10 几年前,互联网产业蓬勃发展,相比传统 IT 企业,互联网应用每天会产生海量的数据。
如何存储和分析这些数据成为了当时技术圈的痛点,彼时,分库分表解决方案应运而生。
当时最流行的 Java 技术论坛是 javaeye ,有位淘宝的技术人员分享了一篇分库分表的文章 ,这篇文章,我反复看了几十遍,想从中吸取更多的营养,但基于我孱弱的技术能力,总是感觉隔靴搔痒。
直到 2012年 Cobar 开源了 ,我的困惑才初步消解了。
1 Cobar 开源了Cobar 是由 Alibaba 开源的 MySQL 分布式处理中间件,它可以在分布式的环境下看上去像传统数据库一样提供海量数据服务。
Cobar 开源后,我迫不及待的的去下载 Cobar 的部署包,配置两个库同样一张表,在两个库分别手工插入 1 条记录,然后通过 Navicat 连接 Cobar 暴露的端口,竟然发现数据表显示两条数据 。
看到 Navicat 的显示,我当时的表情如下:

虽然我极度渴望探索 Cobar 原理的奥秘 , 而且互联网上关于 Cobar 的文章其实并不多 ,我认识的同事朋友也对分库分表不熟悉,于是我想到了世界上最笨的方式:
将 Cobar 源码抄写一次,边抄边理解,直到可以将程序跑起来。
于是,我建了一个新的 maven 项目,一点点去抄。

最开始是模仿 Cobar 的包的结构,接着是网络通讯设计,最后是 SQL 解析 。
网络通讯模块跑通了,但当我抄到 SQL 解析模块时,因为不理解原理,抄起来实在太费劲了,轰轰烈烈的抄源码运动戛然而止,花费了接近三个月的时间。
2 抄源码的收获虽然那时我并没有完全理解 Cobar 的实现机制,但收获还是很大的。
1、网络编程
第一次接触到 Reactor 模式,NIOAcceptor 用于处理前端请求,NIOConnector 则用于管理后端的连接,NIOProcessor 用于管理多线程事件处理,NIOReactor 则用于完成底层的事件驱动机制。

我接触到 Netty 之后,才想到 Cobar 的网络通讯层可以更加优雅点 。事实上 ,MyCat 就是重点优化了后端网络通讯层。
2、缓存池
第一次知道原来可以在网络通讯里,封装统一管理 NIO 的 Buffer 。
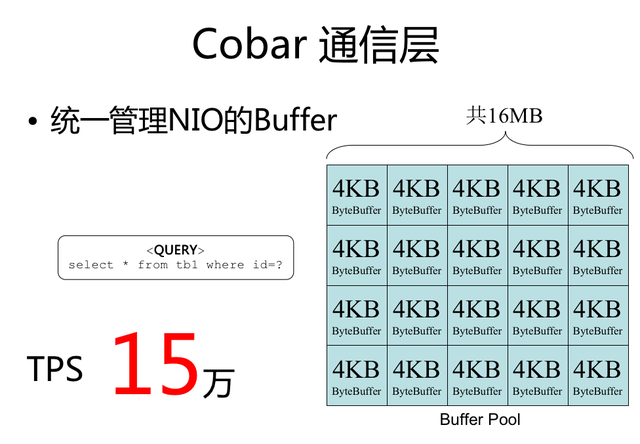
3、打包技巧
Cobar 这种 maven 打包方式,目录结构如下:

我自己写项目都会参考这种 maven 打包方式,因为这种方式相比原来 tomcat webapp 部署包的方式更加优雅。
4、学习 sharding-jdbc
当我对于分库分表 Proxy 的设计有了初步认识之后,再来学习当当开源的 sharding-jdbc 时就轻松很多了。
3 开源分库分表示例项目其实,我对于分库分表技术的执念,更多在在于我强烈的渴望:当遇到需要分库分表的场景,我有足够的能力去解决这个问题。
今年 3月份,我开源了一个分库分表示例项目。

github地址:https://github.com/makemyownlife/shardingsphere-jdbc-demo
这个项目的初衷是:帮助 Java 同学们快速入门分库分表,但又不止于分库分表 。
1、 Grpc ID 生成器示例


2、 shardingsphere jdbc 4.X/5.X 分库分表例子
项目提供了两个模块,分别使用 jdbc 4.X 和 jdbc 5.X 两个版本。

同时,有的同学想使用原生 API 实现分库分表,每个模块里都准备了原生 API 使用的例子 ,方便同学们调试。

网上有很多 shardingsphere jdbc 5.X 的例子,但很多使用方式并不标准,勇哥结合官网文档,并对比网上很多例子,花了很多天才梳理好。
3、 antlr 学习例子
shardingsphere 基于 antlr4 设计了新一代的 SQL 解析引擎,勇哥单独抽出一个模块用来演示:

后面会逐步完善 antlr 的例子,比如简单的 SQL 查询解析、JSON 格式解析等。
这个项目还在不断的进化中,后面还要添加扩容相关的知识点,比如 canal、datax ,希望能帮助大家 !
4 写到最后有些公众号文章写到:分库分表,可能真的要退出历史舞台了!我从来也没有否认分布式数据库架构的先进性 ,但我想分库分表的更大的优势在于:简单。
武汉有些小公司并没有很强的技术储备,但他们用极少的研发人员就可以处理很大的数据量。
因为没有完美的技术,只有最合适的技术 !
最后,来看看 2012年那个傻傻的抄写代码的我,有人说我长得像周杰伦,不过我觉得像梁朝伟 !

