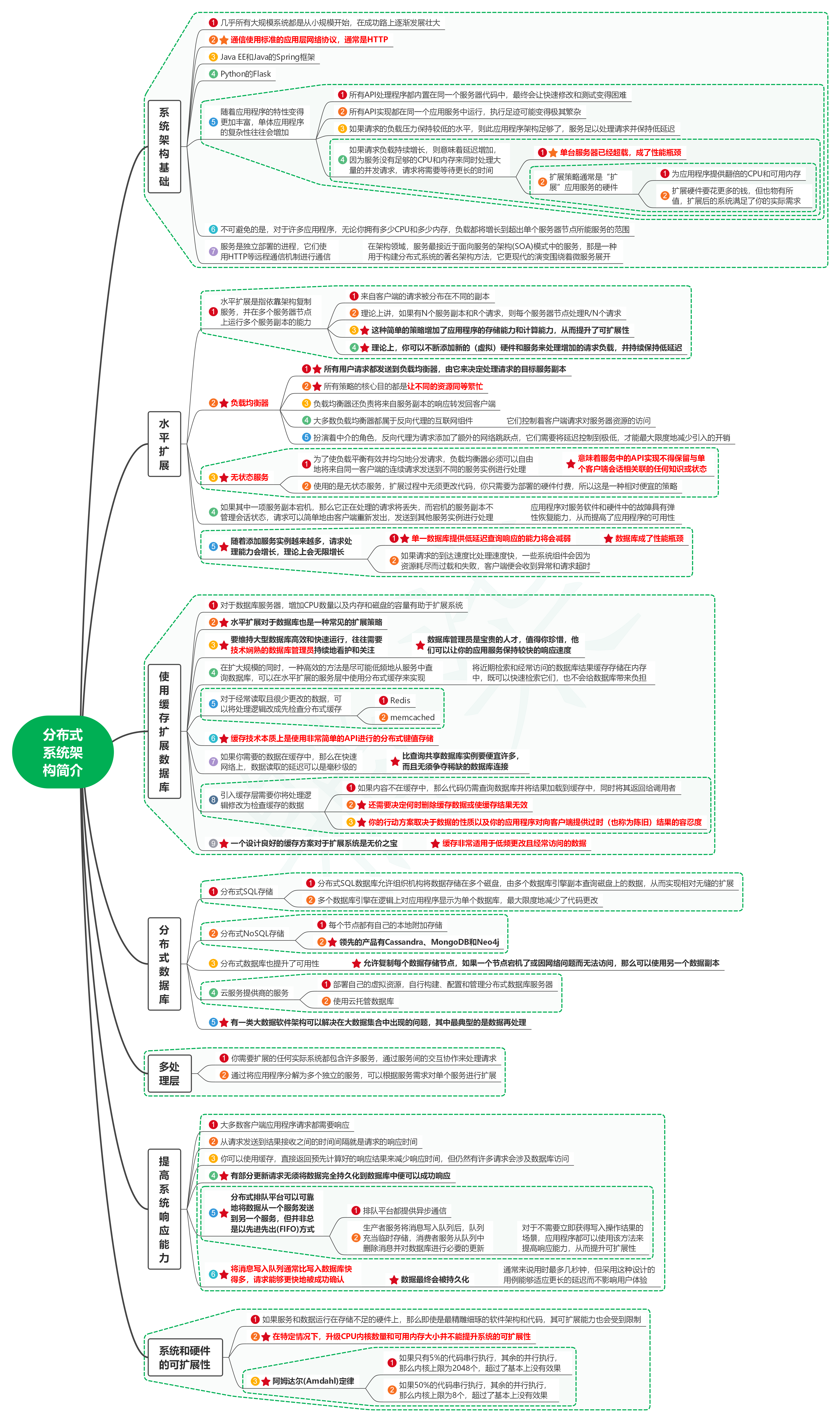
1.1. 几乎所有大规模系统都是从小规模开始,在成功路上逐渐发展壮大
1.2. 通信使用标准的应用层网络协议,通常是HTTP
1.3. Java EE和Java的Spring框架
1.4. Python的Flask
1.5. 随着应用程序的特性变得更加丰富,单体应用程序的复杂性往往会增加
1.5.1. 所有API处理程序都内置在同一个服务器代码中,最终会让快速修改和测试变得困难
1.5.2. 所有API实现都在同一个应用服务中运行,执行足迹可能变得极其繁杂
1.5.3. 如果请求的负载压力保持较低的水平,则此应用程序架构足够了,服务足以处理请求并保持低延迟
1.5.4. 如果请求负载持续增长,则意味着延迟增加,因为服务没有足够的CPU和内存来同时处理大量的并发请求,请求将需要等待更长的时间
1.5.4.1. 单台服务器已经超载,成了性能瓶颈
1.5.4.2. 扩展策略通常是“扩展”应用服务的硬件
1.5.4.2.1. 为应用程序提供翻倍的CPU和可用内存
1.5.4.2.2. 扩展硬件要花更多的钱,但也物有所值,扩展后的系统满足了你的实际需求
1.6. 不可避免的是,对于许多应用程序,无论你拥有多少CPU和多少内存,负载都将增长到超出单个服务器节点所能服务的范围
1.7. 服务是独立部署的进程,它们使用HTTP等远程通信机制进行通信
1.7.1. 在架构领域,服务最接近于面向服务的架构(SOA)模式中的服务,那是一种用于构建分布式系统的著名架构方法,它更现代的演变围绕着微服务展开
2. 水平扩展2.1. 水平扩展是指依靠架构复制服务,并在多个服务器节点上运行多个服务副本的能力
2.1.1. 来自客户端的请求被分布在不同的副本
2.1.2. 理论上讲,如果有N个服务副本和R个请求,则每个服务器节点处理R/N个请求
2.1.3. 这种简单的策略增加了应用程序的存储能力和计算能力,从而提升了可扩展性
2.1.4. 理论上,你可以不断添加新的(虚拟)硬件和服务来处理增加的请求负载,并持续保持低延迟
2.2. 负载均衡器
2.2.1. 所有用户请求都发送到负载均衡器,由它来决定处理请求的目标服务副本
2.2.2. 所有策略的核心目的都是让不同的资源同等繁忙
2.2.3. 负载均衡器还负责将来自服务副本的响应转发回客户端
2.2.4. 大多数负载均衡器都属于反向代理的互联网组件
2.2.4.1. 它们控制着客户端请求对服务器资源的访问
2.2.5. 扮演着中介的角色,反向代理为请求添加了额外的网络跳跃点,它们需要将延迟控制到极低,才能最大限度地减少引入的开销
2.3. 无状态服务
2.3.1. 为了使负载平衡有效并均匀地分发请求,负载均衡器必须可以自由地将来自同一客户端的连续请求发送到不同的服务实例进行处理
2.3.1.1. 意味着服务中的API实现不得保留与单个客户端会话相关联的任何知识或状态
2.3.2. 使用的是无状态服务,扩展过程中无须更改代码,你只需要为部署的硬件付费,所以这是一种相对便宜的策略
2.4. 如果其中一项服务副本宕机,那么它正在处理的请求将丢失,而宕机的服务副本不管理会话状态,请求可以简单地由客户端重新发出,发送到其他服务实例进行处理
2.4.1. 应用程序对服务软件和硬件中的故障具有弹性恢复能力,从而提高了应用程序的可用性
2.5. 随着添加服务实例越来越多,请求处理能力会增长,理论上会无限增长
2.5.1. 单一数据库提供低延迟查询响应的能力将会减弱
2.5.1.1. 数据库成了性能瓶颈
2.5.2. 如果请求的到达速度比处理速度快,一些系统组件会因为资源耗尽而过载和失败,客户端便会收到异常和请求超时
3. 使用缓存扩展数据库3.1. 对于数据库服务器,增加CPU数量以及内存和磁盘的容量有助于扩展系统
3.2. 水平扩展对于数据库也是一种常见的扩展策略
3.3. 要维持大型数据库高效和快速运行,往往需要技术娴熟的数据库管理员持续地看护和关注
3.3.1. 数据库管理员是宝贵的人才,值得你珍惜,他们可以让你的应用服务保持较快的响应速度
3.4. 在扩大规模的同时,一种高效的方法是尽可能低频地从服务中查询数据库,可以在水平扩展的服务层中使用分布式缓存来实现
3.4.1. 将近期检索和经常访问的数据库结果缓存存储在内存中,既可以快速检索它们,也不会给数据库带来负担
3.5. 对于经常读取且很少更改的数据,可以将处理逻辑改成先检查分布式缓存
3.5.1. Redis
3.5.2. memcached
3.6. 缓存技术本质上是使用非常简单的API进行的分布式键值存储
3.7. 如果你需要的数据在缓存中,那么在快速网络上,数据读取的延迟可以是毫秒级的
3.7.1. 比查询共享数据库实例要便宜许多,而且无须争夺稀缺的数据库连接
3.8. 引入缓存层需要你将处理逻辑修改为检查缓存的数据
3.8.1. 如果内容不在缓存中,那么代码仍需查询数据库并将结果加载到缓存中,同时将其返回给调用者
3.8.2. 还需要决定何时删除缓存数据或使缓存结果无效
3.8.3. 你的行动方案取决于数据的性质以及你的应用程序对向客户端提供过时(也称为陈旧)结果的容忍度
3.9. 一个设计良好的缓存方案对于扩展系统是无价之宝
3.9.1. 缓存非常适用于低频更改且经常访问的数据
4. 分布式数据库4.1. 分布式SQL存储
4.1.1. 分布式SQL数据库允许组织机构将数据存储在多个磁盘,由多个数据库引擎副本查询磁盘上的数据,从而实现相对无缝的扩展
4.1.2. 多个数据库引擎在逻辑上对应用程序显示为单个数据库,最大限度地减少了代码更改
4.2. 分布式NoSQL存储
4.2.1. 每个节点都有自己的本地附加存储
4.2.2. 领先的产品有Cassandra、MongoDB和Neo4j
4.3. 分布式数据库也提升了可用性
4.3.1. 允许复制每个数据存储节点,如果一个节点宕机了或因网络问题而无法访问,那么可以使用另一个数据副本
4.4. 云服务提供商的服务
4.4.1. 部署自己的虚拟资源,自行构建、配置和管理分布式数据库服务器
4.4.2. 使用云托管数据库
4.5. 有一类大数据软件架构可以解决在大数据集合中出现的问题,其中最典型的是数据再处理
5. 多处理层5.1. 你需要扩展的任何实际系统都包含许多服务,通过服务间的交互协作来处理请求
5.2. 通过将应用程序分解为多个独立的服务,可以根据服务需求对单个服务进行扩展
6. 提高系统响应能力6.1. 大多数客户端应用程序请求都需要响应
6.2. 从请求发送到结果接收之间的时间间隔就是请求的响应时间
6.3. 你可以使用缓存,直接返回预先计算好的响应结果来减少响应时间,但仍然有许多请求会涉及数据库访问
6.4. 有部分更新请求无须将数据完全持久化到数据库中便可以成功响应
6.5. 分布式排队平台可以可靠地将数据从一个服务发送到另一个服务,但并非总是以先进先出(FIFO)方式
6.5.1. 排队平台都提供异步通信
6.5.2. 生产者服务将消息写入队列后,队列充当临时存储,消费者服务从队列中删除消息并对数据库进行必要的更新
6.5.2.1. 对于不需要立即获得写入操作结果的场景,应用程序都可以使用该方法来提高响应能力,从而提升可扩展性
6.6. 将消息写入队列通常比写入数据库快得多,请求能够更快地被成功确认
6.6.1. 数据最终会被持久化
6.6.1.1. 通常来说用时最多几秒钟,但采用这种设计的用例能够适应更长的延迟而不影响用户体验
7. 系统和硬件的可扩展性7.1. 如果服务和数据运行在存储不足的硬件上,那么即使是最精雕细琢的软件架构和代码,其可扩展能力也会受到限制
7.2. 在特定情况下,升级CPU内核数量和可用内存大小并不能提升系统的可扩展性
7.3. 阿姆达尔(Amdahl)定律
7.3.1. 如果只有5%的代码串行执行,其余的并行执行,那么内核上限为2048个,超过了基本上没有效果
7.3.2. 如果50%的代码串行执行,其余的并行执行,那么内核上限为8个,超过了基本上没有效果
