全文约1500字;
阅读时间:约5分钟;
听完时间:约8分钟;

分享一个人力资源部门专员在整理员工档案时遇到的地址信息处理问题。具体情景是在整理工厂员工档案的过程中,领导提出需求,要求从员工住址的详细信息中单独提取出门牌号。
例如,将地址“和平路万和瑞景小区12-3-501”分为两部分,分别填入两个单元格:“和平路万和瑞景小区”和“12-3-501”。鉴于员工数量庞大,手动完成这一任务极为耗时。因此,亟需设计一个自动化公式,实现快速一键分离地址信息的功能。
 需求分析
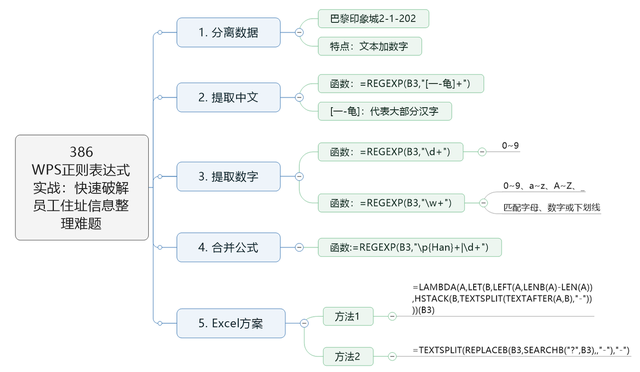
需求分析针对从单元格内容中快速分离特定信息的需求,最优解是运用WPS最新版的正则表达式函数REGEXP进行拆分。观察B列的地址信息,可以发现地址由三部分组成:文字描述、数字以及连接符“-”。对于这类结构规律明显的地址信息,正则表达式特别适合用来分别捕获中文字符与数字序列,从而实现精准分离。
对于Excel用户,若不具备正则表达式功能,可以通过组合使用LENB和LEN函数先估算出文本的长度,进而利用LEFT函数来提取中文部分。至于数字识别,可以采用TEXTAFTER函数处理地址后的数据以获取。最后,利用FIND函数定位连接符“-”的位置,并结合MID或新版Excel中的TEXTSPLIT函数来分割楼号、单元号和门牌号,以此达到分离目的。
 提取中文
提取中文为了便于大家理解,我将正则表达式的应用拆解说明。首先,我们使用正则表达式来单独提取文本部分。在单元格中输入以下函数之一: 函数A:
=REGEXP(B3, "\p{Han}+")
或者
函数B:
=REGEXP(B3, "[一-龟]+")
函数解释:
这两个函数都是作用于B3单元格的内容,旨在抽取出其中的中文文本。它们将返回如“和平路万和瑞景小区”这样的结果。其中,\p{Han}匹配任何中文字符,而[一-龟]+范围表达式匹配从“一”到“龟”之间的所有汉字(涵盖了大部分常用汉字),加号+表示匹配一个或多个这样的字符。这样,就能有效地从地址中提取出所需的中文文本部分。
效果如下图所示:
 提取数字
提取数字随后,我们需要提取由“-”分隔的楼号、单元号及门牌号,这些皆为相连的数字序列。为此,仅需专注于提取数字信息。请在单元格中尝试以下任一函数:
函数A:
=REGEXP(B3, "\d+")
或者
函数B:
=REGEXP(B3, "\w+")
函数解释:
这两个函数均应用于B3单元格的数据,目标是从中抓取数字序列。
函数A \d+ 正则表达式匹配一个或多个数字(0-9),适用于直接获取连续的数字串,即楼号、单元号和门牌号。
而函数B \w+ 通常用于匹配字母、数字或下划线,但由于我们的目标明确为数字,使用\d+更为精确。但在此列出作为备选,因为它也能捕获数字,尽管可能在某些特殊字符存在时不够精确。
通过这些函数,我们可以获得紧随中文地址后的数字部分,进一步处理即可分离出具体的楼号、单元号和门牌号。
效果如下图所示:
 合并提取
合并提取在成功提取了文本和数字之后,可以采用一个综合公式来实现“一键分离”所有所需信息。请在单元格中输入以下函数,并向下填充至相应行: =REGEXP(B3,"\p{Han}+|\d+")
函数解释:
上述正则表达式旨在同时识别并分离文本与数字内容。这里的关键在于使用了 alternation(选择) 符号 |,意味着其能匹配两种模式之一:\p{Han}+ 用于捕获一个或多个连续的中文字符,而 \d+ 则匹配一个或多个连续的数字。因此,该表达式能够识别出地址中的中文部分以及所有数字序列,
效果如下图所示:

如果您倾向于避免逐个单元格填充公式,可以采用数组公式的方式一次性处理范围内的数据。请尝试以下函数:
录入以下函数:
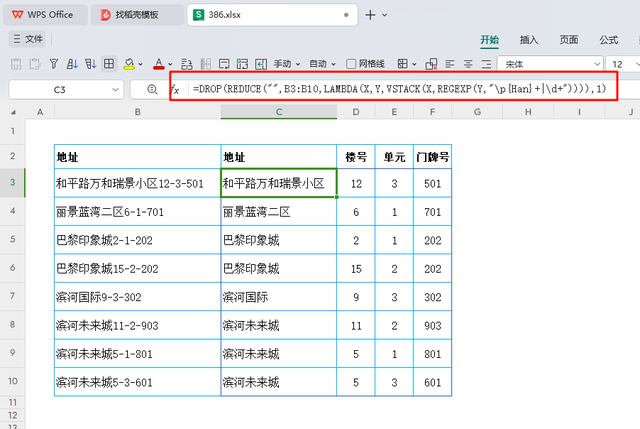
=DROP(REDUCE("",B3:B10,LAMBDA(X,Y,VSTACK(X,REGEXP(Y,"\p{Han}+|\d+")))),1)
效果如下图所示:
 Excel方案
Excel方案对于Excel用户来说,没有正则表达式函数,可以采取以下方法进行分列提取。
录入以下函数并填充:
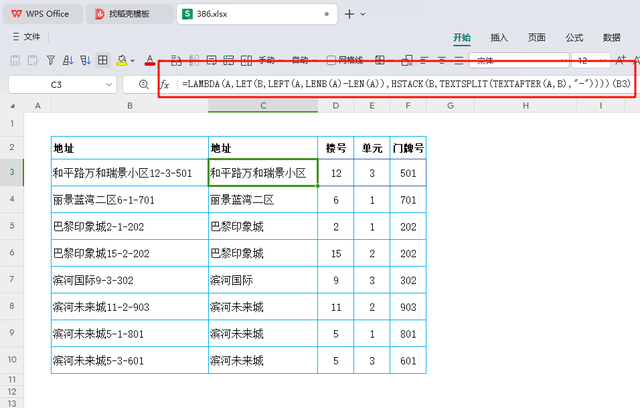
=LAMBDA(A,LET(B,LEFT(A,LENB(A)-LEN(A)),HSTACK(B,TEXTSPLIT(TEXTAFTER(A,B),"-"))))(B3)
函数解释:
此公式通过定义一个LAMBDA函数,以单元格B3中的地址为起点(标记为A),执行以下步骤:
计算文本长度:首先,利用LENB与LEN函数的差值确定纯文本(不包括汉字占的双字节)的长度,以此截取地址中的中文文本部分。
提取并分割数字部分:使用TEXTAFTER函数从原地址中提取出紧跟在中文文本后的部分(即数字和连接符)。然后,通过TEXTSPLIT函数依据“-”将这部分内容分割成不同的单元,代表楼号、单元号和门牌号。
合并结果:最后,利用HSTACK水平堆叠起原始的中文文本部分和刚刚分割得到的数字序列,完成信息的分离。
此方法有效绕过了正则表达式的限制,依然实现了从地址数据中自动分离中文描述与数字编码的功能,直观展现了“和平路万和瑞景小区”与“12-3-501”等信息的分隔效果。
效果如下图所示:
 最后总结:
最后总结:综上所述,无论是借助WPS中强大的REGEXP函数还是通过Excel的巧妙函数组合,我们都能高效地解决人力资源部门在处理大量员工地址信息时面临的分离门牌号需求。正则表达式以其灵活性直接提供了文本与数字的精准切割方案,而Excel的多步骤函数应用则展示了在不具备正则功能条件下的变通之道,同样实现了自动化处理的目标。
这些方法不仅显著提高了工作效率,减少了人工操作的繁琐与潜在错误,还体现了数据分析工具在实际工作场景中的强大应用潜力。通过简单的公式配置,即便是复杂的地址信息也得以迅速结构化,便于后续的档案管理和数据分析工作。
值得注意的是,随着Excel新版本对TEXTSPLIT等高级文本处理函数的支持,即使在不依赖正则表达式的情况下,Excel用户也能享受到更加便捷的数据处理体验。这为不同技能水平的办公软件用户都开启了通往高效数据处理的大门,确保在面对大数据量处理任务时,每个人都能找到适合自己的解决方案。
总之,通过本次实践,我们不仅解决了具体的人事档案整理问题,更重要的是,揭示了在现代办公环境中灵活运用技术工具的重要性,以及不断探索创新方法以应对日常挑战的精神。这些技能的掌握,无疑将对提升个人和组织的生产力产生深远影响。