
文|面包夹知识
编辑|面包夹知识
«——【·前言·】——»
高效识别鸭舍中的死鸭,已成为肉鸭自动化养殖模式中,亟待解决的重要问题之一。

养殖场鸭苗的日均死亡率通常在0.05%~0.1%,例如,在河北某一个存栏量为1×105只的肉鸭厂,平均每日需拣出50~100只死鸭。
由于肉鸭的高密集养殖,死鸭的识别仍然依赖人工操作,这导致效率低下、劳动强度大和养殖成本高昂。

一方面管理人员的行为会导致肉鸭应激,死亡率提高,降低生产效率;另一方面鸭舍内死鸭对空气的污染可能会对工作人员身体造成伤害。
因此,开展笼内死鸭识别模型算法的研究对于家禽养殖业至关重要,为了采集数据需要研发一款适用于肉鸭舍的自主巡检装备。

目前机器视觉在畜禽养殖中应用广泛,显著改善了劳动力短缺的情况,不仅可以代替人类从事危害健康的工作,还能够降低生产成本和节约能源。
例如,南京某大学设计的死鸡自动识别系统,采用热红外采集技术,基于卷积神经网络模型识别鸡场存在的死鸡,但该方法主要用于平养肉鸡,对于笼养目标识别准确率不高。

河北某研究基地,基于MaskR-CNN和LiteFlowNet网络构建了一种,多目标背景下基于视频关键帧的死兔识别模型,但该方法检测速度有待优化
再加上,北京某大学设计的基于机器人技术、红外热成像技术及图像处理等技术设计一种基于温度判断的死鸡识别算法,但总体识别率只有80%。

以YOLOv5s目标检测算法为基础,通过加入SE注意力模块,构成改进后的YOLOv5s-SE模型的检测准确率达到了97.7%,但缺乏适配的图像采集工具。
此外,还有一些修复图像遮挡的创新技术,基于深度卷积神经网络(CNN)引入了3个跳跃连接反卷积和卷积运算,对单幅图像去除雨痕遮挡的效果达到了80%以上。

然而,尽管这些技术在其他养殖领域得到了应用,但关于肉鸭识别模型的研究报道较少。
在立体层叠式笼养肉鸭环境下,使用自主巡航机器人自动追踪群养肉鸭,采集肉鸭图像,采用深度学习的方法实现图像的处理,并在此基础上分析死鸭识别模型的准确率。

«——【·材料与算法·】——»
实验于2023年7月至8月期间,在南京市六合区的某个肉鸭养殖场进行,共持续42d。
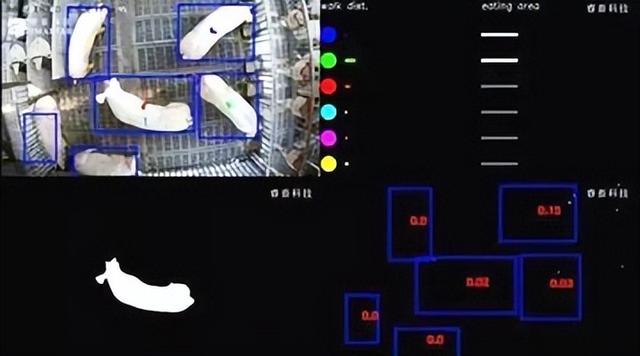
鸭舍采用立体层叠式笼养模式,共有3层笼具,中间过道宽度为0.8m,每个单笼的尺寸为160cm×70cm×40cm,养殖密度为15只/m2,并且配备自动化水线以减少人工对动物的干扰,如图1所示。

自主巡检机器人的主要任务是根据需求在鸭舍内按照规定路线行走,采集所需位置的图像。
自主巡检机器人建模图,和实物如图2所示,总体尺寸为64cm×48cm×210cm。

机器人采用履带式结构以适应鸭舍的环境,并降低巡检时的噪声。两电机差速底盘被用作驱动结构,以确保机器人可以在鸭舍内的任何地点自由转向。
机器人采用磁条导航来保证巡检平台始终沿着铺设的磁条运行,自主巡检机器人依照事先铺设的磁条轨道进行系统巡检。

当机器人行驶于磁条轨道时,一旦磁条传感器探测到磁条宽度发生变化并且达到指定宽度时,上位机将发出指令,车轮停止旋转,并同时向工业相机发出图像采集指令。
相机完成图像采集任务后,将反馈结果,若发现鸭笼内有死亡禽类,系统将通过通信模块将此信息传送至终端,随后继续巡检下一个鸭笼。
若未检测到异常情况,则机器人将持续执行巡线任务。摄像头采用USB输出的IMX588相机模组,相机固定在机器人侧方,距离笼底面0.8m,倾斜45°俯拍,位置如图3所示。
在图像采集过程中,确保肉鸭始终在拍摄范围内,并尽量减小镜头畸变的影响。相机通过USB线连接到巡检机器人内部的一台计算机上。

采用Python算法实现图像的自动抓取,6个摄像头依次采集6f/min,间隔10s,农业机械学报最终,获得1075幅死鸭图像以及大量正常肉鸭图像,用于构建死鸭目标识别模型数据集。
卷积神经网络是一种深度学习模型,广泛应用于处理图像和视觉数据的计算机视觉任务中。

MaskR-CNN是一种广泛应用于目标检测和实例分割的深度学习模型,它扩展了FasterR-CNN框架,通过添加额外的分割分支来生成目标实例的精确掩码。
MaskR-CNN的核心思想是将目标检测和实例分割任务结合在一起,使模型能够检测目标的位置并为每个目标实例生成像素级别的掩码,从而提供更详细的目标分割。

在死鸭识别和检测任务中,CNN通过卷积和池化操作自动学习和提取图像中的特征,如边缘、纹理、形状等,从而准确地识别死鸭。
MaskR-CNN网络是一种基于深度学习的实例分割算法,不仅可以实现对图像的目标检测、目标分类和语义分类,还能对每个单独目标的。

像素进行分类。它是一种典型的两阶段网络算法,包括了区域提取和边界框回归及分类两个阶段。
其结构包括主干网络、区域提取网络、RoIAlign(RegionofInterestAlign)和功能型网络,如图4所示。

其中,采用ResNet-101深度残差网络和特征金字塔FPN(Featurepyramidnetwork)的组合作为特征提取网络。
ResNet-101具有较深的网络结构,通过残差连接能够有效地提取图像中的高级语义特征。

而FPN通过构建多层特征金字塔,将不同尺度和语义层次的特征进行融合,从而更好地捕捉目标肉鸭的细节和上下文信息。
区域候选网络负责生成候选目标区域(RoIs),通过利用锚框和候选框回归来定位可能包含肉鸭的图像区域。

RoI分类网络根据RoIs中的特征进行分类,为每个RoI预测其所属的类别;掩膜生成网络在RoIs的基础上生成目标的像素级掩膜,实现精确分割。
不过与传统ViT中的多头自注意(MSA)相比,MSA缺乏跨窗口的连接,SwinTransformer中的W-MSA作为一个单元控制窗口中的计算区域。

减少了网络计算的数量,降低了图像的复杂度,如图5所示。SW-MSA的位置与W-MSA层相连,因此,SW-MSA需要在之后提供不同的窗口分割方法(W-MSA)实现跨窗口通信。

通过W-MSA对输入图像的窗口分割结果如图所示,图像的每个周期向上和向左移动一半窗口的大小,然后将图5中的蓝色和红色区域移至图像的下方和右侧,如图5所示。
W-MSA虽然降低了计算复杂度,但是不重合的窗口之间缺乏信息交流,在2个连续的SwinTransformerBlock中交替使用W-MSA和SW-MSA解决了不同窗口的信息交流问题。

移动窗口的划分方式使上一层相邻的不重合窗口之间引入连接,大大增加了感受野,极大提高了SwinTransformer的计算效率,使2个窗口有了交互,从而达到了全局建模的能力。
SwinTransformer模型的特征提取过程分为4个阶段,采用了分层自注意力机制,信息可以在不同的层次之间流动,有助于模型从局部到全局捕获不同尺度的深层次特征。
具体网络结构如图6:

SwinTransformer模型的特征提取过程分为4个阶段,采用了分层自注意力机制,信息可以在不同的层次之间流动,有助于模型从局部到全局捕获不同尺度的深层次特征。
网络结构如图6所示,具体网络结构如图6,修改输入分辨率、通道数等确保新的骨干网络的输入和输出与MaskR-CNN的其他部分兼容。

SwinTransformer需要一批图像作为输入,修改MaskR-CNN的数据加载和处理代码以满足SwinTransformer的输入要求。
根据SwinTransformer的特征输出,调整FPN层级,以确保与SwinTransformer输出兼容。基于SwinTransformer改进的MaskR-CNN网络结构如图7所示。

为了提高后续死鸭检测的可靠性,基于OpenCV对采集到的图像进行图像增强处理。
处理过程包括增加亮度、增强对比度以及增加饱和度的批处理操作,具体结果如图8所示。

由于侧方俯拍的方式,部分肉鸭会被笼网遮挡,为了提高死鸭识别的准确率对遮挡图像的笼网进行修复。
该算法使用计算机视觉和图像处理技术,能够自动化地进行图像修复,以获得清晰且完整的肉鸭图像。
«——【·采用Labelme工具标注肉鸭·】——»

图像中的笼网部分并保存为JSON格式文件,利用OpenCV和Python构建图像处理函数,处理使用MaskR-CNN网络模型训练得到的遮挡笼网部分的掩膜部分。
将训练得到的遮挡笼网部分HSV颜色空间下界和HSV颜色空间上界作为输入参数。

函数读取训练得到的遮挡笼网图像,并将其转换为HSV颜色空间,辅助实现更准确地选择和处理目标颜色范围,提高遮挡笼网部分修复的准确性。
在图像处理过程中,算法首先获取图像的尺寸,然后通过顺时针由外到内逐层遍历图像中的每个像素点,遍历过程中,算法通过步骤对每个像素点进行处理。
在处理完该像素点后,顺时针对下一个像素点进行上述处理,完成对图像中所有像素点的遍历后,修复后的图像将去除遮挡笼网部分。
其中,采用不同颜色的笼网掩模修复效果不同,修复结果对比如图9所示。

通过修复结果图对比可以看出,绿色掩膜修复效果最佳。将该算法应用于肉鸭图像的处理,可以有效地去除遮挡笼网部分,为后续死鸭目标识别提供清晰可靠的图像基础。
使用肉鸭自主巡检机器人作为图像采集工具,采集肉鸭图像数据。图像首先经过裁剪和增强处理,得到图像应用图像修复算法对遮挡笼网部分进行去除。

随后使用SAM-Tool半自动标注工具快速标注死鸭目标,标签类别名称为“dead_duck”,创建包含死鸭类别信息的json文件。
最终获得构建死鸭目标识别模型数据集的图像共1075幅,其中915幅为训练集,160幅为验证集。

为了优化每个模型的性能以及有效完成死鸭目标识别任务,分别设置每个模型的学习率、批量大小、迭代次数和优化器选择等训练参数,如表1所示。
每个模型共训练120轮,每迭代8个轮次保存一次模型权重,最终选择识别精度最高的模型作为结果。

«——【·死鸭识别模型实验·】——»
选择损失值和死鸭识别平均准确率(Averageprecision,AP)作为评价死鸭识别模型性能的指标,主要考察。
在目标检测和分割任务中,评估模型的性能主要考察边界框平均精度均值和分割均值平均精度两种性能指标。

bbox_mAP衡量模型在检测和定位目标方面的准确性和精度,segm_mAP衡量模型在分割目标方面的准确性和精度。
由图10可知,经过2×104次迭代后,SOLOv2和MaskR-CNN模型的损失值分别达到了0.097和0.115,MaskR-CNN+SwinTransformer和SOLO模型的损失值则分别为0.156和0.206。

根据图11a的结果,训练经过75个迭代周期后,MaskR-CNN+SwinTransformer、MaskR-CNN和QueryInst模型的bbox_mAP分别达到了90.6%、86.6%和89.2%。

根据图11b的结果,训练90个迭代周期后,MaskR-CNN+SwinTransformer和SOLOv2模型的segm_mAP值最高,达到90.1%和88.9%。
其次是MaskR-CNN和QueryInst模型分别为86.8%和86.4%,SOLO模型segm_mAP值最低为83.3%。
在死鸭目标识别任务中的性能,设计了死鸭目标识别准确率试验,分别使用死鸭目标识别误检率、漏检率和准确率作为评价指标,通过实验选择适合鸭舍环境的mAP。

由表2可知,SOLO和QueryInst网络模型随着mAP的提高,死鸭的漏检率提升,SOLO模型在置信度阈值为90%时,死鸭识别准确率仅为83.3%,QueryInst模型为91.7%。
如果将mAP设置的过低,模型可能会更容易检测出死鸭,但这可能会导致误检率上升,以SOLO模型为例,当mAP为30%时,误检率达到了6.7%。

为评估在死鸭图像中去掉笼网前后,对死鸭检测效果的影响。我们分别对去掉笼网前后的死鸭图像进行标注,制作了数据集,用于训练Mask算法。
因为这样就得到了2个权重文件,并在验证集上进行了检测。我们将mAP调整为90%,选择死鸭目标识别误检率、漏检率和准确率作为评价指标。

根据表3可以看出,使用去掉笼网后的图像作为训练集对死鸭模型检测效果有正面的提升。
在使用去掉笼网后的图像训练的模型进行验证时,相较于模型在训练集和验证集都未去除笼网的情况下,提升效果显著,达到了6.4个百分点。
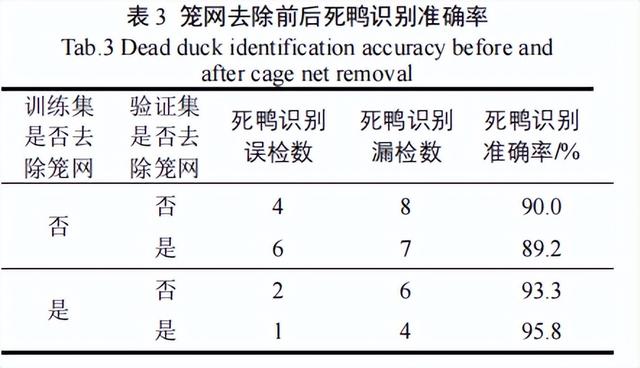
当训练集使用未去除笼网的图像,而验证集使用去除笼网的图像时,死鸭检测效果却出现了下降,死鸭识别误检数增加。这种情况可能是由于光线不足,死鸭与笼网之间的过拟合导致的。
由表4可知,MaskR-CNN模型和SOLOv2模型在在识别0~7日龄和8~15日龄死鸭时均出现漏检或错检的情况。

MaskR-CNN模型出现将健康肉鸭的脚错检成死鸭的问题,SOLOv2模型出现预测框(bbox)检测错误的问题。
MaskR-CNN+SwinTransformer模型对0~7日龄和8~15日龄的死鸭识别准确率均为100%,无漏检与错检现象。

因此应用MaskR-CNN+SwinTransformer模型在自主巡检装备上检测效果最优。
«——【·讨论·】——»
SOLOv2、MaskSwinTransformer和MaskR-CNN模型,在死鸭识别任务中表现较好,死鸭识别准确率分别为95.0%、95.8%和97.5%。

但随后将其部署在死鸭自主巡检装备上,MaskR-CNN模型出现将健康肉鸭的脚错检成死鸭的问题。
MaskR-CNN+SwinTransformer模型能够实现对0~7日龄和8~15日龄的死鸭准确识别,无漏检与错检现象。

出现这种现象的原因可能是机器学习中的过拟合现象导致的,过拟合发生时,模型在训练数据中学到了数据中的噪声和随机变化。
而不能很好地泛化到新的、未见过的数据,这导致模型对于训练数据表现出高度适应性,但对于测试数据的泛化性能较差。

因此MaskR-CNN+SwinTransformer模型在实际应用中效果最优,且自注意力机制包含全局特征,增加了整合全局信息的能力。
一方面降低遮挡导致的目标漏检误检概率,另一方面优化复杂环境下目标丢失的漏检问题。

«——【·结语·】——»
构建一种高度适应性的死鸭识别模型,通过基于深度学习的遮挡笼网去除,基于OpenCV的图像增强处理以及SwinTransformer与MaskR-CNN算法模型的融合应用。
以及基于SwinTransformer的增加自注意力机制和移动窗口的划分方式,改进MaskR-CNN模型。

并开展了死鸭识别评估试验,得出MaskR-CNN+SwinTransformer模型在实际应用中效果最优的结论,为养殖场优化养殖工艺提供了技术和理论支撑。
