiv.org/pdf/2401.06066
[3]https://arxiv.org/pdf/2405.04434
文章来源
本文摘自:2024年5月28日已经发布的《智算未来系列八:大模型持续迭代,算力需求不升反降?》
成乔升 分析员 SAC 执证编号:S0080521060004
黄天擎 分析员 SAC 执证编号:S0080523060005 SFC CE Ref:BTL932
彭虎 分析员 SAC 执证编号:S0080521020001 SFC CE Ref:BRE806
臧若晨 分析员 SAC 执证编号:S0080522070018 SFC CE Ref:BTM305
石晓彬 分析员 SAC 执证编号:S0080521030001
贾顺鹤 分析员 SAC 执证编号:S0080522060002 SFC CE Ref:BTN002
法律声明

