
作者:yongxin
编辑:kefei

Cisco 曾在 2018 年做过测算,全球已经有超过 75% 的数据是视频内容,互联网视频数据流量超过 50%。视频搜索市场存量很大,目前主要被 YouTube、TikTok 等视频巨头占领。但与文本数据不同,视频中的信息仍然难以通过简单的 Ctrl+F 来查找,其主要困难在于跨模态信息的理解、视频的高计算负担,以及可以应用于多领域的模型架构。2017 年 Transformer 的出现使得模型可以高效并行处理长序列和捕捉长期依赖关系,2022 年LLM 的出现进一步了增强视觉-语言模型架构,近两年的视频理解模型的发展已经证明了视频领域的模型可以真正完成理解任务。好的视频搜索方式能够带来巨大的用户粘性和商业价值,因此大量的视频资产就像未被采掘的金矿。另外从增量来看,视频智能问答、摘要、分类都是新的应用,最快跑出来的好模型、好产品有机会快速抢占市场份额。
Twelve Labs 成立于 2020 年,通过 API 为企业和开发者提供视频领域的多模态视频基础模型,主要用于视频多模态检索,用户可以通过输入文字、图片来寻找视频中的任意内容(text / picture to any);还推出了视频智能问答、智能分类的功能。
Twelve Labs 的愿景是成为 ChatGPT for video,目前是视频多模态搜索领域最好的产品,其最大的亮点是视频搜索效果非常准确,能够理解抽象概念,在同类中处于绝对领先的位置,客户普遍评价其搜索质量很好,搜索速度快、泛用性好。视频基础模型的壁垒很高,从优质的视频数据、处理数据的 infra、index 系统、训练方式,甚至到和芯片公司(投资方)的合作,Twelve Labs 都构建了一定的 "先发优势"。
公司自 2020 年成立以来融资超过 7,700 万美元,最新轮次是 A 轮。股东包括 Nvidia, Intel Capital,Samsung NEXT Ventures,Index Ventures,Radical Ventures 等,此外公司还吸引多位学术界、业界的知名人士投资,例如李飞飞,Silvio Savarese(斯坦福大学计算机科学副教授、Salesforce 首席科学家),Alexandr Wang( Scale AI 创始人)等。

💡 目录 💡
01 Thesis
02 Risk
03 Twelve Labs 的产品
04 视频理解技术的关键问题
05 Twelve Labs 的视频模型
06 商业模型及经营情况
07 团队成员
08 市场与竞争
09 融资历史
01.
Thesis
• 视频的存量市场巨大,而搜索需求远未被开发;另外从增量来看,视频智能问答、摘要、分类都是新的应用
根据 Sandvine 的数据,从 2021 年到 2022 年上半年,Google、Meta 的互联网流量占比分别下降 7.1%、8.7%,而 Netflix 的流量激增 4.4%。2022 年上半年视频流量占据超过 65% 的互联网流量。视频内容的需求激增说明了人们从社交平台转向更具算法个性化的视频平台的趋势,这促使非纯视频平台也在更多地嵌入视频内容。

2021 和 2022 H1 互联网流量占比前 6 大公司

2022 H1 视频流量占互联网流量超 65%
目前视频搜索市场存量很大,主要被 Netflix、YouTube、Disney+、TikTok 等视频巨头占领,前十大视频应用流量占比超过 52%。根据 Nielsen 的数据,2021 年美国成年人观看视频的时间估算达到 5 小时 21 秒,接近于每天总清醒时间的四分之一。人们每天都会消费和创建大量的视频内容,巨大的视频流量意味着对视频精准搜索、分类的需求日益显著。但与文本数据不同,视频中的信息仍然难以通过简单的 Ctrl+F 来查找。视频搜索市场能提供的不仅仅是搜索功能;它还包括了内容管理、广告投送和内容推荐,这些增值服务都能通过提高用户参与度从而促进内容消费、增加平台和内容制作者的收入来源。好的视频搜索方式能够带来巨大的用户粘性和商业价值,因此大量的视频资产就像未被采掘的金矿。

前十大视频公司
近两年的视频理解模型的发展已经证明了视频领域的模型可以真正完成理解任务,其中,Twelve Labs 自研的视频理解模型可以实现对视频的多模态搜索(即可以通过文字/图像对视频中的声、画、音、图等各种信息进行精准的搜索),在目前小规模的使用中客户已经感受到了极高的价值。如果视频多模态搜索能够被大范围应用,那么有可能是对视频应用的一次变革。
另外从增量市场上看,Twelve Labs 推出的视频理解(智能问答、摘要)、视频分类功能目前位于 0-1 的市场。是 LLM 的出现催生了视频问答这类 high-level 的视频理解能力,最快跑出来的好模型、好产品有机会快速抢占市场份额。视频智能问答、摘要可以在生产力场景提高人们工作效率,例如在工作中智能总结视频以及音频、在营销中智能生成营销的标题与标签等。视频智能分类可以在视频内容管理、视频智能剪辑的场景中加以利用。
• Twelve Labs 是目前视频多模态搜索领域最好的产品:搜索结果准确、速度快、泛用性好、产品运营能力强
Twelve Labs 最大的亮点是视频搜索效果非常准确,能够理解抽象概念,在同类中处于绝对领先的位置,客户普遍评价其搜索质量很好,搜索速度快。Twelve Labs 的客户在选择供应商时经常会比较不同的模型和方案,尽管有其它的视频搜索模型在准确度测试中能够接近 Twelve Labs,但它们基本无法做到像 Twelve Labs 这样能够理解抽象的概念(例如蒙太奇概念),它们在实际应用中的理解力远不如 Twelve Labs。有一些传统的方案视频理解能力更强,但是传统方案往往需要人工做大量的监督和标注,欠缺质量和效率的平衡。Twelve Labs 的搜索处理时间是视频原长度的 1/4,对于过往依靠传统搜索方法的客户来说,"这个速度几乎可以被认为忽略不计"。
Twelve Labs 产品强大的视频理解力背后是其训练方式的不同。与大部分同类方案的从图像开始、逐帧训练不同,Twelve Labs 的模型从视频开始训练,通过输入整秒的视频片段和使用分片技术,让模型更好地理解时间跨度内的概念。Twelve Labs 训练的单位是涉及到抽象概念的场景边界,确定场景边界后再移除冗余帧,以提高模型在捕捉空间和时间上下文方面的能力和效率。
除了理解力之外,Twelve Labs 在泛化方面也表现更强。如果客户需要训练 Twelve Labs 识别新的图像(例如特定的 logo),Twelve Labs 只需要做少量的训练即可。对比同类型的商用产品(例如 Google vision API),它们则需要客户创建模型做大量的训练。
客户普遍认为 Twelve Labs 的团队乐于沟通、积极吸收反馈、产品迭代速度快。AI 时代的公司不像互联网公司那样,依靠 "产品—用户—数据" 就能实现圈地闭环。但 Twelve Labs 作为视频理解领域第一批跑出来的公司,可以用 "先发优势—用户反馈—更好的产品" 构建自己的竞争优势。例如,公司最初是以视频嵌入模型 Marengo 为核心提供视频搜索功能,但在客户使用的过程中,公司发现用户希望产品可以提供自动为视频生成文本、视频 QA 等辅助功能,于是公司开始开发视频语言模型 Pegasus,二者实现互补,为用户提供完善的产品。
02.
Risk
• Twelve Labs 的视频搜索产品能否突破技术瓶颈率先实现大规模应用?
Twelve Labs 目前的客户群体主要是拥有中小型视频库的企业,这些企业往往需要细颗粒度地处理视频,Twelve Labs 的高质量视频搜索产品极大改善了传统方案所需的时间和成本。这类客户能够向下游客户收取相对高的溢价,因此对于 Twelve Labs 的价格敏感度较低。但据客户反馈,如何实现大规模视频搜索可能是 Twelve Labs 正在或即将面临的商业化瓶颈和技术瓶颈。
1)从商业化的角度看,如果客户的视频量再往上加几个量级,按照目前 Twelve Labs 的搜索方法成本很高,客户只有用 Twelve Labs 的产品创造更大的商业价值才能够负担这样的成本。而目前视频搜索的概念相对比较新。一些视频处理领域的企业反馈,它们的下游客户很多还在使用传统的方式管理视频、处理视频内容,因此视频搜索这个概念还没有在下游客户中有规模化的成熟盈利模式。所以 Twelve Labs 以目前的成本可能较难获得爆发式增长。我们猜测 Twelve Labs 至少是每秒存储一次向量,这样如果有超过 1 万个视频成本会非常高,可能需要每 10 秒或每 30 秒存储一次才可以达到成本和质量的平衡。客户反馈目前 Twelve Labs 可能正在开发这种灵活调整成本和质量的功能。如果他们能够提供这种功能,则有机会拿下有更多视频的客户。
2)从技术的角度看,目前 Twelve Labs 能够处理的视频数量可能面临物理意义上的限制。视频向量存储在数据库中,必须在内存中维护数据,这种方法对于可以处理视频的数量物理上的限制可能在 10,000 到 100,000 小时,这意味着无法处理超过这个数量的视频。YouTube 目前无法实现语义搜索的原因是无法真正处理超过数以亿万量级的视频量。现今主流方法都是将向量存储在数据库中。因此要解决这个问题需要在存储数据方面进行新的思考。如果 Twelve Labs 能够从基础架构或数据存储上解决可扩展性的问题,则有机会可以为像 YouTube 和 Vimeo 这样的大型视频库解决搜索问题、获得更大的市场。
• 视频多模态模型正处于 LLM 公司和 Big Tech 研发的主航道,潜在竞争风险大
在下游客户选择供应商的过程中,与 Twelve Labs 最直接的比较对象主要是 Google、Amazon 和 Microsoft 相应的视频理解模型。尽管客户认为 Twelve Labs 的产品竞争力目前胜于这些 Big Tech 的成熟商用模型,但视频以及多模态理解目前是在这些 Big Tech 以及 LLM 公司的主航道上,它们还有许多正处于 stealth 阶段、正在研发、或者是正在进行商业化的模型(例如 Google 的 Gemini Pro (1.5)、VideoCoCA 等 )。这些处于研发、商业化尝试阶段的模型暂时没有产品功能、客户群体、应用成熟度能与 Twelve Labs 匹敌的,但它们是 Twelve Labs 未来最大的潜在竞争者。
03.
Twelve Labs 的产品
Twelve Labs 的产品最核心的功能是视频搜索(Search),用户可以仅通过文字/图片输入就搜索出视频中的任何相关内容。此外,Twelve Labs 还开发了围绕视频的场景开发了不同功能:视频分类(Classify)功能可以快速对视频进行标签、分类;视频智能问答(Generate)功能可以对视频内容进行总结、摘要、问答。
Twelve Labs C 端 playground 上的
Search、Classify、Generate
Search
Search 是 Twelve Labs 最核心的产品,用户可以通过输入文字、图片来寻找视频中的任意内容——可以是画面、声音,甚至是画面中的人物、动作、文字、图片等。


Search 的使用方法非常简单,企业客户可以直接通过 API 将其与自有视频库集成;C 端用户则是在网页端上传视频或直接输入 YouTube 视频链接。从搜索效果上看,Twelve Labs 的客户们均认为目前市面上还没有完全可以与 Twelve Labs 的视频搜索比拟的产品。产品可以在视频长度 1/4 的时间内处理视频,然后实现搜索(例如 1 h 的视频需要 15 min 的等待时间)。由于搜索效果良好,因此企业客户在等待时间上忍耐度较高。
Search 产品的客户群体主要包括(1)视频网站的用户,例如 YouTube 的用户;(2)专业的视频档案库,例如美国宇航局的档案网站;(3)拥有视频素材库的企业。应用场景包括:视频网站和企业视频的内容搜索、内容审核、证据搜索、制作和编辑视频、情景广告等。
Classify
Classify 功能可将视频自动进行分类,用户可以自定义分类标签,也可以采用产品中的预定义标签。

传统的视频分类的痛点在于需要大量的人力、时间,并且依赖于固定的类别分类法(例如 YouTube 默认提供的是 15 个类别),分类效果单一,限制了用户灵活的需求。而 Twelve Labs 的多模态理解能力则可以帮助灵活拓展分类标签、快速对视频分类。
视频分类功能的最直接的应用场景是社媒个性化推荐,此外还有监控分类、视频内容管理、广告商寻找达人、体育视频分析、自动视频剪辑,语境广告(根据视频内容进行精准广告投放)等。
Generate(视频智能问答)
Generate 功能是为视频生成总结和摘要,用户也可以通过 prompt 对视频的任意内容进行提问。产品可以通过 API 支持本地云、私有云以及内部部署。其应用场景包括在工作中智能总结视频以及音频、在营销中智能生成营销的标题与标签、在实时监控中协助警方工作等。

04.
视频理解技术的
关键问题
视频的研究最开始是图像研究的拓展,传统上是通过一些数字图像信号处理方法来实现 low-level 的视频感知(如识别颜色、纹理)。2013 年以来深度学习和计算机视觉的兴起让人们开始使用 AI 来执行视频感知任务,但初期仍然局限于有限的基础任务,例如目标检测和图像分割等。
当前研究的主流是较高层次的视频理解(如识别物体、动作或事件)。视频理解的目的是让计算机像人一样“看懂”视频内容。下图给出了视频理解研究的范畴,包括视觉-语言理解和视频生成两大领域。

视频理解的研究范畴
(来源:Foundation Models for Video Understanding: A Survey)
从 2000 年到 2022 年,视频生成领域的 publication 在视频理解的研究中增长数量最多。而视频-语言理解范畴的视频检索、视频问答(QA)、视频描述的研究在 2020 年前后才逐渐涌现,目前仍处于 0-1 的商业化阶段。本文聚焦于讨论视觉-语言理解。

视频理解研究在 2000 -2022 年的发展
( 来源:Foundation Models forVideo Understanding: A Survey)
视觉-语言理解任务可以分为视频检索、视频描述、视频问答三个低、中、高层级的任务(如下图)。其主要挑战在于:1/ 视觉-语言模型架构如何效捕捉复杂的跨模态交互。视频结合了视觉和听觉信息,这涉及空间交互和时间交互两个方面。空间交互探讨物体之间的关系,而时间交互捕捉视频帧之间的顺序依赖关系。另外不同的视觉表情、肢体语言、口头语言以及视频的整体语境都会影响整体含义,因此需要多模态基础模型和各种数据源的整合,以捕捉视频的丰富性和多维性。2/ 模型训练方法如何让模型架构适应多任务、多领域。与语言模型在各行各业有许多成熟的细分应用场景不同,视频模型内容天然地涵盖多样化的内容,所以获得一个能够用于多任务、多领域的模型比特定任务的模型更有现实意义。3/ 如何有效地存储、标注、计算视频数据。视频处理与文本或图像处理相比关注度较少的一个原因在于其的高计算负担。视频的大小远大于文本或图像,计算能力问题在 Transformer 架构中尤为明显,因为 Transformer 采取的 self-attention mechanism 使得 token 长度的计算复杂度呈平方增长。
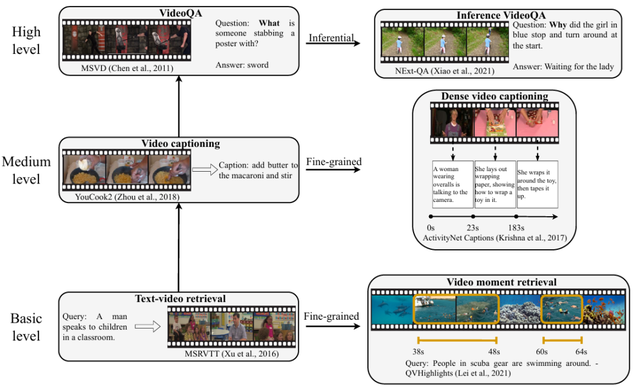
视觉-语言理解任务的低、中、高层级
( 来源:Video-Language Understanding: A Survey from Model Architecture, Model Training, and Data Perspectives)
其中,视觉-语言模型架构是最关键的问题。视觉-语言模型架构的发展大致可分为三个阶段。1/ Pre-Transformer 阶段的研究集中在如何有效融合视频和语言特征,代表性架构有单模态编码器(如 CNN、RNN);语言编码器 (如word2vec);以及跨模态编码器。2/ Transformer-based 阶段引入了 self-attention mechanism,使得模型可以高效并行处理长序列和捕捉长期依赖关系。这一阶段同样也有单模态、多模态编码器。典型的单模态编码器有如 Vision Transformer 用于视频编码、BERT 用于语言编码。但是单模态模型仅专注于单一类型数据,我们判断视频的性质使得视频理解的发展必然需要多模态模型。3/ LLM 的出现进一步了增强视觉-语言模型架构,此阶段的架构包括 LLM 作为控制器的方法和 LLM 作为输出生成器的方法。后者是主流方法,由于 LLM 在训练过程中从未见过视频,因此需要一个对齐的步骤将视频的视觉语义和 LLM 的语义对齐。
05.
Twelve Labs 的
视频模型
Twelve Labs 的 vision 是建立 video-native 的多模态视频基础模型。现阶段 Twelve Labs 的核心自研模型有两个,一个是视频基础模型 Marengo-2.6,用于执行视频搜索和分类任务。但从可以执行的任务来看这还算不上是一个通用的视频基础模型。该模型最大的特点是将视频转换为多模态视频原生嵌入,这种嵌入空间对于跨模态搜索和分类非常有用,也是 Twelve Labs 的优势所在。另一个是视频-语言模型 Pegasus1,用于执行视频智能问答任务,是视觉理解和文本理解之间的桥梁。据用户反馈,Twelve Labs 产品的优势特点在于对视频内容的理解力、可以实现多模态搜索、以及可以通过 API 实现端到端的简单集成。另外从基准测试效果上看,Twelve Labs 的准确性领先;从应用上看它还可以通过微调应用到特定领域。

除了核心模型外,Twelve Labs 平台架构中还有 Engine options 是用于处理不同类型的信息,Processing Engine 用于支持下游的 3 个核心功能:搜索、生成,和分类。
视频基础模型 Marengo-2.6:
Marengo-2.6 将视频转换为多模态视频原生嵌入,从而可以 scale up 执行任务,无需存储整个视频。Marengo-2.6 已经在大量视频数据上进行了训练,训练重点是在综合多模态数据集上进行自我监督学习。目前的训练数据集包含 6000 万个视频、5 亿张图片,和 50万段音频。模型可以识别视频中的实体、动作、模式、运动、物体、场景等多种元素。因此,Marengo-2.6 支持任意到任意的检索任务(包括文本到视频、文本到图像、文本到音频、音频到视频和图像到视频)。但目前仅提供文本/图像输入执行搜索任务,文本输入执行分类任务,公司表示未来很快会发布更广泛的基准模型。此外,模型还通过引入 Reranker 模型,增强时间定位功能,获得精确的搜索结果。

Marengo 架构
视频语言模型 Pegasus1:
目前开放的 Pegasus1 open-beta version 拥有大约 170 亿个参数( Pegasus1 alpha version 拥有大约 800 亿个参数), Pegasus1 通过将文本和视频数据整合到一个共同的嵌入空间,在视觉理解和文本理解之间架起了一座桥梁,支持从视频到文本生成的多种功能。Pegasus1 目前被用于处理视频内容上下文中生成或理解自然语言的任务,例如总结视频和回答问题。该模型集成了三个主要组件来处理和解释视频数据:
• 视频编码器模型 Video encoder model:该组件基于 Marengo 嵌入模型,将视频和音频作为输入,通过分析帧及其时间关系,输出封装了视觉、音频和语音信息的多模态视频嵌入。
• 视频语言对齐模型 Video-language alignment model: 该组件将视频编码器模型 video enconder model 生成的视频嵌入信息与文本领域对齐,确保大语言模型解释视频嵌入信息的方式与解释文本标记的方式相似。该模型输入视频嵌入,输出与视频语言对齐的嵌入。
• 大语言模型-解码器 Large language model - decoder: 该组件根据用户提供的 prompt 解释对齐的嵌入信息,并将信息解码为连贯、人类可读的文本。该模型输入视频语言对齐嵌入,用户提示;输出文本。

Pegasus 架构
06.
商业模型及经营情况
公司在成立一年多(2021 年 3 月)后,开始拥有付费客户。2023 年 6 月,公司推出了 Search API。目前已超过 2 万名开发者在使用该产品,每月 API 调用次数就已突破百万。2023 年,公司接触了 10 多个不同行业的数百家客户。客户主要有三类,一是娱乐媒体公司,它们要处理大量细颗粒度的视频;二是广告相关的公司,视频的上下文理解可以帮助他们更好地插入广告;第三是公共安全公司,它们需要智能监控服务。
因此,Twelve Labs 目前主要的客户是拥有、或需要处理中小型视频库的企业级客户。其商业模式是为开发者和企业用户提供 API,按时长收费。C 端用户亦可以在公司官网上使用产品,但不是目前主要收入来源。

产品收费模式
客户案例
• dSky.ai
dSky.ai 主要在好莱坞和媒体制作行业帮助制造电影、电视。它使用 Twelve Labs 技术帮助客户管理和快速搜索大量的视频档案。dSky.ai 评价 "Twelve Labs的价值是将视频搜索从无限长的时间缩短到无限小" 。dSky.ai 选择 Twelve Labs 的原因在于价格竞争力、技术优势(Twelve Labs的技术能够从少量训练数据中进行泛化)以及初创公司合作的灵活性。dSky.ai 每年花费约 100 万美元,Twelve Labs的费用占到了dSky.ai向客户收费的20%到40%。
• Source Digital
Source Digital 是一家内容增强公司,通过为视频标注人物和产品,分辨视频的最佳广告位。使用 Twelve Labs 每月花费约 1 万美元,使用后视频购物广告用户点击次数增加了 3 倍。公司评价 "Twelve Labs 在视频搜索有 97% 的准确率,而同类的Google video AI 只有40-50%" ,但是公司认为 "Twelve Labs 的收费太贵,不是所有下游客户都需要使用。"
• MindProber
MindProber 记录用户观看电视过程中的生理数据,为广告商提供最佳广告插放位置。公司利用 Twelve Labs 技术检测视频中的 logo 并标记用户生理数据。公司评价 "相比于Google Vision API,Twelve Labs 的泛用性更强,性价比更高,可以开箱即用。" 公司认为其传统替代方案(如LogoGrab)的精度更好但是需要非常多人工干预,精度和速度无法平衡。
• Virtulley
Virtulley 为企业组织远程活动,使用 Twelve Labs 提供的视频搜索和分析服务记录参与者反应,通过参与者的反馈提高活动质量,并剪辑精彩片段。每月花费在 7000~8000 美元之间。公司认为 "Twelve Labs收费较高,但其视频搜索和分析功能吸引力很大。"
媒体领域的经营合作情况
媒体制作公司是 Twelve Labs 目前占比较大的客户群体。在媒体制作中,快速找到理想的视频内容至关重要。传统上,媒体资产依赖手动打标签管理或元数据搜索,存在准确性和可扩展性问题。

示例 : 传统上,使用元数据搜索
( 来源:MediaCentral 产品 )
因此 Twelve Labs 的技术在媒体和娱乐领域有广泛应用,例如优化视频资产归档、管理和制作流程。语义搜索功能可以根据用户的搜索提供推荐,让视频编辑者接触到他们可能没有考虑过的潜在相关内容,在加快工作流程的同时激发新的创意。另外还能应用在通过个性化推荐提高用户参与度、识别最佳广告机会等。

MediaCentral 中的推荐引擎示例
( 来源:MediaCentral 产品 )
Twelve Labs 正在积极拓展与媒体资产管理(MAM)提供商产品的集成,以提高用户的视频处理体验。例如:与 Blackbird (AIM:BIRD) 的云原生视频编辑平台合作,将产品作为插件集成到其平台中,提升视频编辑效率;与媒体资产管理和工作流程自动化解决方案公司 EMAM 合作,将产品集成到其平台中。与大数据传输服务公司 MASV合作,简化视频处理,提升生产和编辑效率。与 CineSys 的视频播放平台合作,简化后期视频制作流程。与社交媒体数据分析 Phyllo合作,实现视频内容的高效搜索和详细分析,从而优化营销策略。

Twelve Labs 与数字化转型公司 Arvato 合作,让体育行业的客户可以用自然语言搜索准确视频内容
07.
团队成员

创始团队
2021 年 3 月,CEO 和四位联合创始人一起创办了公司。目前团队大约 80 多人。
CEO Jae Lee 出生在首尔,在 10 来岁的时候随着在田纳西大学攻读统计学博士的叔叔来到了美国,从小接触了许多统计学的方法,11 岁就开始学习 Matlab,后来独自留在在美国继续自己对统计学和计算机科学的研究兴趣以及学业。Jae 和 Aiden Lee、Sungjun Kim 是一起在韩国军队(韩国国防部的 R.O.K Cyber Operations Command 部门)作战的战友,他们在军队中一起做了很多视频的底层研究,热衷于打造智能系统,做了许多多模态视频理解的研究。他们曾想在学术界发展,但是他们想做的研究的产品需要大规模的数据,于是一拍即合一起创业。Jae 和另一位联合创始人 Soyoung Lee 是十几年的老朋友,Soyoung 喜欢和开发者交流、喜欢技术。
我们认为 Twelve Labs 的核心团队是视频理解赛道上的一个比较好的团队。1/ 前面我们已经分析,视频理解模型的大规模商业化需要在基础研究上有大的突破。尽管从团队的学术背景上看 Twelve Labs 不是该领域的最强团队,但从已取得的模型效果上看是处于领先位置,未来的关键在于能否在基础研究上持续取得突破。2/ 作为前沿领域的 AI 公司,Twelve Labs 需要在工程上能够快速迭代、快速测试不同的想法,并且在获得实验结果后快速部署,才能持续保持竞争优势。Twelve Labs 的团队在工程能力上较强,团队项目经验丰富。2021 年,公司在 Microsoft 主办的 ICCV VALUE 挑战赛中一举成名,以优异的成本、性能在腾讯、百度等对手中名列前茅。此次比赛是 Twelve Labs 高速成长的推进器,为公司吸引来了来自 Index Ventures 的第一笔种子轮投资,随后飞速成长、建立声誉。3/ 产品力和运营能力也是新型领域公司商业化的关键。客户普遍反馈 Twelve Labs 的团队沟通积极、能够及时响应反馈和调整产品。例如,视频生成文本的功能(视频语言模型 Pegasus1)正是在客户的强烈要求下推出的,为客户实现与视频搜索相辅相成的功能。

08.
市场与竞争
目前的视频搜索市场
VerifiedMarket 估计 2023 年视频搜索的市场规模大约在 283 亿美金,这部分的市场主要来自于 "传统" 玩家,它们利用自然语言处理、计算机视觉、机器学习和数据分析等技术的组合提供搜索算法,这些算法能够根据用户查询或偏好来理解、索引和检索视频内容,主要服务于安全和监控、智能家居、视频管理等行业。玩家有如 Agent Vi、Genetec、Verkada、Vivint、Bosch (Bosch Sicherheitssysteme)、BriefCam、Identiv等。下面列举了几家公司的情况:
• Agent Vi:一家企业视频分析软件公司,主要用于安全领域的监控和保证,其视频搜索功能包括高级视频分析和搜索功能。该公司被 Livly 以 6,750 万美元的价格收购。
• Genetec:一家安全系统领域的公司,提供视频监控、访问控制和自动车牌识别等解决方案。年收入约为 5 亿美元。
• Verkada:一家基于云的 B2B 物理安全平台公司,其中视频安全摄像头是核心产品之一,提供视频搜索和分析功能。2016 年成立以来融资超过 4.4 亿美元。
• Vivint:Vivint 提供智能家居自动化和视频监控解决方案,其视频搜索功能集成于智能家居系统中。市值约 25 亿美元,年收入约 16.8 亿美元。
这些 "传统" 玩家提供终端的视频解决方案,提供特定领域的视频产品,但视频搜索、视频分析是其产品的一项核心功能。所以这部分市场并不是 Twelve Labs 直接对标的市场,而更有可能是 Twelve Labs 的下游市场。市场上在做视频搜索领域基础模型的人相对较少,但这方面有大量的 use case,例如上述的监控领域,还有医疗保健、教育、娱乐、工业方面的 use case。
Twelve Labs 的直接竞争者
在客户选择供应商的过程中,最直接的比较对象来自三大 Big Tech,例如有 Microsoft Azure video services(已关停)、Microsoft Azure AI Video Indexer、Amazon Rekognition、Google Video Intellignce、Google Vision API。据用户反馈:Microsoft Azure video services 定价最低但是产品力欠缺;Google Video Intellignce 的准确率不如 Twelve Labs(Twelve Labs 在视频搜索有97%的准确率,Google video AI 只有40-50%);相比与 Google Vision API,Twelve Labs 更加开箱即用,并且泛用性更强,需要的训练数据远小于Google Vision API。除了 Big Tech 外,一些传统的视频搜索方案也是竞争对象,例如 LogoGrab 的精度更好但是需要非常多人工干预,精度和速度无法平衡。
从 startup 的角度来说,暂时并未 mapping 到产品功能和客户群体相似度高的 startup,最相近的是 Gloss AI,其次是细分场景的 comp,具体如下:

此外,对客户而言,Twelve Labs 的替代方案主要是自行构建视频搜索系统,这需要大量的工程投入和时间。具体过程包括使用视频转录服务将视频转换为嵌入数据,然后使用 Pinecone、Vectra 或 Perplexity AI 等工具(或开源工具如 FAISS 和 Annoy)进行数据存储和搜索。虽然这种方法是可行的,但确实需要耗费大量的工程资源和时间。
Twelve Labs 的潜在竞争者
Twelve Labs 最大的风险来自于 Big Tech 正在研发、而未进入成熟商业阶段的模型。Big Tech 在多模态模型的研究范围很广,从 Twelve Labs 的三个主要业务:Search、Generate(视频智能问答)、Classify 来看,Big Tech 各有相应的可比/功能相似的模型。由于模型众多,我们从客户访谈以及公司主要对比的 benchmark 中选取了重要对比模型,例如(1)搜索方面有 Google 的 Gemini Pro (1.5)、VideoCoCA、 Vid2Seq、VATT;北大和腾讯合作的 LanguageBind 等。(2)视频问答方面有 Google 的 Gemini Pro (1.5);Allen AI 研究所的 MERLOT Reserve;以及 Video-ChatGPT、VideoChat2 等。(3)视频标记、内容推荐、搜索推荐领域则有 YouTube、Spotify 多年深耕其中、应用成熟。
虽然功能相似的模型很多,Twelve Labs 和 Big Tech 的区别主要在于:1/ 从较高的层次来看,Big Tech 主要聚焦的是多模态的研究,只是其中必然或多或少涉及到视频检索或生成,但他们并不是直接针对视频搜索、生成的市场,所以视频搜索、生成只是其研究中的一个小部分,或者只是一个小测试。从目前客户的反馈上看我们认为这些处于研发阶段的模型没有产品功能、客户群体、应用成熟度能与 Twelve Labs 同步的。2/ Twelve Labs 在不同的访谈中都有提到,公司长远的愿景的让 AI 像人类一样理解世界,而公司采取的第一步是 "视频优先" 的策略。所以我们可以认为,Big Tech 和 Twelve Labs 长远的 vision 是相似的,不过 Big Tech 的研究 "全面覆盖" 的,而 Twelve labs 的策略是 "以点破面" 的。当然这也与其商业位置有关,Big Tech 也许并不着急商业化,而作为初创的Twelve Labs需要先做出产品生存立足,再往大的vision 发展。3/ 在视频搜索中,建立索引和搜索的成本/时间占比大约 8:2,因此建立索引的技术路径是不同多模态模型的主要区别,相应的策略和技术有很多种路径。4/ 从公司公布的模型测试上来看,Twelve Labs 模型在三个核心产品对应的任务上,其性能优于主要的可比模型。

Search、Generate、Classify 产品的可比模型
09.
融资历史
公司于 2020 年成立。至今融资超过 8700 万美元,最新轮次是 A 轮,由 NEA 和 Nvidia 领投(公司是 NV 投的第一个韩国的初创公司)。公司股东还包括 Intel Capital,Samsung NEXT Ventures,Index Ventures,Radical Ventures,Korea Investment Partners 等,此外公司还吸引多位学术界、业界的知名人士投资,例如李飞飞,Alexandr Wang(Scale AI 创始人)等。

团队与投资人

融资历史
**本文仅作为科普分享及学习资料,不构成任何投资建议或金融产品推荐,并且及不应被视为邀约、招揽、邀请、建议买卖任何投资产品或投资决策之依据,文中所涉及的分析、观点及结论均为作者基于公开信息的研究和主观判断,不代表任何投资机构或金融机构的官方立场,亦不应被诠释为专业意见。投资有风险,入市需谨慎。**


排版:Doro
答 AI 的 6000 亿美元问题:LLM 应用会如何崛起?|AGIX 投什么
Perplexity:并不想替代Google,搜索的未来是知识发现
AI是如何重塑软件公司的?|AGIX投什么
Voice Agent:AI 时代的交互界面,下一代 SaaS 入口
为什么我们相信英伟达能到 5 万亿|AGIX 投什么
