在快速发展的人工智能领域,ViTs已成为各种计算机视觉任务的基础模型。ViTs通过将图像划分为小块并将这些小块作为标记来处理图像。6月刚发布一篇论文,引入了一种新颖的方法,即像素级Transformers,它通过将单个像素视为令牌来挑战这种范式。本文将讨论Pixel Transformer的复杂性,创新方法,以及它对人工智能和计算机视觉未来的重要影响。

ViTs已经彻底改变了我们处理图像处理任务的方式。通过利用自注意机制,vit可以捕获图像不同部分之间的远程依赖关系和交互。传统的vit将图像分解为固定大小的小块(例如,16×16像素),并使用这些小块作为输入令牌。这种方法已经在各种应用中被证明是成功的,但是它固有地假设了局部偏置:相邻像素比远的像素更相关。
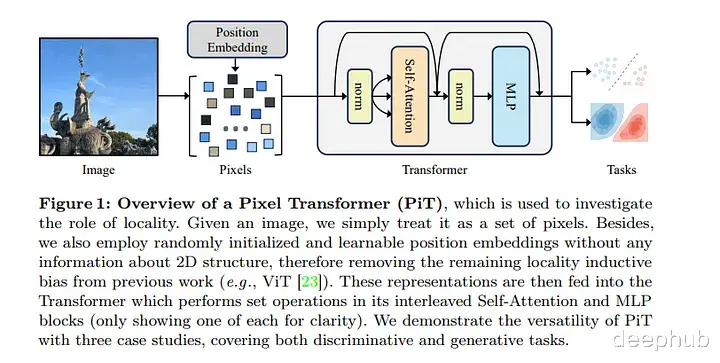
Pixel TransformerMeta AI和阿姆斯特丹大学的研究人员在论文《An Image is Worth More Than 16×16 Patches: Exploring Transformers on Individual Pixels》中提出了Pixel Transformer,将每个像素视为单独的令牌。这种方法挑战了局部偏置的必要性,为视觉变换开辟了新的可能性。
1、局部偏置
Pixel Transformer的主要创新是完全消除了局部偏置。传统的vit假设像素的空间接近度与它们彼此的相关性相关。而Pixel Transformer证明了这种假设并不总是必要的。通过将每个像素视为一个单独的标记,模型可以捕获任何像素之间的关系,而不管它们的空间距离如何。

2、跨任务的通用性
Pixel Transformer在多个任务中进行了严格的测试,包括监督学习、自监督学习和图像生成。在监督学习中,与传统的vit相比,Pixel Transformer的准确性有了显著提高。例如,在Acc@1上,PiT-T (Pixel Transformer的一种变体)比ImageNet上的vit提高了1.5%,而在小型模型上,PiT-S提高了1.3%。
3、增强分类性能
Pixel Transformer的一个突出应用是分类任务。通过将单个像素视为标记,该模型可以在CIFAR-100和ImageNet等数据集上获得更好的结果。这种改进的性能归功于模型捕获细粒度细节和复杂模式的能力,这些细节和复杂模式在使用更大的补丁时可能会丢失。
4、优越的图像生成
Pixel Transformer在图像生成任务方面也表现出色。在VQGAN的实验中,Pixel Transformer的性能优于标准ViTs,证明了其生成高质量图像的能力。消除局部偏置使模型能够更好地理解和重建复杂的视觉结构。
测试结果指标以下是论文的一些关键结果指标:
在固定输入大小的ImageNet上,PiT达到了80.3%的准确率,即使没有局部偏置,也显示出其具有竞争力的性能。
CIFAR-100:在CIFAR-100上,Pixel Transformer的表现优于传统的vit,突出了其在不同数据集上的鲁棒性。
VQGAN实验:在使用VQGAN的图像生成任务中,像素转换器显示出卓越的质量,表明其具有创造性和生成性应用的潜力。

1、为什么作者选择探索在单个像素上使用Transformer,而不是继续使用传统的16x16像素块?
作者选择在单个像素上探索使用Transformer主要是为了质疑并测试在现代计算视觉架构中“局部性”这一归纳偏置的必要性。这种探索基于以下几个原因和动机:
检验归纳偏置的限制:传统的ViT(如Vision Transformer)通常采用16x16像素块作为输入单元,这种做法继承了卷积神经网络(ConvNets)对局部像素邻域的偏好。通过将每个像素单独作为令牌输入,作者可以彻底去除这种局部性偏置,进而测试模型在完全不同的输入处理方式下的表现,从而评估局部性偏置在视觉处理任务中的真实作用和重要性。
探索模型的泛化能力:通过摒弃常规的16x16像素块,使用单个像素作为输入,可以检验模型在没有预设空间关系偏置的情况下,是否能够从数据中自主学习和发现有效的视觉表示。这种方法可以帮助理解模型如何处理和组织视觉信息,并探索新的方法来提升模型的泛化能力。
挑战和推动技术边界:将每个像素单独作为输入令牌,可以极大地增加模型处理的复杂度和挑战性,从而推动相关技术的进步。这包括优化模型架构、提升计算效率和开发新的训练技术等,这些都是推动深度学习技术前进的重要因素。
实验性研究:此项研究具有很强的实验性质,意在打破常规,探索和验证新的假设。通过实验验证单像素输入的效果,研究者可以获得有关信息处理和模型设计的新见解,这些见解可能会影响未来计算视觉模型的开发方向。
总的来说,作者通过这种探索性的研究,不仅挑战了传统的视觉处理模型设计,还为理解和改进深度学习模型在处理图像时的内在机制提供了新的视角和数据支持。这有助于推动计算视觉领域的理论和实践发展。
2、如何解决处理单个像素时序列长度大幅增加导致的计算问题
虽然作者指出将每个像素直接作为令牌导致序列长度大幅增加,这会增加计算负担(尤其是因为自注意力机制需要处理的序列长度呈平方增长),但他们实际上并没有完全解决这一计算问题。文章中提到,尽管直接处理单个像素的方法在理论上是可行的,并且可以带来良好的性能,但从计算的角度来看,这种方法并不实用。这主要是因为自注意力操作需要的计算资源随着输入序列长度的增加而显著增加。
不过,作者确实提出了几点可能的方向来应对这一挑战,以便为未来的研究提供线索:
硬件和算法优化:随着硬件能力的提升和算法优化技术的发展,未来可能能够更高效地处理更长的序列。例如,优化的矩阵乘法操作、更有效的并行计算策略等。
近似技术:使用近似计算方法来减少自注意力机制的计算需求。例如,稀疏性技术、低秩近似或利用局部敏感哈希等技术来降低复杂度。
分层注意力:实现一种分层的注意力机制,通过在较低的分辨率上首先处理图像,逐渐增加细节层次,这样可以减少在高分辨率时处理每个像素所需的计算负担。
虽然这些方案为处理长序列提供了理论上的可能性,但实际应用中还需要进一步的工程实现和优化。这篇论文更多地强调了将单个像素作为令牌的潜在价值,并指出这种方法可以为未来研究提供新的方向,即探索减少或去除归纳偏置在视觉模型中的作用。
3、实际意义
Pixel Transformer的成功挑战了局部偏置对视觉模型至关重要的传统观念。这种模式的转变可能会导致更多功能和更有能力的神经架构的发展,而不受固定大小补丁的限制。
通过将每个像素视为令牌,Pixel Transformer在处理各种图像分辨率和长宽比方面提供了增强的灵活性。这种灵活性在图像大小和形状差异很大的应用程序中是有益的。
由于Transformer本身的模态不可知性,将单个像素作为输入的成功可能进一步激励研究者探索Transformer在其他类型数据(如文本、声音)上的应用,进而推动跨模态学习和通用人工智能的发展。
总结Pixel Transformer通过挑战局部偏置的必要性并将单个像素视为标记,这种新方法在一系列任务中展示了卓越的性能。这项研究的意义超越了传统的图像处理,为人工智能和计算机视觉提供了新的可能性。
随着我们不断突破人工智能的极限,Pixel Transformer提醒我们,创新往往需要重新思考既定的惯例。通过接受新思想,探索未知领域,我们可以释放人工智能的全部潜力,推动无数领域的进步。
论文地址
https://avoid.overfit.cn/post/558881d4b25b4e9e944806441eaf887a
