「我们终于拥有了“地表最聪明AI”——至少埃隆·马斯克是这么评价Grok3的。马斯克的人工智能初创公司xAI于周二宣布了其人工智能聊天机器人Grok3的更新,并声称在关键计算领域的测试表明,Grok3测试版在多个重要领域已超过了竞争对手。」
在发布Grok3的视频中,马斯克提到,Grok这个名字来源于科幻作家罗伯特·海因莱因(RobertHeinlein)所创造的一个术语,背后的动力是追求知识。
“xAI和Grok的使命是理解宇宙,”马斯克表示,“我们对宇宙本质的好奇心推动着我们前行,也使我们成为一个极力追求真理的AI,哪怕有时候这种真理与政治正确相悖。”
首个Grok聊天机器人于2023年11月发布,之后xAI定期推出更新,持续优化它的大语言模型。大语言模型是一种通过海量数据集训练,能够模仿人类反应的人工智能。
在视频中,马斯克和三位xAI工程师讨论了Grok3的表现,并展示了他们称之为新AI引擎超越竞争对手的图表和数据图。竞争对手包括OpenAI的ChatGPT4、Google的Gemini、Anthropic的Claude,以及新晋加入前沿AI平台,由中国公司推出的DeepSeek。
事实果真如此吗?
OpenAI的高管BorisPower最近针对xAI的Grok模型发起了猛烈的指责,声称xAI在模型评测中涉嫌“数据注水”,引发业界的广泛讨论。这场争论的核心在于两家公司如何评估自家模型的性能,OpenAI指责Grok团队通过不公平的对比方式,夸大了自家模型的优势。

OpenAI与xAI的争执
事件的导火索是BorisPower在公开场合的指控,他表示Grok模型在性能评测上玩起了“障眼法”。具体来说,OpenAI质疑Grok团队采用了一种不合理的方式:他们通过多次测试挑选最高分来展示成绩,给人一种模型表现优异的假象。
简单来说,OpenAI的做法是通过一次性测试展现模型的真实水平,而Grok团队则通过64次尝试挑选最好的结果,然后用这个结果作为“亮点”展示。这种方式看似赢得了高分,却忽略了效率和成本的巨大差异。
面对指责,xAI的工程师们急忙回应,反驳作弊的说法,并声称Grok团队与OpenAI“用的方法都是相同的”。然而,OpenAI对此并不买账,认为这种比较方式并不公平。
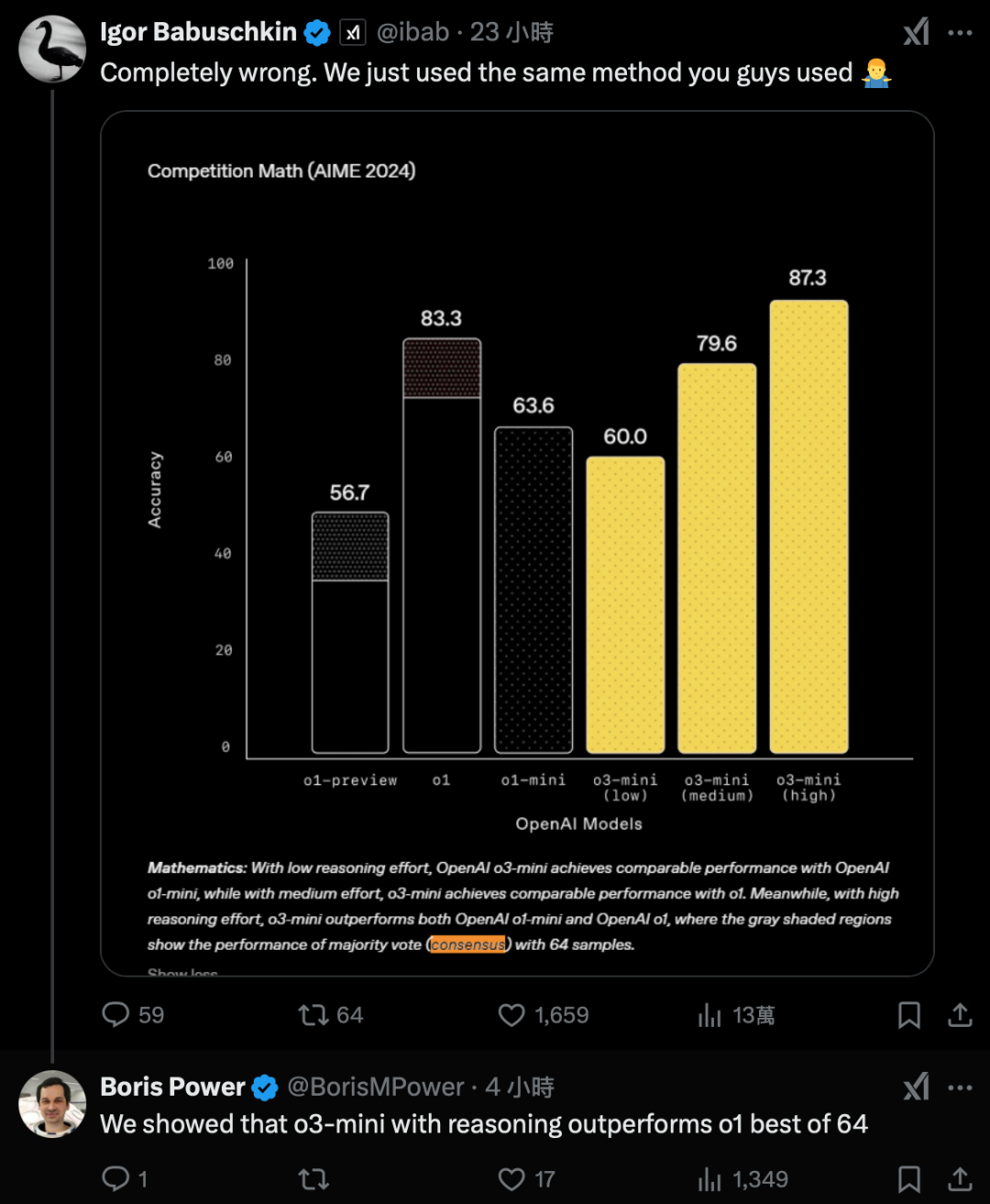
Grok的评测方法争议
这场争议的焦点在于Grok和OpenAI的评测方法差异。Grok使用的是64次尝试(cons@64),而OpenAI则选择了单次尝试(cons@1)。简单来说,Grok是通过多次尝试挑选最高分来展示模型的最好表现,而OpenAI则是以“单回合对决”的方式,挑战自家旧模型,强调新模型的真实实力。
这种差异看似微不足道,但却暴露了两种截然不同的评测理念。Grok的方式固然能够提升最终成绩,但在效率和成本上却付出了很高的代价。相反,OpenAI通过“以弱胜强”的方式展示了新模型的优越性,不仅表现出色,而且大幅节省了计算资源和成本。
OpenAI的对比方法与影响
OpenAI在这场对比中采取了更为严格的标准,采用新模型与自家旧模型进行对比。在这种情况下,新模型需要一次性“击败”旧模型的64次尝试成绩。这种方法的好处在于能够真实地反映新模型的能力,避免了通过多次尝试寻找“最优结果”来误导用户。
更重要的是,这种评测方法体现了新模型在计算效率上的优势。通过减少计算资源的消耗,新模型不仅在效果上超越了旧模型,更在实际应用中带来了巨大的成本节约。这种做法展示了AI在技术革新中的巨大潜力——通过高效、低成本的方式带来卓越表现。
另外,仅仅是“表面”上的成本对比,并不能反映AI模型在实际应用中的真正优势。OpenAI通过对比,证明了新模型在提升效率、降低成本方面的巨大潜力。对于任何一个追求高效的AI应用来说,成本和效率的优化无疑是最关键的因素。
OpenAI对Grok的质疑,揭示了当前AI评测标准和方法中的一个深层问题——如何在保证模型性能的同时,实现成本和效率的最大化。从OpenAI的角度来看,Grok团队的做法虽然在数据上看似有优势,但在实际应用中却可能导致巨大的资源浪费。
特别声明:以上内容仅代表作者本人的观点或立场,不代表新浪财经头条的观点或立场。如因作品内容、版权或其他问题需要与新浪财经头条联系的,请于上述内容发布后的30天内进行。




Leo
营销第一马斯克的常规操作罢了