DeepSeek火了之后,很多人终于理解了多模态模型、prompt 等概念,那再来看理想的「端到端 + VLM」架构应该就不难了。
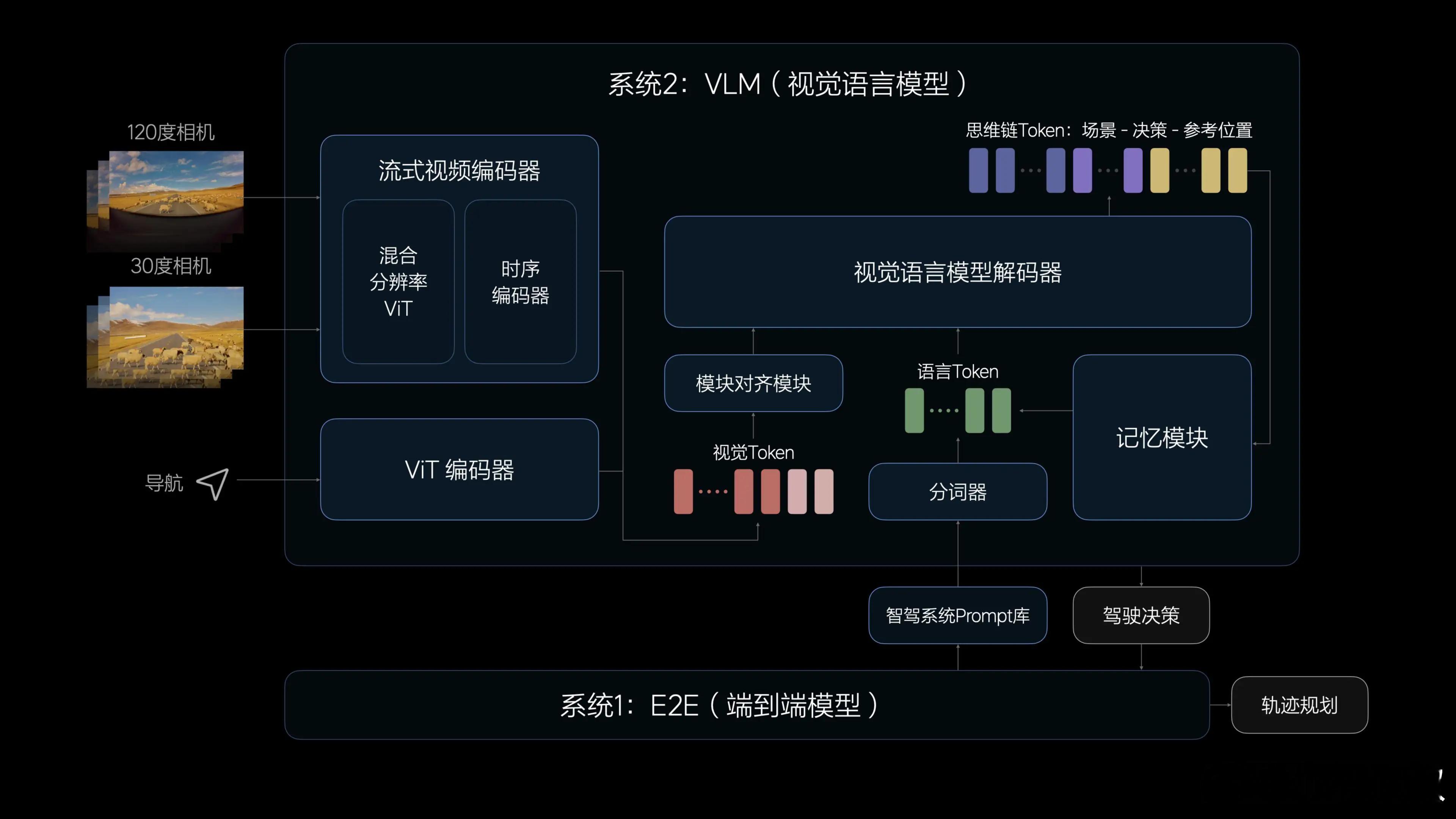
理想目前采用的是“双模型并行”架构:端到端模型和 VLM 模型各跑在一个 Orin 上,分别处理不同任务。
端到端模型参数量很小(0.3~0.5B),但运行频率很高,每秒可执行十几次推理。它的输入包括传感器数据、自车状态、导航信息,输出的是融合感知 + 规划结果,比如 OCC 动态障碍物和最终轨迹。
而 VLM 是一个参数量达 2.2B 的多模态语义模型,主要用来进行“深层理解”任务,比如识别复杂路口结构、分析交互意图等。但运行频率很低,大概 0.34Hz。端到端模型会在需要语义信息的时候调用 VLM 的输出,作为决策参考。
根据 scaling law(规模法则),模型越大、数据越多,效果越好。所以理想的训练数据也从最早的 100 万 clips,扩展到了今天的 1000 万 clips。
接下来如果芯片算力更强,还可以进一步增加模型参数或者推理频率。
理想的下一步,就是把这两个模型合体 —— 做一个完整的“图像进、动作出”的大模型 VLA。也就是说,直接用一个模型搞定“理解 + 决策”,把车变成一个能看、能懂、能开的“驾驶机器”。