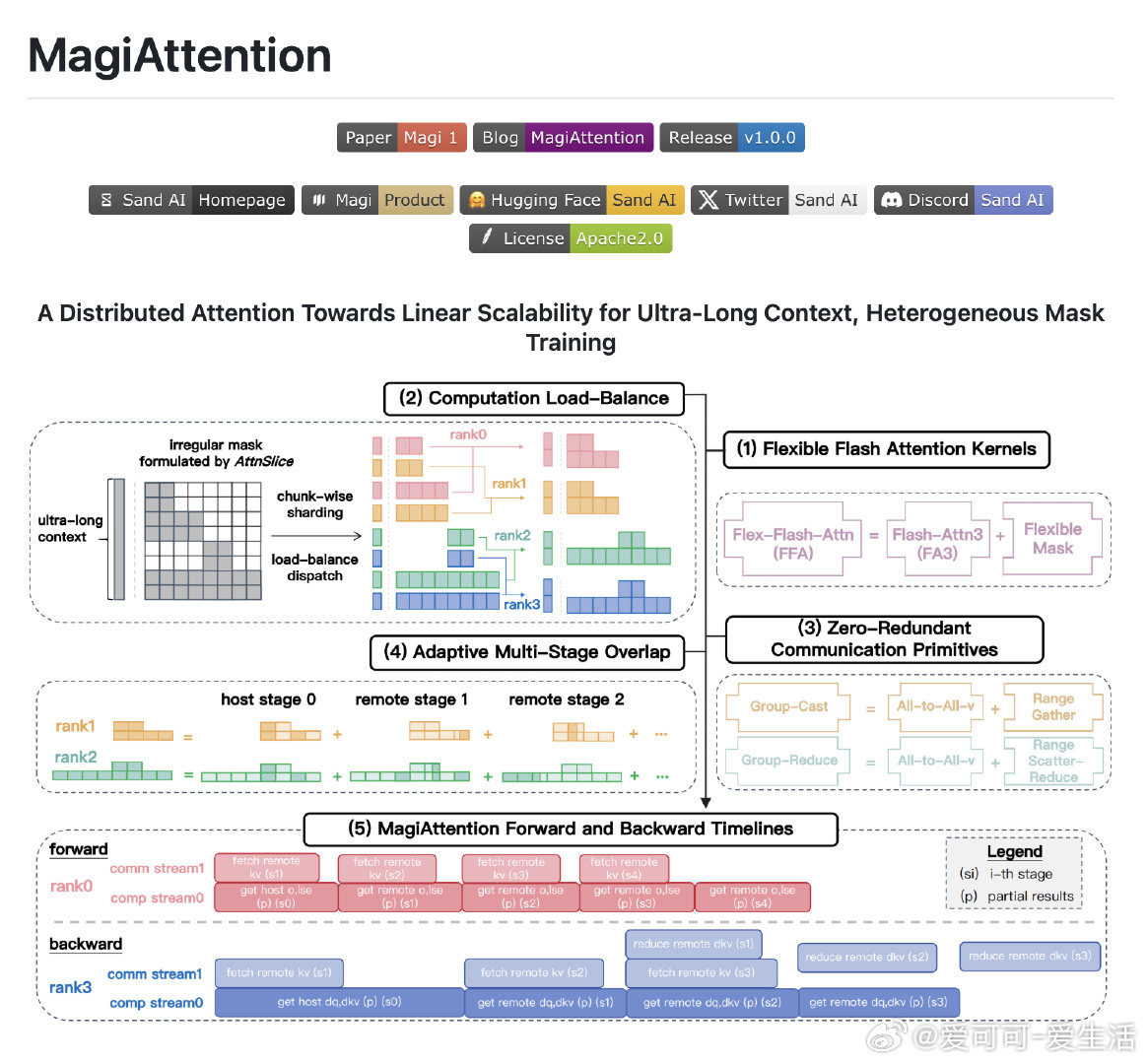
【[197星]MagiAttention:为超长文本和异构数据训练提供线性可扩展的分布式注意力机制。亮点:1. 支持多种注意力掩码类型,灵活性极高;2. 在Hopper GPU上性能与Flash-Attention 3相当;3. 实现零冗余通信,大幅提升分布式训练效率】
'A Distributed Attention Towards Linear Scalability for Ultra-Long Context, Heterogeneous Data Training'
GitHub: github.com/SandAI-org/MagiAttention
分布式注意力 超长文本训练 异构数据 AI创造营