大型语言模型(LLMs)通常因为体积过大而无法在消费级硬件上运行。这些模型可能包含数十亿个参数,通常需要配备大量显存的GPU来加速推理过程。
因此越来越多的研究致力于通过改进训练、使用适配器等方法来缩小这些模型的体积。在这一领域中,一个主要的技术被称为量化。

在这篇文章中,我将在语言建模的背景下介绍量化,并逐一探讨各个概念,探索各种方法论、用例以及量化背后的原理。
大型语言模型(LLMs)的问题大型语言模型之所以得名,是因为它们包含的参数数量。这些模型通常拥有数十亿个参数,存储这些参数可能相当昂贵。
在推理过程中,激活值是输入和权重的乘积,同样可能非常庞大。
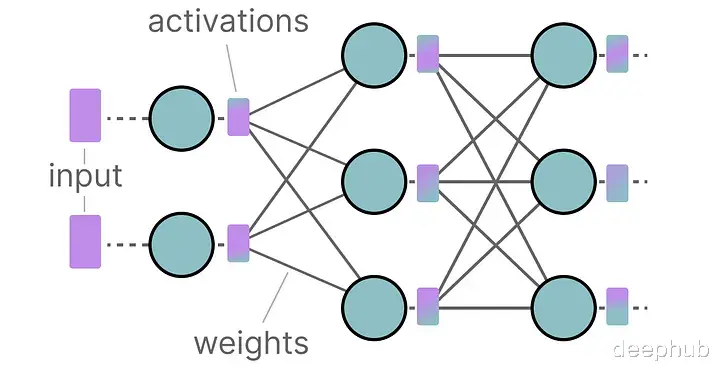
所以我们希望尽可能有效地表示数十亿个数值,最小化存储给定值所需的空间。
让我们从头开始,探索在优化之前如何首先表示数值。
如何表示数值在计算机科学中,一个给定的数值通常表示为浮点数(或称为浮点),即带有小数点的正数或负数。
这些数值由“位”或二进制数字表示。IEEE-754标准描述了如何使用位来表示一个值的三个功能之一:符号、指数或小数部分(或称尾数)。

这三个方面一起可以用来计算给定一组位值的值:

我们用越多的位来表示一个值,它通常就越精确:

可用的位数越多,能表示的数值范围就越大。

可表示数字的区间被称为动态范围(dynamic range),而两个相邻数值之间的距离被称为精度(precision)。

这些位的一个巧妙特性是,我们可以计算设备存储给定值需要多少内存。由于一字节内存中有8位,我们可以为大多数形式的浮点表示创建一个基本公式。

实际上,在推理过程中,需要的(V)RAM量还与上下文大小和架构等因素有关。但是这部分影响比较小,我们暂时忽略不计。
现在假设我们有一个模型,包含700亿个参数。大多数模型默认使用32位浮点数(通常称为全精度)表示,仅加载模型就需要280GB的内存。

因此最小化表示模型参数的位数(包括在训练期间)变得非常重要。但是随着精度的降低,模型的准确性通常也会下降。所以我们希望在保持准确性的同时减少表示数值的位数……这就是量化的用武之地!
量化简介量化旨在将模型参数的精度从高位宽(如32位浮点数)降低到低位宽(如8位整数)。

在减少表示原始参数的位数时,通常会有一些精度(细粒度)的损失。为了说明这种效应,我们可以拿任何一幅图像,仅使用8种颜色来表示它。

放大部分看起来比原图更“粗糙”,因为我们用更少的颜色来表示它。量化的主要目标是在尽可能保持原始参数的精度的同时,减少表示原始参数所需的位数(颜色)。
常见数据类型首先让我们来看看常见的数据类型以及使用它们替代32位(称为全精度或FP32)表示的影响。
FP16让我们看一个从32位到16位(称为半精度或FP16)浮点数的例子:

FP16能表示的数值范围比FP32小很多。
BF16为了获得与原始FP32相似的数值范围,后来又引入了一种名为bfloat 16的“截断FP32”类型:

BF16使用与FP16相同的位数,但可以表示更广泛的数值范围,常用于深度学习应用中。
INT8当我们进一步减少位数时,我们接近基于整数的表示而不是浮点表示。例如,从FP32转换到只有8位的INT8,结果是原始位数的四分之一:

根据硬件不同,基于整数的计算可能比浮点计算更快,但这并不总是如此,使用更少的位进行计算通常会更快。每次减少位数时,都会执行一个映射,将初始的FP32表示“压缩”到较低的位数中。
在实际应用时我们不需要将整个FP32范围[-3.4e38, 3.4e38]映射到INT8。我们只需要找到一种方法,将我们数据的范围(模型的参数的最大值和最小值内)映射到INT8。
常见的压缩/映射方法有对称和非对称量化,它们是线性映射的形式。
对称量化在对称量化中,原始浮点值的范围被映射到量化空间中以零为中心的对称范围。在之前的例子中,注意量化前后的范围如何保持围绕零对称。
这意味着浮点空间中零的量化值在量化空间中恰好是零。

对称量化的一个很好的例子被称为绝对最大值(absmax)量化。
给定一系列值,我们取最大的绝对值(α)作为执行线性映射的范围。

请注意,[-127, 127] 的值范围代表受限范围。不受限的范围是 [-128, 127],这取决于量化方法。
由于这是一个以零为中心的线性映射,公式非常直接。
我们首先使用以下公式计算比例因子(*s*):
b 是我们想要量化到的字节数(8),
α 是最大的绝对值,
然后,我们使用 s 来量化输入 x:

填入这些值会得到以下结果:

为了检索原始的FP32值,我们可以使用先前计算的缩放因子(*s)来去量化量化值。

应用量化和去量化的过程来检索原始流程图解,如下所示:

可以看到某些值,例如 3.08 和 3.02,在量化为 INT8 时被赋予了相同的值,即 36。这是因为将这些值反量化回 FP32 时,它们会失去一些精度,不再能够被区分开来。
这通常被称为量化误差,我们可以通过找出原始值和反量化值之间的差异来计算这一误差。

一般来说,比特数越低,我们的量化误差就越大。
非对称量化与对称量化不同的是,非对称量化不是围绕零对称的。它将浮点范围中的最小值(β)和最大值(α)映射到量化范围的最小值和最大值。
我们将要探讨的方法称为零点量化。

看到0的位置如何发生了变化吗?这就是为什么它被称为非对称量化。在范围[-7.59, 10.8]内,最小/最大值到0的距离是不同的。
由于其位置的偏移,我们必须为INT8范围计算零点,才能执行线性映射。像之前一样也必须计算一个比例因子(s)。

由于需要计算INT8范围内的零点(z)来移动权重,这个过程略显复杂。
如之前所述,公式如下:

为了将从INT8量化的数据反量化回FP32,需要使用之前计算的比例因子(s)和零点(z)。

当把对称和非对称量化放在一起时,可以很快看到方法之间的区别:

可以明显的看到对称量子化的零中心特性与非对称量子化的偏移量。
范围映射与裁剪在之前的例子中,探讨了如何将给定向量中的值范围映射到较低位的表示。尽管这允许将向量值的完整范围映射出来,但它带来了一个主要的缺点,即异常值。
假设有一个向量,其值如下:

其中一个值比其他所有值都大得多,可以被认为是一个异常值。如果我们要映射这个向量的完整范围,所有小的值都会被映射到相同的较低位表示,并且失去它们的区分因素:

这就是我们之前使用的absmax方法。如果我们不应用裁剪,非对称量化也会发生同样的行为。
所以我们可以选择裁剪某些值。裁剪涉及设置原始值的不同动态范围,使得所有异常值获得相同的值。
在下面的例子中,手动将动态范围设置为[-5, 5],那么所有超出该范围的值将被映射到-127或127,无论它们的实际值如何:

其主要优点是显著降低了“非异常值”的量化误差。但是会导致离群值的量化误差增大。
校准上面展示了一种选择[-5, 5]任意范围的简单方法。选择这个范围的过程被称为校准,其目的是找到一个范围,包括尽可能多的值,同时最小化量化误差。
执行这一校准步骤对所有类型的参数来说并不相同。
权重(和偏置)我们可以将LLM的权重和偏置视为静态值,因为在运行模型之前就已知这些值。例如,Llama 3的~20GB文件主要由其权重和偏置组成。

由于偏置的数量(百万级)远少于权重(十亿级),偏置通常保持较高的精度(如INT16),量化的主要工作集中在权重上。
对于已知且固定的权重,可选择范围的校准技术包括:
手动选择输入范围的百分位数
优化原始权重和量化权重之间的均方误差(MSE)
最小化原始值和量化值之间的熵(KL散度)

选择一个百分位数会导致我们之前看到的类似裁剪行为。
激活在LLM中持续更新的输入通常被称为“激活”。

这些值被称为激活,因为它们通常会通过某些激活函数,如sigmoid或relu。与权重不同,激活会随着在推理过程中输入模型的每个数据而变化,这使得准确量化它们变得具有挑战性。由于这些值在每个隐藏层之后更新,所以只有在输入数据通过模型时才能知道它们在推理过程中的状态。

有两种方法用于校准权重和激活的量化方法:
训练后量化(PTQ)——在训练之后进行量化
量化感知训练(QAT)——在训练/微调期间进行量化
训练后量化最有名的量化技术之一是训练后量化(PTQ)。它涉及在训练模型之后对模型的参数(包括权重和激活)进行量化。
权重的量化使用对称量化或非对称量化来执行。但是,激活的量化需要推断模型以获取它们的潜在分布,因为我们不知道它们的范围。
所以这里又引出了激活的量化的两种形式:
动态量化数据通过隐藏层后,其激活值被收集:

然后使用这些激活值的分布来计算量化输出所需的零点(z)和比例因子(s)值:

每次数据通过新层时都会重复此过程。每一层都有其自己的z 和 s 值,因此具有不同的量化方案。
静态量化与动态量化不同,静态量化不是在推理过程中,而是在之前计算零点(z)和比例因子(s)。
为了找到这些值,需要使用一个校准数据集,将其提供给模型以收集这些潜在的分布。

在收集了这些值之后,就可以计算推理过程中执行量化所需的s 和 z 值。
在进行实际推理时,s 和 z 值不会重新计算,而是全局使用,量化所有激活。
通常,动态量化由于仅尝试计算每个隐藏层的s 和 z 值,因此可能更准确。但是这会大大增加计算时间,因为需要计算这些值。
静态量化的准确性虽然较低,但由于已经知道用于量化的s 和 z 值,因此速度更快,所以一般都会使用静态量化。
4位量化将量化位数降低到低于8位已被证明是一项艰巨的任务,因为每减少一位,量化误差都会增加。但是有几种灵巧的方法可以将位数减少到6位、4位,甚至2位(尽管通常不建议使用这些方法将位数降低到低于4位)。
这里将介绍在HuggingFace上常见的两种方法:
GPTQGPTQ 是目前最著名的4位量化方法之一。
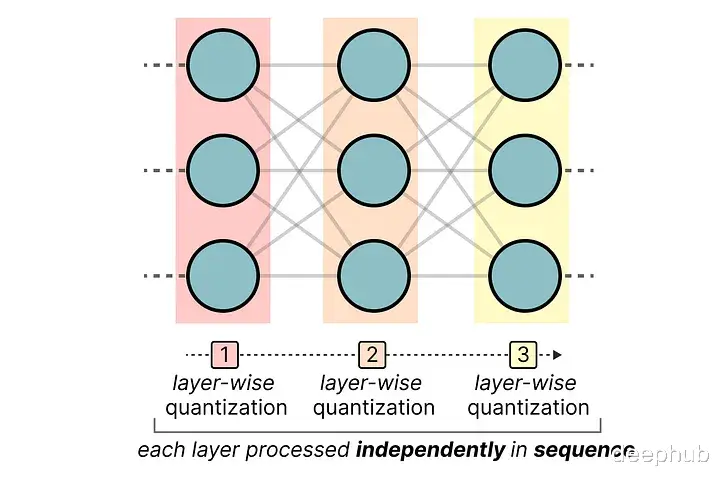
它使用非对称量化,并且逐层进行,每层独立处理完毕后再继续到下一层:
在这个逐层量化过程中,它首先将层的权重转换为逆-赫塞矩阵(Hessian)。赫塞矩阵是模型损失函数的二阶导数,它告诉我们模型输出对每个权重变化的敏感度。它本质上展示了每个权重在层中的(逆)重要性。
与赫塞矩阵中较小值相关联的权重更为关键,因为这些权重的小变化可能会导致模型性能的显著变化。

在逆-赫塞矩阵中,较低的值表示更“重要”的权重。我们对权重矩阵中的第一行的权重进行量化然后反量化:

这个过程允许我们计算量化误差(q),我们可以使用之前计算的逆赫塞(h_1)来加权这个量化误差。
本质上是根据权重的重要性创建了一个加权量化误差:
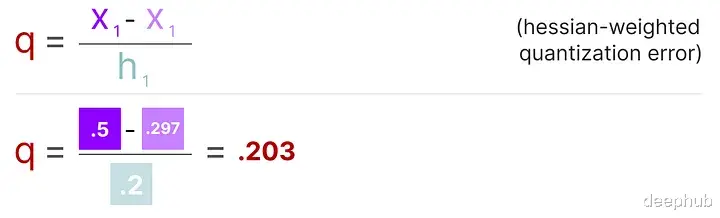
接下来需要将这个加权量化误差重新分配到行中的其他权重上。这有助于维持网络的整体功能和输出。
例如,如果我们对第二个权重,即 .3(x_2)这样做,我们会将量化误差(q)乘以第二个权重的逆赫塞(h_2)

我们也可以对给定行中的第三个权重进行相同的处理:

我们重复这个过程,将加权量化误差重新分配,直到所有值都被量化。
这个方法之所以行之有效,是因为权重通常是相互关联的。所以当一个权重发生量化误差时,相关的权重会相应地更新(通过逆赫塞)。
GGUF虽然GPTQ是一个在GPU上运行完整LLM的出色量化方法,但我们可能没有那么强大的GPU。所以可以使用GGUF将LLM的任何层卸载到CPU上。这可以在VRAM不足的情况下同时使用CPU和GPU。
GGUF的量化方法经常更新,可能取决于位量化的级别。我们这里总结一般的原则。
首先,给定层的权重被分割成包含一组“子”块的“超级”块。从这些块中,我们提取比例因子(s)和alpha(α):

为了量化给定的“子”块,可以使用之前使用过的absmax量化。记住它将给定的权重乘以比例因子(s):

比例因子是使用“子”块的信息计算的,但使用“超级”块的信息量化,后者拥有自己的比例因子:

这种块量化使用“超级”块的比例因子(s_super)来量化“子”块的比例因子(s_sub)。每个比例因子的量化级别可能不同,“超级”块通常具有比“子”块的比例因子更高的精度。
我们介绍几个常用的量化级别(2位、4位和6位):

根据量化类型,可能需要一个额外的最小值(m)来调整零点。这些与比例因子(s)一样被量化。
量化感知训练上面我们已经介绍了如何在训练之后量化一个模型。这种方法的一个缺点是,量化并不考虑实际的训练过程。
而量化感知训练(QAT)与训练后量化(PTQ)在模型训练完成之后进行量化不同,QAT旨在在训练期间学习量化过程。

QAT通常比PTQ更精确,因为量化过程已在训练中被考虑。其工作原理如下:
在训练过程中,引入所谓的“假”量化。这是一个首先将权重量化为例如INT4,然后再反量化回FP32的过程:

这个过程允许模型在训练、损失计算和权重更新过程中考虑量化过程。QAT试图探索损失中的“宽”极小值以最小化量化误差,因为“窄”极小值往往会导致较大的量化误差。

例如,假设我们在反向传播过程中没有考虑量化。根据梯度下降选择损失最小的权重。如果它处于“窄”极小值,那将引入更大的量化误差。
如果我们考虑量化,将在一个“宽”极小值中选择一个不同的更新权重,其量化误差将大大降低。

所以尽管PTQ在高精度(例如FP32)中有更低的损失,但QAT在低精度(例如INT4)中会获得更低的损失
1位大型语言模型的时代:BitNet正如我们之前看到的,量化到4位已经相当小了,但如果我们进一步减少呢?
这就是BitNet的用武之地,它使用-1或1来表示模型权重的单一位。它通过将量化过程直接注入到Transformer 架构中实现这一点。
Transformer 架构是大多数LLM的基础,它由涉及线性层的计算组成:

这些线性层通常用更高的精度表示,如FP16,并且是大多数权重所在的地方。
而BitNet用它们称为BitLinear的东西替换了这些线性层:

BitLinear层的工作方式与普通线性层相同,根据权重乘以激活来计算输出。但是BitLinear层使用1位来表示模型的权重,并使用INT8来表示激活:

BitLinear层,如量化感知训练(QAT),在训练期间执行一种“假”量化形式,以分析权重和激活量化的效果:

这种方法显著减少了模型的存储和计算需求,使得在资源受限的环境中部署大型语言模型变得可行。同时,通过这种极端的量化方法,BitNet在维持性能的同时大幅降低了能耗和运行成本
在论文中,他们使用γ而不是α,但由于我们在这个示例中使用了a,所以我继续使用这个名词。另外,请β与我们在零点量化中使用的不同,是平均绝对值。
下面我们看看他是如何工作的
权重量化在训练过程中,权重存储在INT8中,然后使用一种称为符号函数的基本策略,将其量化为1位。
它将权重的分布移动到以0为中心,然后将0左边的所有值赋值为-1,右边的所有值赋值为1:

此外,它还跟踪一个值 β(平均绝对值),因为稍后将用它进行去量化。
激活量化为了量化激活值,BitLinear使用absmax量化将激活值从FP16转换为INT8,因为在矩阵乘法(×)中它们需要更高的精度。

此外,它还跟踪了 α(绝对值),因为稍后将用它进行去量化。
去量化上面跟踪了 α(激活值的最大绝对值) 和 β(权重的平均绝对值),这些值将帮助我们将激活值反量化回FP16。
输出激活值使用 {α, γ} 重新缩放,以将其反量化到原始精度:

这个过程相对简单,并允许模型仅用两个值表示,要么是 -1,要么是 1。使用这种方法,作者观察到随着模型大小的增长,1位和FP16训练之间的性能差距变得越来越小。
并且作者发现,这仅适用于较大的模型(>30B 参数),而在较小的模型中,差距仍然相当大。
所有大型语言模型都可以变为1.58位BitNet 1.58b 被引入以改进之前提到的扩展问题。在这种新方法中,每个权重不再只是 -1 或 1,而是还可以取 0 作为值,使其变成 三元。仅添加 0 极大地改进了BitNet,并且允许更快的计算。
0的力量那么,为什么添加0是如此重要的改进呢?
这与矩阵乘法有关!
首先,让我们回顾一般的矩阵乘法是如何工作的。在计算输出时,将一个权重矩阵乘以一个输入向量。下面可视化了第一层权重矩阵的第一次乘法:

这种乘法涉及两个动作,即乘输入和单个权重,然后将它们加在一起。
BitNet 1.58b 通过使用三元权重基本上可以避免乘法操作,因为三元权重本质上告诉你以下信息:
1 — 我想添加这个值
0 — 我不需要这个值
-1 — 我想减去这个值
所以如果权重量化到1.58位,只需要进行加法操作:

这不仅可以显著加速计算,还允许进行特征过滤。
通过将给定的权重设置为0,就可以忽略它,而不是像1位表示那样要么添加要么减去权重。
量化为了进行权重量化,BitNet 1.58b 使用了 absmean 量化,这是我们之前看到的 absmax 量化的一个变种。
它简单地压缩权重的分布,并使用绝对平均值(α)来量化值。然后这些值被四舍五入为 -1、0 或 1:

与BitNet相比,激活量化基本相同,但是激活不再缩放到范围 [0, 2ᵇ⁻¹],而是使用 absmax 量化 缩放到 [-2ᵇ⁻¹, 2ᵇ⁻¹]。
所以1.58位量化主要需要两个技巧:
添加 0 创建三元表示 [-1, 0, 1]
absmean 量化 用于权重
这样就得到了轻量级模型,因为它们只需要1.58位的计算效率!
总结本文深入探讨了量化技术在大型语言模型(LLMs)中的应用,特别介绍了几种量化方法,包括训练后量化(PTQ)、量化感知训练(QAT)、GPTQ、GGUF和BitNet。量化技术通过减少模型的参数精度来降低存储和计算需求,从而使模型能在资源受限的环境中高效运行。
PTQ和QAT分别在训练后和训练过程中实施量化,以优化模型性能和减小量化误差。GPTQ和GGUF则是针对特定硬件环境优化的量化策略,如使用GPU或CPU。特别值得一提的是BitNet和其进阶版本BitNet 1.58b,它们通过将模型权重量化到极低的位数(如1位和1.58位),显著提升了计算效率并降低了模型体积。
希望这篇文章能让你更好地理解量化、GPTQ、GGUF和BitNet的潜力。谁知道将来模型会变得多小呢?
https://avoid.overfit.cn/post/11536319ad704103b39ec8da734eeb3c
作者:Maarten Grootendorst
