本篇为InfoQ中文站供稿
原文链接:https://www.infoq.cn/article/NHSAAmN*MfpLiTiTTEu5?from=timeline&isappinstalled=0
ShardingSphere 是什么?ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(规划中)这 3 款相互独立的产品组成。他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、容器、云原生等各种多样化的应用场景。ShardingShpere 在刚刚过去的双十一之前通过了 Apache 基金会的投票,正式进入孵化器,成为 Apache 的首个分布式数据库中间件。ShardingSphere 可以采用混合使用 Sharding-JDBC 和 Sharding-Proxy 的部署方式满足在线 + 管理的能力,也可以独立使用 Sharding-JDBC 或 Sharding-Proxy。ShardingSphere 希望可以通过多元化的接入端架构去满足不同需求。
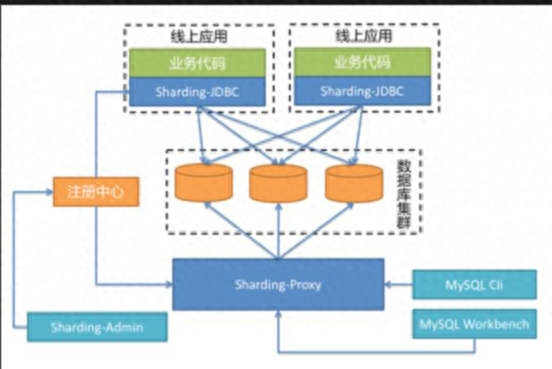 Vitess 是什么?
Vitess 是什么?Vitess源起于 Youtube,现已属于 PlanetScale 的开源产品。它致力于部署、扩展和管理大型 MySQL 实例集群的数据库解决方案。它结合了许多重要的 MySQL 功能和 NoSQL 数据库的可扩展性,提供数据分片、分布式事务以及管理大量 MySQL 实例等功能。

Vitess 由负责元数据存储的 Topology、负责应用接入和 SQL 路由的 vtgate、负责重写和执行 SQL 的 vttablet 以及两类管理工具 vtctl(用于命令行) 和 vtctld(用于图形界面) 等服务组件共同构成。用户可以通过支持 MySQL 协议的客户端,或使用 Vitess 的客户端 API 使用 Vitess。
应用功能对比面对这两个同样优秀的产品,用户该在何种场景下选用哪款产品,想必有所纠结。本文接下来将使用 Vitess v2.2 和 ShardingSphere 3.0.0,从应用功能和管理功能的角度,以官方文档为基础,进行测试对比,尽可能展示出两者在已有功能和实现思路侧重点上的不同。
接入方式Vitess 通过组件 vtgate 作为中心化的接入代理,用户可以通过 Vitess 的 gRPC 连接器或各类 MySQL 原生驱动进行连接。Vitess 的 gRPC 连接器目前仅支持 Java 和 Go 两种语言,若使用原生驱动则没有语言限制,目前 Vitess 支持 MySQL 和 MariaDB 两种数据库。ShardingSphere 提供 Proxy 和 JDBC 两种接入方式,其中 Sharding-Proxy 和 vtgate 类似,提供了中心化的接入代理,用户可以通过 MySQL 原生驱动进行连接,理论上支持所有开发语言,目前同样支持 MySQL 和 MariaDB 数据库;Sharding-JDBC 可理解为增强版的 JDBC 驱动,提供无中心化的轻量级运行方式,让客户端直连数据库,无网络二次转发的消耗。由于是 JDBC 的增强,因此没有数据库类型的限制,可以支持 MySQL、Oracle、SQLServer 和 PostgreSQL 等。通过表格,可以更直观的比较双方的接入方式区别:
Vitess
Sharding-Proxy
Sharding-JDBC
中心化
是
是
否
静态入口
有
有
无
异构语言
原生驱动任意 gRPC 仅 Java 和 Go
任意
仅 Java
数据库
MySQL 和 MariaDB
MySQL 和 MariaDB
任意
分片模式Vitess 在分片上采用了每个数据库实例均创建一个分库,并且不进行分表的方式,即多实例单库单表。由于 Vitess 的分片模式相对固定,因此在配置分片时通过 JSON 指定分片表、分片字段和分片算法,分片之后的库名由 Vitess 自动管理,表名不变。ShardingSphere 支持单独分库、单独分表和同时分库分表的分片方式,并且提供四种不同的分片策略以及能够让用户自行实现分片算法,使得用户能够更加自由地控制数据分片。单纯描述有些抽象,接下来分别创建一个分片的例子进行测试.首先模仿 Vitess 官方文档的测试用例,创建了一个名为 testkeyspace 的键空间(keyspaces),为其设置了 2 个分片。同时指定了 t_order 和 t_order_item 两张分表,分别使用 user_id 和 order_id 进行 Hash 分片。在建表完毕后,通过 DataGrip 客户端分别连接 vtgate 和实际 MySQL 实例进行查看。vtgate 执行 show databases 和 show tables。

MySQL 实例中的拓扑结构如下图。
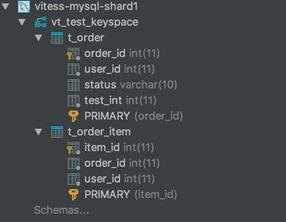
从 MySQL 实例的拓扑看出,Vitess 在每一个分片数据库实例中,都创建了一个 vt${keyspace_name}的库,并且将建表语句广播到所有数据库执行。同样模仿 ShardingSphere 的官方样例,在 Sharding-Proxy 中配置 test_keyspace 分库及 t_order,t_order_item 两张分表。为了区别 ShardingSphere 和 Vitess 的分片能力,这里选用同时分库分表的方式进行分片,通过 user_id 取余进行分库、order_id 取余进行分表。在进行配置的时候,可以利用 InlineShardingStrategy 直接使用 Groovy 表达式简化配置,如本例中可简化配置为:
test_keyspace_${user_id % 2}t_order_${order_id % 2}t_order_item_${order_id % 2}在建表完毕后,通过 DataGrip 客户端分别连接 Sharding-Proxy 和实际 MySQL 实例进行查看。Sharding-Proxy 执行 show databases 和 show tables:

MySQL 实例中的拓扑结构:

同样通过表格,直观的展示两者分片上的区别:
Vitess
ShardingSphere
分库
支持
支持
分表
不支持
支持
分库 + 分表
不支持
支持
配置方式
JSON
Groovy 或实现接口
多 Schema 切换
支持
支持
由此可见,ShardingSphere 和 Vitess 在分片模式上有着很大的区别,ShardingSphere 具有更丰富更自由的分片方式,能够应付更多的应用场景。
SQL 支持由于 SQL 语法灵活复杂,分布式数据库和单机数据库的查询场景又不完全相同,难免有和单机数据库不兼容的 SQL 出现。针对该问题,Vitess 和 ShardingSphere 都在官方文档中进行了说明。在 ShardingSphere 中,对于已支持和未支持的 SQL 种类作出了明确的标注,对于常用的分页、排序、分组、聚合都进行了支持,并支持部分关联查询,具体内容可以通过官方文档 使用规范 > SQL 中进行查阅。而 Vitess 暂时没有明确的文档标明已支持和未支持的 SQL 种类,只在 FAQ 中的test-case标注了当前已经出现的未支持的 SQL 的情况。为了更直观地展示两者 SQL 支持情况,这里选取了一部分常用的 SQL 类型,根据文档说明并结合实际测试结果,列出参考列表:
SQL 类型
测试 SQL
Vitess
ShardingSphere
全表查询
SELECT * FROM t_order;
支持
支持
等值查询
SELECT FROM t_order WHERE user_id = 7;SELECT FROM t_order WHERE user_id = 7 and order_id=9;
支持
支持
范围查询
SELECT FROM t_order WHERE user_id in (7, 9);SELECT FROM t_order WHERE user_id BETWEEN 7 AND 10;SELECT FROM t_order WHERE user_id=7 or user_id=11;SELECT FROM t_order WHERE user_id > 1;
支持
支持
累加聚合
SELECT count(*) FROM t_order; SELECT sum(user_id) FROM t_order;
支持
支持
比较聚合
SELECT max(user_id) FROM t_order;SELECT min(user_id) FROM t_order;
支持
支持
平均聚合
SELECT avg(order_id) FROM t_order;
不支持
支持
分组
SELECT user_id, MAX(order_id) FROM t_order GROUP BY user_id;SELECT sum(user_id), order_id FROM t_order GROUP BY order_id;SELECT sum(user_id), test_int FROM t_order GROUP BY test_int;SELECT count(order_id), status FROM t_order GROUP BY status; (status 为 VARCHAR 类型)
前 3 句支持 第 4 句不支持
支持
排序 / 分页
SELECT FROM t_order ORDER BY user_id;SELECT FROM t_order ORDER BY user_id LIMIT 10, 10;
不支持
支持
去重
SELECT DISTINCT test_int FROM t_order;
支持
不支持
算式
SELECT * FROM t_order WHERE user_id=7+1;
支持
支持
关联查询
SELECT a.user_id, a.order_id, a.status, b.item_id FROM t_order a JOIN t_order_item b ON a.order_id = b.order_id;SELECT a.user_id, a.test_int, a.status, b.item_id, b.user_id FROM t_order a JOIN t_order_item b ON a.test_int = b.user_id;
支持
支持
子查询
SELECT x.user_id,x.status,x.item_id FROM (SELECT a.user_id, a.order_id, a.status, b.item_id FROM t_order a JOIN t_order_item b ON a.order_id = b.order_id) x;SELECT count(x.item_id) FROM (SELECT a.user_id, a.order_id, a.status, b.item_id FROM t_order a JOIN t_order_item b ON a.order_id = b.order_id) x;SELECT * FROM t_order WHERE test_int in (SELECT test_int FROM t_order);
第 1 句支持 后 2 句不支持
前 2 句支持 第 3 句不支持
UNION
SELECT user_id, order_id, status FROM t_order UNION ALL SELECT item_id, order_id, user_id FROM t_order_item
不支持
不支持
INSERT
INSERT INTO t_order (order_id, user_id, status, test_int) VALUES (1000, 1, “INIT”, 1);INSERT INTO t_order (order_id, user_id, status, test_int) VALUES (1001, 2, “INIT”, 2), (1002, 3, “INIT”, 3);
支持
支持
无列名 INSERT
INSERT INTO t_order VALUES (1000, 1, “INIT”, 1);
不支持
支持
DELETE
DELETE FROM t_order WHERE user_id=1;
(条件有分片键) DELETE FROM t_order WHERE test_int=1;(条件无分片键)
支持
支持
UPDATE
UPDATE t_order SET test_int=1 WHERE user_id=0;
支持
支持
分片键 UPDATE
UPDATE t_order SET user_id=1 WHERE user_id=0;
不支持
不支持
CREATE
CREATE TABLE messages (page BIGINT(20) UNSIGNED,time_created_ns BIGINT(20) UNSIGNED,message VARCHAR(10000),PRIMARY KEY (page, time_created_ns)) ENGINE=InnoDB
支持
支持
ALTER
ALTER TABLE messages ADD COLUMN status VARCHAR(50);
支持
支持
DROP
DROP TABLE messages;
支持
支持
TCL
BEGIN; COMMIT; ROLLBACK;
支持
支持
DAL
USE test_keyspace; DESC t_order;
SHOW CREATE TABLE t_order;
支持
支持
DCL
CREATE USER ‘test_user’@’%’ IDENTIFIED BY ‘test’;GRANT SELECT, INSERT ON test_keyspace. TO ‘test_user’@’%’;REVOKE INSERT ON test_keyspace. FROM ‘test_user’@’%’;DROP USER ‘test_user’@’%’;
不支持
支持
从测试结果看来,对于常用的 SQL 类型,无论是 Vitess 还是 ShardingSphere 都可以比较好的支持。但是 Vitess 无法支持排序,因此也无法支持分页对于部分应用来说可能是比较严重的问题。相比 Vitess,ShardingSphere 除 DISTINCT 关键字以外,其他类型的 SQL 支持程度均持平或略有优势。通过 SharingSphere 的官方 issue 列表中可知,DISTINCT 的支持目前正在进行中,相信不久之后就会支持。
分片路由分布式数据库将数据进行分片的主要目的之一就是希望执行的操作能分散在一个或其中数个分片中,而不是在所有分片中,因此如何触发分片路由,缩小分片范围也是需要重点关注的功能。Vitess 在 VSchema Guide 文档说明 Select、Update、Delete 通过 Where 条件中的等值条件进行路由,等值条件仅包括了 = 及 IN;Insert 则根据插入字段是否包含分片键来进行分片路由。ShardingSphere 除了支持 Where 条件中的 = 及 IN 进行分片路由之外,还可以通过 BETWEEN 进行分片路由 (需要使用 RangeShardingAlgorithm 或 ComplexShardingStrategy),Insert 时同样根据插入字段来进行分片路由。为了验证分片路由的执行条件,首先要开启 MySQL 数据库的 GENERAL_LOG 参数。
SET GLOBAL GENERAL_LOG = 1;SHOW VARIABLES LIKE '%general_log%';开启该参数之后,MySQL 数据库将会记录所有执行过的 SQL,通过查看分片库中实际执行的 SQL,来判断是分片路由还是广播。之后在 Vitess 中执行数个测试 SQL:
SELECT * FROM t_order WHERE user_id = 7;SELECT * FROM t_order WHERE user_id in (7, 9);SELECT * FROM t_order WHERE user_id=7 or user_id=11;SELECT * FROM t_order WHERE user_id BETWEEN 7 AND 11;从 Vitess 分片 1 的 general_log,找到 Mysql 实际执行了如下 SQL:
select * from t_order where user_id in (9)select * from t_order where (user_id = 7 or user_id = 11)select * from t_order where user_id between 7 and 11从 Vitess 分片 2 的 general_log,找到 Mysql 实际执行了如下 SQL:
select * from t_order where user_id = 7select * from t_order where user_id in (7)select * from t_order where (user_id = 7 or user_id = 11)select * from t_order where user_id between 7 and 11由于 user_id=7 属于分片 2,所以 SQL1 不会分发到分片 1 中,而 SQL2 也被实际改写,只将 user_id=9 分发到了分片 1,说明对于 = 以及 IN,Vitess 的确能够正确进行路由分片; 因为 user_id 7 和 11 均属于分片 2,所以对于等值 OR 查询 Vitess 并没有解析到条件内部,而是直接执行了广播。然后在 ShardingSphere 中执行测试 SQL:
SELECT * FROM t_order WHERE order_id = 1007 AND user_id=7;SELECT * FROM t_order WHERE order_id = 1007;SELECT * FROM t_order WHERE order_id in (1007, 1008);SELECT * FROM t_order WHERE order_id in (1007, 1009);SELECT * FROM t_order WHERE order_id=1007 or order_id=1011;从 ShardingSphere 分片 1 的 general_log,发现 Mysql 实际执行了如下 SQL:
SELECT * FROM t_order_1 WHERE order_id = 1007SELECT * FROM t_order_0 WHERE order_id in (1007, 1008)SELECT * FROM t_order_1 WHERE order_id in (1007, 1008)SELECT * FROM t_order_1 WHERE order_id in (1007, 1009)SELECT * FROM t_order_1 WHERE order_id=1007 or order_id=1011SELECT * FROM t_order_1 WHERE order_id=1007 or order_id=1010SELECT * FROM t_order_0 WHERE order_id=1007 or order_id=1010从 ShardingSphere 分片 2 的 general_log,发现 Mysql 实际执行了如下 SQL:
SELECT * FROM t_order_1 WHERE order_id = 1007 AND user_id=7SELECT * FROM t_order_1 WHERE order_id = 1007SELECT * FROM t_order_0 WHERE order_id in (1007, 1008)SELECT * FROM t_order_1 WHERE order_id in (1007, 1008)SELECT * FROM t_order_1 WHERE order_id in (1007, 1009)SELECT * FROM t_order_1 WHERE order_id=1007 or order_id=1011SELECT * FROM t_order_1 WHERE order_id=1007 or order_id=1010SELECT * FROM t_order_0 WHERE order_id=1007 or order_id=1010ShardingSphere 的等值查询和 Vitess 一样,能准确的确定对应分片表进行查询,当 SQL 中存在库级分片键 user_id 时(SQL1),ShardingSphere 只将 SQL 定位在了分片 2 的 t_order_1 分表;而查询不带有库级分片时(SQL2),ShardingSphere 进行了库级的广播,但仍然能够将 SQL 定位在 t_order_1 表;而对于 IN 方式,虽然能够准确的定位到分片表,但是不会对 IN 的条件进行重写(分片 1 的 SQL2-4);对于 OR 的等值查询,ShardingSphere 能够定位到具体的分片,比 Vitess 优秀;最后由于测试用例使用的是 InlineShardingStrategy,因此无法对 BETWEEN AND 的 SQL 进行测试。经过测试,Vitess 和 ShardingSphere 都可以对等值条件进行准确的分片路由;ShardingSphere 相比于 Vitess 多支持了 OR 等值的分片路由,并且在实现了特定算法或特定策略时,还能够支持 BETWEEN AND 的分片路由。另外,对于强制分片路由,Vitess 在 FAQ 中回答需要用户直接连接到对应分片的 vttablet 进行操作,而 ShardingSphere 支持 Hint 方式进行强制分片路由,依旧使得分片对应用透明。由此看来,ShardingSphere 在分片路由上的功能,也要略强于 Vitess。
路由条件
Vitess
ShardingSphere
= 值
正确路由
正确路由
IN
正确路由
正确路由
OR 等值
直接广播
正确路由
BETWEEN AND
直接广播
正确路由需要用户实现特定算法接口
结果归并当分片路由将 SQL 路由到多个分片,或无法使用分片路由而进行广播时,如何将多个分片的结果合并为一个正确的结果,就涉及到结果归并。Vitess 在文档中没有对结果归并详细的说明,从在之前的 SQL 测试中能够发现,Vitess 对于一般的结果仅是简单的将各个分片的结果集按照分片顺序连接起来;对于部分聚合的结果归并,如 count 和 sum,Vitess 能够正确的进行合并;但是对于一些复杂的归并类型,比如 avg 或 order by 的结果归并,就无法支持;在测试过程中,还发现 Vitess 会对 Limit 的分页 SQL 进行改写,比如分页 SQL
SELECT * FROM t_order LIMIT 10,10;就会改写成
SELECT * FROM t_order LIMIT 20;然后将 2 个分片的结果集合并之后再获取 10~20 的结果。ShardingSphere 在文档 归并引擎 一节中对结果归并有非常详细的描述,将归并分类为遍历、排序、分组、分页和聚合 5 种类型。不仅和 Vitess 一样能够将分片的结果集普通地连接起来,而且还支持了 avg 和 order by 的结果归并。同时对于 Limit 分页 SQL,也进行了改写。正是由于 ShardingSphere 对结果归并有着更好的支持,所以 ShardingSphere 在 SQL 支持上能够比 Vitess 表现的更好。
分布式事务事务是数据库中一个重要且常用的功能,对于分布式数据库而言同样不可或缺。因此 Vitess 和 ShardingSphere 都提供了一些可选的分布式事务功能。Vitess 提供了 3 个级别的分布式事务,单库事务、多库事务、两阶段提交事务,用户可选择其中一种作为 Vitess 的分布式事务实现:
单库事务指的是仅允许单个数据库事务。尝试超出单个数据库的任何事务都将失败。多库事务允许事务跨越多个数据库,但每个数据库均为单独提交,即弱 XA,可能会出现部分提交导致数据不一致,且无法回滚。两阶段提交类似于多库事务,但能保持多数据库间的原子性,即其中一个数据库提交失败时,其他数据库的提交将会回滚以保持数据一致。ShardingSphere 同样提供了 3 种类型的分布式事务,本地事务、XA 事务及柔性事务(开发中,预计 3.1.0 发布):
本地事务类似于 Vitess 的多库事务,各个数据库独立提交,即弱 XA。XA 事务即两阶段提交事务,默认采用 Atomikos 事务管理器。柔性事务采用 SAGA 模型进行事务控制,以保证数据的最终一致性。其中 ShardingSphere 在 3.x 之前的版本也使用过最大努力送达型事务,但由于无回滚能力,因此已经废弃,转而使用能力更加强大的 SAGA。Vitess 和 ShardingSphere 当前版本的分布式事务功能相当,但是 Vitess 的官方文档和 roadmap 计划中,似乎没有实现柔性事务的计划,因此一旦 ShardingSphere 3.1.0 中支持柔性事务,在分布式事务功能上将能支持更多的应用场景。
读写分离Vitess 的不提供默认的读写分离功能,但是提供在 SQL 中通过 @指定的方式进行从库的查询,例如在 SQL 中通过 ks@master 将查询指向主库,而使用 ks@replica 或 ks@rdonly 将查询指向从库或备库。ShardingSphere 的读写分离功能只需要在配置中指定主库和从库,ShardingSphere 能自动地将 DML 路由至主库,DQL 路由至从库;同时 ShardingSphere 允许多个从库并配置负载均衡策略将请求疏导到不同的从库;另外 ShardingSphere 还可以通过 Hint 进行强制主库路由。ShardingSphere 的读写分离功能,无论从对 SQL 的入侵程度,还是从功能的实现程度,都略强于 Vitess 的读写分离。
分布式主键Vitess 的分布式主键,用户可通过设定全局非分片的外部查询表来实现。如 Vitess 在官方文档中的用例,将 user_id(主分片键)列配上全局序列表 user_seq,组成自增分布式主键;ShardingSphere 提供灵活的配置分布式主键生成策略方式。 在分片规则配置中可配置每个表的主键生成策略,默认使用雪花算法(snowflake)生成 64bit 的长整型数据。ShardingSphere 的雪花算法的时间纪元从 2016 年 11 月 1 日零点开始,可以使用到 2156 年,相信能满足绝大部分系统的要求。
管理功能对比配置管理Vitess 将数据库信息、分片信息等元数据信息,存储在 zookeeper 或 Etcd 注册中心中,并配以 GUI 系统 vtctld 和命令行系统 vtctl 对 Vitess 的功能进行管理和控制。同时 Vitess 提供 workflows,将一些常用操作流程,变成可控制的工作流,使运维人员能够自动快速地执行诸如主从切换、数据迁移、平衡分片等操作。ShradingSphere 同样可以将分片信息,配置信息等元数据,存储在 zookeeper 或 Etcd 注册中心中,但暂时没有提供 GUI 或命令控制台功能,对配置和 ShardingSphere 程序进行控制和管理,用户需要在 zookeeper 或 Etcd 的 API 或自带的控制台中,修改其中的信息。
监控Vitess 在 vtagate 和 vttablet 中提供了简易的 GUI,用户通过 GUI 页面不仅能够查看 Vitess 本身部分组件的健康状况,QPS 等信息,还能获取一部分底层数据库的监控信息。ShardingSphere 自身并不提供监控,但是可以通过一些 APM 系统进行应用监控。目前 ShardingSphere 提供两种方式对接应用性能监控系统:
使用 OpenTracing API 发送性能追踪数据。面向 OpenTracing 协议的 APM 产品都可以和 ShardingSphere 自动对接,比如 SkyWalking,Zipkin 和 Jaeger。使用 SkyWalking 的自动探针。数据库管理Vitess 提供了备份数据库数据的功能,能将数据库的数据、配置,连同 vttablet 一同备份到 NFS、云存储或本地文件系统中,在备份的过程中,还能进行自动压缩以提高备份效率,并且 Vitess 可以从备份中快速创建出 vttable 并加入集群中。Vitess 还提供了主从切换和重设主从关系的功能,该功能不仅可以由 DBA 有计划的使用 workflow 执行,还可以在数据库节点失效或有问题时自动执行。Vitess 也提供了重分片 (Resharding) 的数据迁移方式,使得用户能够在修改分片规则后平滑地将旧分片的数据迁移到新分片上,Vitess 会在新分片上复制,验证和保持数据最新,而现有分片继续提供实时读写流量。当 Vitess 准备切换时,只需几秒钟的只读停机时间即可进行迁移。在切换执行期间,可以读取现有数据,但无法写入新数据。ShardingSphere 目前仅提供了熔断实例和禁用从库的功能,在 roadmap 中还规划实现多数据副本和弹性伸缩的功能。总结Vitess 和 ShardingSphere 作为当下优秀的数据库中间件和分布式数据库解决方案,在数据分片、分布式事务和数据库治理等功能上均有所建树,但是双方在功能侧重上有部分差异。关于数据分片、分布式事务等 OTLP 应用功能方面,ShardingSphere 比 Vitess 提供了更丰富和自由的分片方式、提供了更多的 SQL 支持和更容易触发的分片路由、提供了侵入性更低的读写分离并即将提供更多种的分布式事务类型。因此 ShardingSphere 在应用功能方面要强于 Vitess。而关于管理方面的功能,Vitess 相比 ShardingSphere 增加了 GUI 的控制方式、提供了数据库的备份和主从切换功能、并提供部分自身和数据库的监控。因此 Vitess 在管理方面的功能要优于 ShardingSphere。ShardingSphere 还在快速发展中,未来也会对数据库治理及弹性数据迁移做大量工作。如果目前想找一个完美的在线功能 + 管理功能的解决方案,可以混合部署,在线查询更新用 ShardingSphere,然后使用 Vitess 进行数据的管理和监控,并可以自行开发插件,同步 Vitess 和 ShardingSphere 的注册中心配置,使其动态生效。最后,通过一个简单的表格,总结一下 Vitess 和 ShardingSphere 的对比结论:Vitess
ShardingSphere
分片模式
仅分库
分库 + 分表 + 分库分表
SQL 支持
略少于 ShardingSphere
略多于 Vitess
分片路由
支持 = 和 IN
支持 =、IN、OR、BETWEEN AND 允许用户 Hint 强制路由
分布式事务
1PC(弱 XA)和 2PC(强 XA)
1PC(弱 XA)、2PC(强 XA) 将支持柔性事务 SAGA
读写分离
在 SQL 中指向主库或从库
配置之后由 ShardingSphere 自动路由
分布式主键
通过全局非分片序列表实现
实现接口,默认使用雪花算法
配置管理
支持 Zookeeper 和 Etcd 提供 2 类管理端
支持 Zookeeper 和 Etcd 暂无管理端
数据库治理
提供简单数据库监控 提供数据备份、主从切换、重分片数据迁移等
仅提供熔断、禁用从库功能
