pandas 中有一个让人捉摸不透的警告:

有人说,你用了"链式赋值操作",你应该:

事实上,这样子也会出来警告:
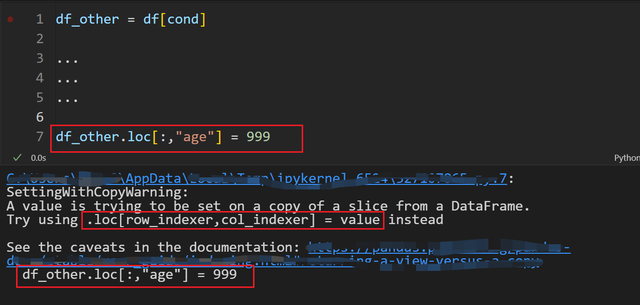
警告信息真的让人无语。有一些无脑的教程会说,你得用 copy:

无缘无故为啥要复制一整份数据。难道每次赋值都要 copy ?
我在 pandas 专栏中也详细讲解了其中的原理,主要是驳斥了网络上一些无脑说法。今天我们换一个角度,尝试成为 pandas 作者,看看当时作者到底遇到了什么样的难题,使得他做出这样子设计。
从零开始假设我们是 pandas 的作者,现在要设计数据表(DataFrame)的定义:
 名字叫 MyFrame初始化的时候需要传入字典数据
名字叫 MyFrame初始化的时候需要传入字典数据看看怎么使用
 实例化的时候,传入字典
实例化的时候,传入字典筛选是数据表常规操作,添加一个 where 的函数:
 功能实现不是本文重点,这里借用 pandas 实现行15:重点是,我们要返回一个全新的 MyFrame 对象。 因为我们不希望后续操作会影响原来的数据
功能实现不是本文重点,这里借用 pandas 实现行15:重点是,我们要返回一个全新的 MyFrame 对象。 因为我们不希望后续操作会影响原来的数据现在可以条件筛选:

现在的问题是,筛选总是用 where 显得太啰嗦。在 python 中对集合的物件取出元素,是有专门的语法 [...] 。
 行2:语法 对象[切片范围]
行2:语法 对象[切片范围]这不也是一种数据筛选的方式吗?我们自定义的类也能有这样子的语法支持吗?
魔法方法从对象的角度来说,它只不过是数据与函数的结合体。显然语法中的 [] 应该是一个函数。但 python 中是不可能如下定义函数名字的:
 行17:这违反了 python 定义函数名字的规则
行17:这违反了 python 定义函数名字的规则python 的作者就想,既然特殊符号不行,那就用比较不常用又合法的函数名字代替吧。所以,集合的物件取出元素的函数名字如下:
 行18: __getitem__(self,...) ,就表示当使用 语法 对象[0:-2] 会调用的函数行25:可以看到,最终仍然是调用之前定义的 where 函数(没必要重新实现一次)。
行18: __getitem__(self,...) ,就表示当使用 语法 对象[0:-2] 会调用的函数行25:可以看到,最终仍然是调用之前定义的 where 函数(没必要重新实现一次)。现在我们的数据表可以这样子使用:

语义感满满。
同样的套路,我们可以实现赋值操作。首先实现一个 update 函数
 行39:注意,更新操作不需要返回新的对象,而是修改对象中的 data
行39:注意,更新操作不需要返回新的对象,而是修改对象中的 data重点来了, 索引赋值操作 同样有魔法方法:
 行41:魔法方法名字: __setitem__(self, keys, new_value)行50:直接调用 update 函数即可
行41:魔法方法名字: __setitem__(self, keys, new_value)行50:直接调用 update 函数即可看看使用方式就很容易理解这个魔法方法:
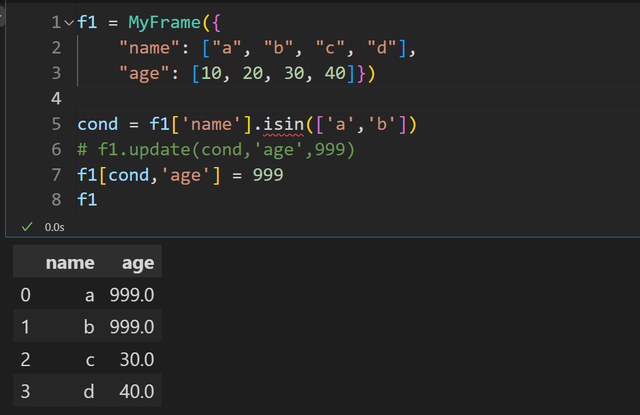 行6:使用 update行7:使用索引赋值
行6:使用 update行7:使用索引赋值以下是魔法方法调用示意图:

可以想象,当年 pandas 作者做到这一步也是信心满满,这语义牛逼了!但不出意外的话,很快就会出意外!
陷阱许多初学者以为,索引赋值操作会执行2个步骤( 错误理解 ):
执行等号左边的筛选操作。调用了魔法方法 __getitem__ ,得到了一个新的数据表执行赋值操作现在我们自己实现了一遍就清楚知道,实际上代码只调用了 __setitem__ 函数, 没有调用 __getitem__ ,因此不会产生任何新的对象。
再看下面的代码:
 行7:看起来也是更新操作。但结果根本没有被更新
行7:看起来也是更新操作。但结果根本没有被更新这里就会执行2个步骤:
执行等号左边第一个 f1[cond] ,也就是执行了一次 __getitem__ ,返回了一个全新的对象全新的对象执行赋值操作 ,执行了一次 __setitem__ ,完成赋值操作。注意,这一步执行的操作,不是作用在 f1 对象上如果代码换一种写法,就很容易理解:
 行5:f2 就是之前说的"新对象"行7:更新的是 f2 ,f2 也确实被更新。但我们却期望 f1 被更新
行5:f2 就是之前说的"新对象"行7:更新的是 f2 ,f2 也确实被更新。但我们却期望 f1 被更新此时,pandas 的作者有点绝望了。因为这是 python 的机制,他无法改变。唯一能做的,就是做一个警告,用于提醒用户。
此时他灵机一动,想到了一个简单可行的机制。
警告机制问题核心就在于:

既然是 __getitem__ 的祸,那就从这里做手脚吧。
首先,在对象初始化的时候,给一个标志属性:
 行11:标记一个对象是否为影子对象,就类似之前例子中的 f2
行11:标记一个对象是否为影子对象,就类似之前例子中的 f2在 __getitem__ 中,返回全新对象之前,修改新对象的 _shadow 属性:
 行36:打标记
行36:打标记接下来就很简单,在 __setitem__ 里面,按需出警告:
 行65-66:判断,出警告
行65-66:判断,出警告实际使用:

这种警告机制的问题在于,大部分情况下,我们会无意识产生 "影子对象" 。比如最常见的一种情况:
 行7:做了一次筛选行10:调用函数注意结果,是正确的,但仍然出现警告。 这就是为什么在我的 pandas 专栏中明确告诉大家,只要你明确知道需要修改的数据表对象,那就可以不用管这警告
行7:做了一次筛选行10:调用函数注意结果,是正确的,但仍然出现警告。 这就是为什么在我的 pandas 专栏中明确告诉大家,只要你明确知道需要修改的数据表对象,那就可以不用管这警告你觉得这种设计思路是不是挺巧妙,同时又让人有点无语?
不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。
转发、关注、评论,获得本期源码和数据。
