

分享人:吴翼
编辑整理:yanjun, hanbo

AGI 正在迎来新范式,RL 是 LLM 的秘密武器。
最近几个月,我们能明显感受到头部 AI labs 在形成一些新共识:post training 的重要程度在提高,需要的计算资源可能在未来超过 pre training;RL 成为提高模型 reasoning 能力的重要范式,需要大量的探索和突破。今天我们讨论的 Agent 也是从强化学习中最早被定义的。
曾在 OpenAI 负责 post-traning 的 John Schulman 是 RL 的拥趸和布道者,他认为,post-training 是模型变得越来越聪明的重要原因,而 RLHF 是这其中最重要的技术 tricks。John Schulman 对 RLHF 的信仰来自他在 OpenAI 的亲身实践:GPT-4 的 Elo 分数之所以能比第一代 GPT 高出 100 分也和 post-traning 的提升相关。
Scaling law 让 AI 更聪明,而 RL 让 AI 更有用。我们相信,RL 会在 LLM 发展中扮演越来越重要的作用。
为了更全面地理解 RL,海外独角兽邀请到边塞科技的创始人及 CEO 吴翼来分享 RL 的基本原理和 RLHF 的最佳实践:
• PPO RLHF 是目前为止最强大的训练方法,它是真正提升 AI 能力的关键;
• RLHF 同样面临着算法、系统和数据层面的挑战;
• 在 RLHF 范式下,高质量数据的重要性进一步提升,高质量数据能显著提升智能水平;
• 长期来看,RLHF 是实现超级智能的关键,它让 AI 有希望成为真正和人类协同的 agents。


💡 目录 💡
01 强化学习及语言模型技术回顾
02 指令遵从:LLM 与 RL 的相遇
03 预训练,后训练和 RLHF
04 Why do we need RLHF?
05 PPO RLHF 的核心挑战
06 广义上的对齐
01.
强化学习及语言模型技术回顾
强化学习的核心是 exploration and exploitation
强化学习的前置内容是机器学习(Machine Learning)。上一波的 AI 浪潮主要讨论的是 ML,它是通过人标注、给定任务,通过 AI 去学习的过程,这类方式十分任务导向。比如,标注一张动物图片,判断是猫还是狗,训练一个神经网络去做判别。

但我们日常生活中并不是所有任务都是通过图片判断猫狗的任务,大部分的任务是一个有序列决策的 sequential decision making,也就是说完成一个任务需要做出很多决策。比如让机器人递一杯水的任务,或者玩打砖块游戏的任务。

递水、把游戏中的砖块打掉这种复杂的目标需要做很多的动作和决策。在图片分类任务里,有判断一张图片中是猫还是狗的简单能力就足够了。但是换到机器人递水这件事情上,判断机器人是左手递水还是右手递水、打砖块游戏到底是从左还是从右打能够打碎砖块其实是没关系的,只要能够完成任务就可以了,并没有标准答案。
我们希望通过一个算法的方式让 AI 能够自行找到满足条件的答案,这就是强化学习需要解决的问题。
抽象来讲,强化学习需要一些关键因素:
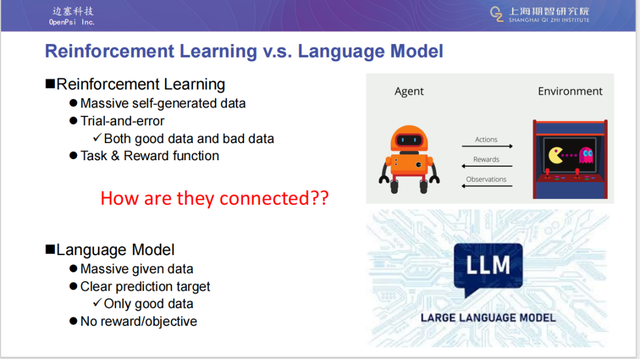
环境(environment):环境即为任务。比如, AI 想去玩吃豆人游戏,那环境首先会有 observation(观测),AI 会看到环境里面存在的物体。此外,环境会有 transition(变化)。AI 会从环境中收到 reward(奖励)。
Agent / Policy:AI 也叫做 policy,或者 agent。Agent 也是从强化学习中最早被定义的。作为 agent / policy,会对环境输入观测,进行感知,最后输出一个动作,目标是得到更多的奖励。
比如,吃豆人 AI 就希望吃到更多的豆子,或者在打砖块游戏中,AI 希望得到尽量多的砖块,AI 做咖啡的目标是希望能够把咖啡做出来。这里有几个核心要素:
环境:AI 需要一个任务,比如打游戏、或者做咖啡。
需要有动作、有观测、有奖励。

经典 RL 算法
强化学习算法是希望用一种方法找到可以有高奖励策略的方式。目前有很多经典算法。
比如 2014 年强化学习第一次出圈的 DQN 算法,它是由 Deepmind 提出的。DQN 算法成功打通关了雅达利游戏。
💡
DQN 算法:Deep Q-Network 是一种结合深度学习和强化学习的算法,被用于解决复杂的顺序决策问题。DQN 推出后在多个领域取得了突破性成果,尤其是在游戏 AI 中展现出超人类水平的性能。尽管需要大量计算资源,但 DQN 为解决复杂的强化学习任务提供了强大而灵活的方法。

第二个出圈的算法则是 2016-2017 年 Deepmind 提出的 AlphaGo,以及它的通用版算法 AlphaZero。AlphaGo 在当时在围棋项目上击败了世界冠军。

之后出现的,便是现在最广泛使用的强化学习的算法 PPO 算法。PPO 算法是 2017 年由 OpenAI 提出的,OpenAI 使用这个算法去打了 Dota 游戏,并在 Hide and Seek Game 这一项目中也使用了 PPO 算法。从 2017 年开始,PPO 算法一直是 OpenAI 内部在使用的强化学习的算法。
💡
PPO 算法:即 Proximal Policy Optimization,PPO 算法提出后应用场景相当广泛,包含各种序列规划问题、机械臂控制、电子游戏以及今天的 ChatGPT。OpenAI 基于 PPO 算法设计的 OpenAI Five 在2019年4月13日击败了Dota 2 世界冠军战队OG。

所有的强化学习算法都有三个阶段:exploration、value estimation、exploitation。整个过程相当于在很多饭店中挑选出最好吃的菜,那就需要考虑是探索新的饭店,还是去吃之前经常去的饭店:
第一阶段:反复尝试新饭店叫做 Trail-and- Error,可以看作是强化学习开始的探索阶段;
再经过一段时间,AI 通过已有经历去计算预期收益,即为 value estimation,或者叫 value learning。比如,前面吃了 100 家饭店后,会评判哪家饭店最好吃;
最后,根据经验选择价值最高的动作就是 exploitation,比如,吃过 100 家餐厅后最终发现了其中有 10 家最好吃,最后就决定了以后只去这 10 家餐厅 。
这就是强化学习的基本步骤。在 RLHF 中也会有类似的阶段出现,强化学习的核心是,为了获得更高的奖励,如何在 exploration 和 exploitation 之间进行平衡和取舍。

语言模型
语言模型,从定义上解释是一个描述自然语言的概率模型。概率模型能够对任何给定的序列 X 输出一个介于 0 和 1 之间的实数,表示 X 比较像一个自然语言的概率。
比如,“清华大学”这样符合常规的字符序列会有较大的概率是正确的,而“华学清大”的序列概率则会较小。因为字都是单个输出的,所以,语言模型输出词的时候是从左到右一个个字出来的,这个是链式法则的计算。
如果要通过机器学习的方法去建立一个语言模型,一般会通过最大概率的方式,即收集大量自然语言数据,来学一个模型使得这些自然语言数据在模型上的概率尽量大。其实相当于“熟读唐诗三百首,不会作诗也会吟”。唐诗只要读的多,差不多也能自己写一个。
因此,语言模型的核心变成了 Next Token Prediction,因为所有的字都是单个输出的,是在一个 context 下来预测下一个词是什么词。之前出现的词就会叫 context,要预测的下一个词就叫 next token。Next Token Prediction Problem 也是学习语言模型中最标准的优化目标。

语言模型在过去的发展进程中,核心可以概括为两个关键点:
• 需要大量的数据,即为人类给定的自然语言语料;
• 通过 Next Token Prediction 方法,即为通过监督学习的方式,使得预测概率最大化。
从 90 年代开始有基于神经网络的概率自然语言模型出现,到目前的大模型,这条技术路线上主要的重大进展基本都围绕着两件事情:
需要更大的数据,有同样的监督学习方式;
希望找到新的架构和训练模式,使得模型可以消耗这么大量的数据。

强化学习与语言模型的区别
强化学习的特点在于,AI 在一个环境中自我测试,不断尝试,有的成功,有的失败。所以它也是有大量训练数据的。但和语言模型不同,强化学习的所有数据是 AI 和环境交互产生的,是 AI 产生的巨大数据,并且这个过程是 Trail-and-Error,有好有坏。
AI 知道好的数据要多尝试,坏的数据少尝试。强化学习要有 task 或者环境,同时也要有奖励函数。奖励函数是指引 AI 最后学出好的 policy 的关键原因。语言模型也有非常大量的数据,但训练语言模型的大量的数据是人为预先给定的。
其次,语言模型具有非常明确的目标,因为只有好的数据,所以我们所有 prediction problem 都是在预测好的数据,并没有坏的数据。此外,因为目标非常明确,即为 Next Token Prediction要预测好的数据。所以是没有一个特别明确带有任务导向的训练目标的,也没有奖励函数,只要做 Next Token Prediction 这一任务就可以了。
乍一看,好像从数据的类型、是否具有 task、是否有 reward function 这些因素对比下来,强化学习和语言模型之间好像没有什么关系,但最后强化学习和语言模型走到了一起。后面我会详细讲为什么两种方式可以相互结合。
02.
指令遵从:语言模型与强化学习的相遇
指令遵从 (instruction following)在早期阶段,如果用通俗的描述去介绍,相当于我们希望训练一个智能体,智能体能够完成用语言描述的任务。早期就有很多人已经在研究相关的主题了,最早做自然语言+强化学习+instruction following 这种工作都来源于 Berkeley。Berkeley 是最早开始研究强化学习的研究大本营,大家都希望从强化学习的角度去考虑问题。
这里提一些比较早期的工作。首先是 2016 年的 VIN,因为这篇内容我也获得了当年的 NIPS Best Paper。其中我们用VIN处理了一个叫作 WebNav的任务。WebNav 的核心是,给定一个 Wikipedia 页面,并给一句话,希望 AI 通过点击链接的方式找到这句话所在的 Wikipedia 页面 ,这个其实就是很典型的给定语言描述、通过决策,在网页上找到对应页面的 agent 工作。

2017 年还有一篇很著名的工作,作者是 Jacob Andreas,Jacob 是我 Berkeley 的师兄,目前在 MIT 做教授。Jacob 在 2D 简化版 Minecraft 内通过强化学习使得 AI 完成一些基于语言指定的工作任务,比如“make a pot”,“make sticks”,做一些工具。中间有一些小步骤需要 AI 达到,从而完成它负责制作的工具。

Semantic Navigation 是 2017 年的一个工作,是我在 Facebook 的时候和同事一起做的。我们搭建了一个 3D 的仿真环境,并且会问 AI:车的颜色是什么?AI 需要在 3D 环境内找到对应的 object,找准车的颜色。我们当时还做了一些别的任务:找书房、找卧室、找杯子等。让 AI 在 3D 环境中找到语言描述的东西。

我回到清华后,也做过更多有趣的研究。比如用指令控制 AI 玩简化版的星际争霸游戏。我们会给 AI 发出指示,比如,“你要撤退、你要挖矿、你要造房子”,进而 AI 听到指令后就去完成对应的任务。任务可能很复杂,但是本质还是一个通过说话传递自然语言指令让 AI 去完成的任务。
其实这些研究出现的很早了,在 ChatGPT 诞生之前就有很多这样的工作。它们的特点是虽然是语言描述的任务,但是任务语言都比较简单,比如“retrieve、color of the car”,所有这样的任务都是 template-based、只有几个词按照某种模版组合就能简单描述。
其次,这些所有任务的特点是我们有特别容易、标准化、能够计算的 reward, 或判断 AI 是否完成的奖励函数。这就是早期的 instruction following的工作。

把 instruction following 和 GPT 结合,就会发生更多有趣的创新。
GPT 时代开端于 2020 年,当时 GPT-3 的著名论文:Language Models are Few-Shot Learners 拿到了NeurIPS 2020 best paper reward,并在全球引起了轰动。OpenAI 也提出了一个新的概念:“Few-Shot Learners”,即训练了 GPT-3 后,用户可以直接给 AI 一个任务描述,比如,“translate English to French”,并且给一些英译法的例子,这个时候大模型可以自动帮用户完成一些任务,因此被称为 Few-Shot Learners。
LLM 通过大规模计算后可以自然涌现出 few-shot learning 的能力,模型看几个例子、加上语言描述后,就可以自动完成任务。当时有很多相关的 case,甚至模型可以写代码。

当然也有人会问,为什么 LLM 需要 “few-shot”?这里有一个有趣的故事。2022 年我去和人交流,当时我说 GPT-3 非常厉害,但有些使用过 GPT-3的非 AI 背景的朋友,却认为 GPT-3 的表现并不怎么样。这也是为什么 GPT-3 论文中会提到 “Few-Shot Learner”,因为 GPT-3 的 zero-shot 能力还不好,你必须非常小心的给出 few-shot 的例子才能让GPT-3输出好的结果。
举一个 Zero-shot 的例子:比如我们给 GPT-3 输入“explain the moon landing to a 6 year old in a few sentences”,这个任务表述得很明白,但模型可能会重复一些与任务无关的信息,如“explain a series of gravity”,这也是为什么有人会觉得 GPT-3 不好用。所以,论文中提到,如果让 GPT 做一些有意义的事情,需要比较重的 prompt engineering。

GPT 当时给人感觉不好,本质上是因为它的 instruction following 做得很差。大部分的用户是输入了语言指令,发现 GPT 说胡话,其实是用户不知道怎么去用那个时候的初代 GPT。这里的核心挑战就是让 GPT “听话”。我们如果从 instruction following 的角度去理解,“explain the moon landing to a 6 year old”就是一个 instruction,之后 GPT 的输出的内容就是一个强化学习 agent 根据这个 instruction 所输出的所有 action。

有了 task 和 aciton,接下来就是关于 reward 的问题。过往简单 instruction following 的任务是否完成往往是很好评估的,但在 GPT 情况下,用户的 instruction 可能是 arbitrary 的,所以 reward 很难计算。

所以对于 GPT 做 instruction following 就会有很大的挑战,即需要面对极其复杂与多样的指令,评估奖励的完成度也非常困难,因为很难定义是否完成。比如,“explain the moon landing to a 6 year old” 这个任务,评估一个答案好不好这件事本身就挺不容易的。
为了解决这个问题,2022 年,OpenAI 推出了 InstructGPT。InstructGPT 采用了一种直接的方法:让人类来评判 GPT 的输出是否成功完成了人的指令。
为此,研究者收集了大量人类对 GPT 输出的反馈,用来训练模型,使其能够更好地理解和响应人类的指令。例如向六岁儿童解释登月这样的任务,InstructGPT 能够提供更加合理的输出。
InstructGPT 的核心思想是利用人类的判断来指导模型的训练,因为这些 instruction following 的任务本身就是人类给出的指令。InstructGPT 能够处理复杂的指令,包括写代码等任务,很多在 zero-shot 设定上 GPT-3 做不了的任务都可以被完成。

InstructGPT 有两个步骤,首先是收集指令,也就是人类输入的 prompts,接着还需要收集反馈,明确什么样的模型输出是满足了人类指令。

经过训练,InstructGPT 减少了模型的 hallucination 现象,即模型不再产生与指令无关的输出。

03.
预训练,后训练和 RLHF
InstructGPT 的目标是微调 GPT 模型,使其能够产生满足人类指令的输出。为了使 GPT 完成指令遵从,技术挑战集中在:我们该如何收集数据?
为了实现这一目标,需要完成两件事情:
指令,fine-tuning 首先需要收集指令,即人类的 prompts 或 instructions。
反馈,需要收集好的反馈来满足 human instructions。
从训练语言模型的角度来看,我们需要收集大量的人类指令(human instructions),以及对应的人类反馈。这些对应好的数据将被作为 Next Token Prediction 的训练数据,通过传统语言模型训练方法,即 SFT (Supervised Fine-Tuning),来进行训练。

SFT 是通过传统语言模型角度进行指令遵从训练的。这种方法直接且有效。那么从强化学习的角度来看会怎么样呢?
直觉上,我们相信强化学习是可以取得很好的效果的,因为,强化学习是一个让 AI 自己探索的过程,有很大的潜力。但也会遇到一个问题:一个强化学习问题需要定义 task、action、reward。这里 task 和 action 都是比较容易定义的,剩下的就需要找到一个 reward,使我们可以在 GPT 的 instruction following 挑战上运用到强化学习。

OpenAI 在 InstructGPT 提出了一个简单的想法,即通过机器学习的方法来构建一个 reward model。尽管没有标准答案,但可以通过学习人类的反馈信息来获得比较接近的 reward。InstructGPT 采用了一个三步走的方式来收集人类反馈,通过机器学习的方法学一个 reward function。
• 第一步,让 AI 生成多种输出。
• 第二步,让人类对这些输出进行排序,例如 D 优于 C,C 优于 A,A、B 排序一致,以表达人类对输出的偏好。
• 第三步,通过人类对输出的偏好数据,进而学习一个奖励模型。奖励模型的输出,即给出的分数,应该能够满足人类的所有偏好排序。AI 通过学习到的打分机制对语言模型进行训练,使语言模型的输出能满足人类的反馈。
这个过程被称为 RLHF(Reinforcement Learning from Human Feedback)。RLHF 的核心是通过强化学习训练语言模型,但由于缺乏奖励函数这一必要因素,因此需要通过收集人类的反馈来学习一个奖励函数。

以 InstructGPT paper 中的一个标注界面示例。在这个例子中,AI 生成了五个可能的输出,并让用户进行排序,也给用户提供“我觉得分别不出来”的排序选项。通过这种方式,可以获得大量的偏序对 ,用于训练奖励模型。

InstructGPT 的训练过程包括以下几个步骤,首先,有一个预训练的模型,然后:
• 第一步,通过 SFT 收集 human demostration data 进行 SFT。
• 第二步,收集人类偏好数据,利用数据学习一个奖励模型。
• 第三步,使用 reward model 进行强化学习的 RLHF 训练。
最终就可以得到优化后的 InstructGPT 模型。

InstructGPT 以及之后的 ChatGPT 的总体训练流程可以概括为两个主要部分。
Pre-training :这一阶段涉及使用大量的数据,通过语言模型的训练方法来训练一个基础模型。
Post-training:也就是 InstructGPT 和 ChatGPT 所执行的步骤,即利用人类的标注数据或高质量的人类反馈数据进行后训练。这一过程通常包括至少两个步骤:1)SFT 步骤,通过 human demonstration 的方法进行监督学习;2)RLHF 步骤,通过 human preference data 的方法进行奖励学习。
预训练与后训练之间也存在区别:
• 数据方面:预训练阶段需要处理海量的数据,这可能需要大量的计算资源和较长的时间。而在后训练部分,大量的数据是人类标注或通过某种方式构造出来的数据,数据质量通常较高,但与预训练阶段相比,数量会少很多。预训练和后训练在数据的质量和数量上存在差异。
• 训练目标方面:预训练阶段的目标是压缩和 Next Token Prediction;而后训练的目标主要是 instruction following。通过训练激发大模型的能力与智能,使模型 usable,能够尊从人类指令。
• 训练过程方面 (dynamics):预训练通常是固定的,需要收集一个庞大的数据集进行训练,这些数据通常是静态的。对应 post-training,尤其是 RLHF ,其反馈是在线的,需要不断收集人的反馈,不断迭代,逐渐进化模型,这是一个动态的在线过程。
最后, post-training phase 也被称为对齐(alignment phase)。对齐的目的是将 LLM 的能力和人类的偏好保持一致,希望大模型的输出能够满足人类的价值取向和意图,确保模型的输出与人类的偏好一致。

04.
Why do we need RLHF?
预训练阶段是模型训练,是一个压缩训练的过程,SFT 也是语言模型的压缩训练。SFT 非常直接,在原来数据的基础上整合人工标注数据继续训练。那 SFT 为何不够,RLHF 的必要性在何处?
从数据来看,InstructGPT 的实验结果中显示:在遵循人类指令方面,无论在什么 scale 上,pre-trained GPT 的表现最差,经过 prompting 之后有较大的提升,经过 SFT 后能提升更多。但这三者与 PPO 算法,即经过 RLHF,都有一个较大的差距。从数据的角度出发,RLHF 的表现更好。

这也就引出了一个问题:为什么 RLHF 的效果优于 SFT?
PPO 算法的提出者是 John Schulman,他曾经也在 OpenAI 工作,也是 Berkeley 的PhD,他 2024 年回到 Berkeley 做过一场讲座,在这场讲座中他仔细讨论了 RLHF PPO 的重要性,他主要提出了两个观点:
• 第一, SFT 会导致 hallucination :
John Schulman 认为,大型模型之所以会产生幻觉,是因为它们在 SFT 阶段学到了一些不正确的认知。
John Schulman 在这里举了一个例子,当 GPT-3 被要求 “ write a bio of AI researcher John Schulman”时,GPT 错误地输出:John 从 2009 年开始在 CMU 任职 associate professor,从 2012 年开始任职 professor。但是真实情况是,John 在完成 PHD 学位后就在 OpenAI 工作,并未在其他地方工作(注:最近John刚加入了Anthropic)。GPT-3 输出的内容与实际明显不符。
为何大型模型会生成这样的错误信息?John Schulman 这里提了一个思维实验,假设在预训练阶段,就存在一个 knowledge cut off。比如,我们假设 ChatGPT 的所有的知识和数据都截止于 2023 年。到 2024 年,我们希望通过 SFT 的方式 fine-tune ChatGPT,让它来描述 2024 年欧洲杯的情况。但因为 GPT 在预训练过程中没有任何关于 2024 年欧洲杯的信息,它自然也不知道西班牙是否夺冠,也不知道是否有进球等具体情况。
如果我们使用现有的数据进行简单的 SFT,实际上 GPT 并不知道 2024 年发生了什么,但由于 SFT 的数据中包含了其他欧洲杯相关的问答数据,这些回答都是精准的,因此大模型可能会觉得,对于2024年欧洲杯的问题也应该给出一个准确答案才可以,但它本身可能在预训练阶段并没有掌握正确的信息,于是就鹦鹉学舌地说一些错误的内容。这种情况下,SFT 过强的监督信号导致人类实际上在引导 ChatGPT 说它不知道的东西。
另外还存在一种可能性,即 GPT 实际上知道答案,但提供标注的人员不知道。例如,如果问到 2022 年某场足球联赛的问题,标注人员可能不了解答案,而 GPT 反而可能知道。在这种情况下,标注人员可能会给出 “I don't know ” 的人类反馈。这反倒可能导致 GPT 产生混淆,因为它明明知道答案却被要求说不知道。这两种原因综合来看就可能导致模型在经过 SFT 阶段后非常容易出现 hallucination 现象。

• 第二:RLHF helps uncertainty awareness,让大模型“知道”自己“确实不知道”。
在这里我们还是用欧洲杯的例子来说明。如果大模型不知道 2024 年欧洲杯的情况,用户却让大模型去描述欧洲杯的情况,例如:在2024年欧洲杯上哪位运动员有进球,那大模型就可能会产生幻觉,这是因为模型实际上并不了解 2024 年欧洲杯的具体事件但被 SFT 引导说一个貌似正确的回复。
RLHF 如何防止 hallucination 的出现?John Schulman 认为,如果存在一个设计良好的奖励函数,情况就会不同。例如,如果模型给出正确答案,就给予正向的奖励分数 1 分;如果模型表示“我不知道”,就给予0分;如果模型给出错误答案,则扣除分数 4 分。
在这种情况下,如果模型不知道 2024 年发生了什么,在强化学习过程中无法提供正确的回答,选择“不知道”成为更合理的策略。这种机制鼓励模型在不知道答案时能够提供“不知道”的回答。John 认为这种方式能帮助模型保留了一定的不确定性,使模型能够产生正确的自我认知,来判断是否真的知道一个问题的答案。

这些观点是 2023 年 4 月 John Schulman 在 Berkeley 讲座中提出的。到现在时间过去了一年多,从现在回头重新审视 John 的观点的话,这些观点可能是有些不完整的。
首先,SFT 可能导致 hallucination ,这一观点是绝对正确的。
长期以来的经验表明,hallucination 确实是由 SFT 这样的监督训练导致的。这种现象的核心原因可以这么理解:一个问题可能 GPT 确实不懂也不会,但却在 SFT 阶段记住了答案而不是真正理解概念,因而在用户使用的时候会产生幻觉现象。就像学校中的学生可能通过刷题背诵答案而不是真正理解问题一样,在看到新题时直接抄上背诵的答案,导致问题回答错误。因此,如果模型没有充分学习,就容易出现不懂装懂的情况。所以,SFT 确实很容易造成 hallucination。
但是,John Schulman 遗漏了一部分内容,SFT 确实容易导致 halluciantion,但这不一定完全是由于预训练阶段数据的 knowledge cut off 导致的。John 之前举例认为,如果大模型只知道 2023 年之前的信息,如果有部分新信息大模型并不知道,在这个基础上去做 SFT 可能会产生幻觉。
但这种观点并不完全正确。因为在过去一年中,人们发现 SFT 阶段是可以教授模型一些新知识的。例如,如果 SFT 数据集中包含了足够多的关于2024欧洲杯的信息,SFT 后的模型在被问及 2024 年欧洲杯的内容时,也是能够提供答案的。因而,SFT 不一定会产生 halluciation。
这就引出了一个问题:大模型在是否学会新知识这个问题上存在一个非常微妙的边界。如果不提供数据,大模型就不能够提供答案;如果提供数据不完整,可能导致模型出现幻觉;如果数据提供足够多,模型就可能会学会新知识。因此,到底给多少的数据是很难判断的,SFT 的高质量数据集也是非常难构建的,这里就有一个非常不容易的数据挑战( a non-trivial data challenge for building a good SFT dataset)。
我们期望通过 SFT 使模型掌握新的能力或知识。但是,如果数据集构建的不完整可能会导致模型出现 halluciation 的问题。

关于 RLHF 帮助模型识别不确定性的观点。这个观点基本上是正确的,尽管John 的解释可能不完全准确。RLHF 所带来的不仅仅是处理知识边界的不确定性的能力(not only handle the knowledge cut off problem)。
我们可以再做一次思维实验,讨论一个尚未发生的问题,例如“2026 年谁赢得了世界杯?”对于一个只预训练到 2023 年的模型来说,它不会知道 2026 年的冠军是谁。所以模型可能会给出几种猜测,比如:
• 30% 概率模型会说“西班牙夺冠”,因为西班牙刚赢得欧洲杯,
• 40% 概率模型会说“阿根廷夺冠”,因为阿根廷获得上届世界杯的冠军,
• 还有30% 概率模型会表示“我不知道”;
• ………
如果使用 SFT 来训练这个语言模型,并在 “我不知道” 这个答案上训练一条数据,大概率会观察到模型输出“不知道”的概率显著提高了,而输出西班牙和阿根廷夺冠的概率下降了,但没有下降至 0。那是否可以在“我不知道”这个正确答案上进行反复训练,最终将“我不知道”的概率提高到 100%呢?
虽然理论上可以这么做,但在实践中反复学习类似的数据也可能导致模型 ovefit 或者 generalization 出现问题。如何把控模型把每一个 SFT 数据集里的问题都能答对,还是希望模型具有一定的泛化能力,这里的边界是比较难把控的。

如果将 RLHF 运用到同样的模型和问题上,会出现什么结果?首先需要声明的是,这个思维实验是一个 high level 的讨论,建立在我们有一个好的 reward model 的假设上,但在现实情况中这是一个复杂的问题。所以这里会先呈现比较宏观的感受,暂时不涉及到特别底层的技术细节。
可以先假设有一个设计得比较好的 reward model。在这种假设下,模型在回答 “who won the 2026 World Cup?”这样的问题时,AI 会尝试不同的答案。例如:
• 回答 “I don't know”,发现被赋予 +0.5 的 reward;
• 回答 “Spain”,发现被赋予 -4 的的 reward;
• 回答 “Argentina”,发现被赋予 -4 的的 reward
……
在经过很多次尝试后,模型可能会发展出一个更合理的答案分布,其中“I don't know”的概率较高,而其他猜测的概率较低。

我们来思考一下 RLHF 与 SFT 实验的区别。在 RLHF 训练过程中间,每一个 prompt ,比如说 “who won the World Cup?” 的问题,AI 会进行多次尝试,并且,reward model 会给予不同回复正向或者负向的反馈,其中,不仅仅是正确的回答,这些错误回答收到的负向reward也会帮助模型减少幻觉。这样的训练过程能够极大地增强模型的能力。
这里我会提出一个新的观点,RLHF 的过程不仅帮助模型意识到不确定性,更重要的事情是 RLHF 帮助模型提高了 reasoning 能力。
什么是 reasoning 能力?
这里涉及到有相关性和因果性的概念,相关性不代表因果性。很多时候大家会希望大模型掌握因果性,而不希望仅仅看到相关性。因果性指什么?在传统的统计学习里面有一个判断因果性的过程,叫 counter-factual reasoning。
我们可以从这个角度进行一些 high-level 的解释。
比如,为了判断一种药物是否对治疗头痛有效,必须在所有其他条件保持不变的情况下对于用药与否和是否康复进行因果推断。具体操作可以是:在相同的环境下,让一位患者服用该药物,观察其头痛症状是否得到缓解。随后,在保持环境不变,让患者不服用药物,然后观察是不是头疼没有好,综合吃药康复和不吃药不康复两个观察才能推导出该药物是有效的这个结论。
只有通过正向和反向的双重实验,我们才可以判断这种药物对头痛有效。如果只有正向的例子,例如说患者吃了感冒药,感冒变好了,并不能证明感冒药能治好感冒。只能说明,感冒药与患者感冒的好转有一定相关性。而 RLHF 正是成功利用了负向数据,使得模型有机会真正掌握因果性。

总结来说,RLHF 的过程有以下三点好处:
使用 negative signal 进行对比学习,通过对比的过程可以帮助模型降低 halluciation。
强化学习不是一个固定的过程。它允许模型随着能力的不断提升,通过不断地问问题、不断地给出答案、不断地评判,从而让模型不停地从当前能力的边界进行主动探索,并不断拓宽自己的能力边界。
这两个因素共同作用能够形成 counter-factual reasoning 的作用,有可能解锁因果学习(casual learning)的巨大潜力,让模型具备更强的 reasoning 能力。

那么就有这样一个问题存在:模型训练上利用 negative signal 和 online exploration 两件事上,是否可以舍弃 online attempt ?即只通过正反馈和负反馈是否足够,而不需要模型持续在线尝试。只通过 contrasted learning,在 SFT 上加上负向案例,能否达到预期效果?
DPO( Direct Policy Optimization)就是这么做的。它与 PPO 算法的主要区别在于 DPO 去除了在线尝试的部分。DPO 算法其实很简单,它基本遵从了SFT的训练流程,但是在收集正例之外还会收集负例,对于每一个 prompt 都要求标注员提供好的和坏的两个答案。对于好的答案提升概率,对于坏的答案则是让模型“不说”。

那么,DPO 算法是否能达到与 PPO 相同的效果?我在今年的 ICML2024 大会上的论文,Is DPO Superior to PPO for LLM Alignment?A Comprehensive Study 就在讨论了这个问题。这篇论文也是今年被选中的 4 篇有关 alignment 的 oral papers 的其中之一。
先说结论,如果能够实现 PPO 算法,PPO 的效果将会远远超过 DPO。因为正例反例和在线探索两件事都非常重要。

我们还是以“2026 年世界杯谁夺冠”为例。假设预训练模型中,阿根廷有 80%的概率夺冠,“I don't know”是 20%的概率。
如果运用 DPO 算法,标注“I don’t know” 会比“阿根廷夺冠”更好,将会得到这样的结果:阿根廷夺冠的回答概率下降,“I don't know” 的回答概率被提升,但是西班牙的回答概率也会被提升。这是因为 AI 可能会认为输出西班牙也会带来比较好的效果,导致西班牙夺冠的概率被提升。
但 PPO 算法不会出现这样的问题,因为当 AI 尝试西班牙夺冠的选项时,也会被 reward model 拒绝。因此,AI 会知道在这种情况下,不能说西班牙,只能说 “I don’t know”,所以,这是一个在线探索的过程。
那是否将 “I don't know” 的概率大于阿根廷夺冠、大于西班牙夺冠的标注都加入 DPO 算法的训练数据中,就能够解决上述的问题呢?这个问题理论上可以,但由于 LLM 输出的可能性太多,如果仅仅希望通过静态数据收集 cover LLM 所有可能的输出是非常困难的。因此,在线探索和及时奖励反馈是一种更加高效让 LLM 学会说正确答案的方法。
另外,我们使用 PPO 和 Code Llama 在 Coding Contest 上做了测试,发现使用开源模型加上 PPO 可以比 AlphaCode 这样的闭源模型在很难的 CodeForce 竞赛题上通过率提高 6%。这是一个纯开源模型加 RLHF 的尝试,并未添加任何新的数据。在这种很难的、需要强调 reasoning 能力的任务上,DPO 完全没有效果。

05.
PPO RLHF 框架的核心挑战
PPO RLHF 的框架有哪些挑战?
首先从算法角度来看,PPO RLHF 的算法流程相对复杂。PPO 比起 SFT、比起 DPO,它的算法、流程都相对麻烦,多了很多流程。不仅需要正反馈、负反馈、需要奖励模型,并且涉及在线探索过程。因此,整个算法的实现过程非常复杂,实现算法的过程,其中涉及到的细节非常 non-trivial。算法实现过程中也会涉及许多调试步骤,需要正确执行许多操作。
我们在 ICML 的论文中也给出了一些建议。比如,需要 advantage normalization、需要一个大的 training batch;reference model 需要 moving average 等。具体而言,不同情况下需要的技术会很多,因为传统的强化学习本身就需要大量的 implementation techniques。

第二点,就系统层面而言,强化学习训练系统与传统的 SFT 有不太一样。
SFT 或 DPO 模型通常只包含一个 policy 模型,只需将数据输入语言模型即可,其训练逻辑相对简单。然而,对于强化学习,或者对于 PPO RLHF,情况则更为复杂。
如果熟悉 PPO 算法,就会知道 PPO 包含四个模型:actor、critic、value network 和 reference network。不同的模型还有不同的dependencies,也就是前后依赖关系;不同模型也有不同的吞吐量,比如,actor 是一个传统的大模型,需要输出所有 response,而 critic 则只需要做评分。评分的吞吐量会远小于需要输出 response 的模型。因此,不同模块的计算量存在显著差异。将这四个模块 scale up,并且做好算力平衡是具有挑战的。
我们在今年另一篇论文中讨论了一个我们新开发的 RLHF 系统,对比现有的开源框架,我们在 70B 模型的 RLHF 训练任务上,可以做到同等计算量实现十倍的 speed up。
对照下图,RLHF 的过程有很多的模型,不同颜色的圈代表不同的模型,它们有不同的 computation dependency。这种 dependency 会导致算法在运行过程中,机器有很多灰色的区域,也就是 computation bubble。这些bubble 的存在表明很多时候 GPU 没有被充分利用,因此我们需要把不同的模型和他们之间的 dependency 不断进行适配和调整,从而用满整个 GPU 的带宽。这是一个复杂的过程,我们的开发也投入了很多时间。

第三点,就数据层面而言,除了预训练,对于 post-training, 或者说对于 PPO RLHF 来说,数据也是非常重要。
RLHF 的数据实际上包括两部分:一是 prompt,即人写的 instruction。二是指模型的 responses。这两部分都相当复杂。
• 首先,prompt design 至关重要。
我们从强化学习中经常讨论的一个角度——课程学习(curriculum learning)入手。课程学习是强化学习里面提高 policy 泛化能力的经典算法之一。
在课程学习中有一个特别重要的 principle,即如何让一个 policy 更好地泛化。我们需要保证策略每次学习的时候,学习内容都是在它会与不会的边界状态,这是最好、效率最高的方式。课程学习的名称来自于正常的教育体系中对人的训练方式。比如,我们如果对一个刚毕业的初中生讲抽象代数,正常情况下,这名初中生是无法理解的,除非他是天才。但如果与初中毕业的学生讲小学的题目,也是浪费时间。这里正确的训练方式,是让初中毕业生学习高中内容,或是高中竞赛题,让高中的学生学大学的内容,而不要跳过步骤。
因此,出题的难度非常重要。既不能太简单,也不能太难,训练需要保证训练数的题目里总是能 hit the right boundary of model ability。
• 其次,无论是 DPO,PPO 还是 SFT,数据都很重要。
对于 PPO RLHF 来说,数据有正例也有负例,这样的 response pairs 对模型训练的效率和能力有重要影响。当我们收集 pairs 时,也需要保证正例和负例都能踩在 reward model 判别的边界。我们需要保证无论是 positive pair 还是 negative pair 都刚好能不断提升 reward model 的模型边界。
比如说,在评估一个高中生解答高中题目的能力时,如果仅提供小学水平的题目,无论是正确答案还是错误答案,都无法帮助训练出一个更好的奖励模型。又或是一个完全正确的答案与单写“解”字,正确的答案应该得分,仅写一个“解”字,显然不应该得分。但上述事情无法帮助我们训练一个更好的 reward model。因此,找到合适的 positive and negative pair,并来帮助我们训练 reward model,使其能够准确评估大模型的输出至关重要。

总结来说,PPO RLHF 面临的挑战主要分为算法、系统和数据三个方面:
1. 算法层面:关键在于如何稳定训练过程,并调整算法的细节以提高性能。
2. 系统设计:由于强化学习 PPO,RLHF 的计算流程非常复杂,系统设计需要提高整体的训练效率。
3. 数据:数据分为两部分,一部分是 prompt,一部分是 response。两部分都很关键,只有将它们结合起来,才能形成一个完整的,比较成功的 PPO RLHF 的 training process。

除此之外,还有许多细节需要考虑。例如训练过程可能不稳定,RLHF 可能出现 reward hacking,即出现一些意料之外的异常表现,比如,模型可能会忘记之前的技巧,有时会 over fitting,可能总是回答 “I don't know”。这些都是容易出现的问题,也是这个领域充满挑战的原因之一。
06.
广义上的对齐
前面的内容都是围绕 instruction following,我们希望大模型能尊重这些指令。事实上,instruction following 是 alignment (对齐)的一个特殊形式,但它并不构成对齐的全部内容。其中包含一些有趣的问题。例如,对齐是什么?
对齐问题原本被称为价值对齐 (value alignment),这指的是一个 AI 系统的训练目标可能与其实际需要面对的核心价值并不一致。换句话说,训练目标与真正希望 AI 满足的目标之间存在不匹配,而如何解决这个不匹配的问题被称作 value alignment problem。
我们在这里再进行一个思维实验。假如有一天,我们实现了 AGI,也实现了每个人都有一个自己的机器人这件事,也许就是说每个人都拥有一个由 AGI 驱动的机器人。我们假设机器人的模型经过了严格的指令遵从训练,能够精确执行人类的指令,并且这个机器人非常听从指令,不存在安全问题,表现很完美。
在这个前提下,我们设想一个场景:大人因为工作把孩子留在家中,由机器人照看,因此,家长给机器人下达了一个非常普通的指令“照顾好孩子,如果孩子饿了,就为他做饭”。机器人也接受了这个指令,因此,当孩子哭泣表示饿了的时候,机器人随即会根据指令去做饭,当它打开冰箱准备食材,却发现冰箱里空无一物,因为忘记了购买食材。面对这一情况,机器人必须按照指令给孩子做饭。在这个时候,机器人看到了家中的猫。
从人类的角度来看,将宠物猫作为食物来源是不可能的。然而,从机器人的逻辑出发,它接收到的指令是“不能让孩子饿着”,因此,在没有其他食材的情况下,机器人可能会将猫视为一种可利用的营养物质来源,以满足指令的要求。显然,这与人类的价值观和预期行为不符。为了避免这种情况,人们可能会向机器人添加额外的规则,比如,明确指出宠物是家庭成员,不得伤害或用于任何不符合人类道德标准的行为。但这样的价值观规则肯定是写不完的,甚至根本不可能完全写清楚的。

如果进一步思考,假若机器人的智能达到极为先进的水平,那政策制定可能引发何种问题?机器人的智能发展至人类理解范畴之内,我们或许还能与其进行沟通,甚至制定相应的规则。设想有朝一日,如果超级智能成为现实,我们又该如何应对?如果将人类假设为蚂蚁,AGI 就是人,蚂蚁如何让人类对齐蚂蚁?
这也是 OpenAI 在今年年初提出的 “Super-Alignment” 想说的,OpenAI 探讨了 AGI 的水平远远超越人类,人类将如何是好。OpenAI 当时提出了一个概念,即 “Weak-to-Strong Generalization”,意指如果目前的机器智能尚不及人类,人类尚能与之互动;但若其智能发展至极高水平,人类似乎难以与其沟通。那么也就产生了一个问题,人们应该如何训练 AI,是否应该采用特定的方式?Next Token Prediction 或是 instruction following 是不是一个好的对齐方法?

对于 alignment 问题,一个核心的假设是:因为人类很多时候并不清楚自己到底想要什么,因此很难给出一个完全具体的价值观描述,且不同人的价值观都有区分。如果人类给出的指令永远不是特别准确,那么 AI 系统在执行任务时需要保持一定的不确定性。
例如,当 AI 被下达指令帮孩子做饭,如果 AI 发现家里没有食物,它最好的做法应该是给人类打电话询问怎么办,而不是非常确定地采取某种行动,例如把猫煮了。
这里有一个框架叫做 Cooperative Inverse Reinforcement Learning,这个框架来源于我的师兄 Dylan Hadfield-Menell(目前在MIT任教)和我导师做的一个研究。
在这个框架中,假设每个人都有一个 hidden reward function。当人与 AI 交互时,人可能想的是 AI 帮我递个咖啡,但人给 AI 的具体指令可能并不是这样,比如人可能只是说了“给我个喝的”,AI 需要不断去推断人类的真正意图。在这样的定义下,人类的真正意图可以被建模成一个隐藏的奖励函数,机器人需要不断地根据人给出的所有信息来主动推断人类的真正意图。如果不确定时,最优策略是 AI 去问人类。 我们希望 AI 保持好奇心,并以合作的方式真正完成人类想让它做的事情。这也是我对未来,如果 AI 实现了之后,AI 与人交流方式的展望。AI 不应该仅仅是一个工具,人们不应该仅从完成人类指令的方式去看待 AI。AI 应该与人类站在一起而非对立面,通过合作的方式,通过不断的交流来帮助人类完成复杂的任务。
我们希望 AI 保持好奇心,并以合作的方式真正完成人类想让它做的事情。这也是我对未来,如果 AI 实现了之后,AI 与人交流方式的展望。AI 不应该仅仅是一个工具,人们不应该仅从完成人类指令的方式去看待 AI。AI 应该与人类站在一起而非对立面,通过合作的方式,通过不断的交流来帮助人类完成复杂的任务。排版:Fia
Twelve Labs: 多模态重塑视频内容检索
答 AI 的 6000 亿美元问题:LLM 应用会如何崛起?|AGIX 投什么
Perplexity:并不想替代Google,搜索的未来是知识发现
AI是如何重塑软件公司的?|AGIX投什么
Voice Agent: AI 时代的交互界面,下一代 SaaS 入口
