不知道大家发现没有,一些大模型的提示技巧总是习惯将一些重要指令或信息放在提示的开头或者结尾。
这是因为LLMs在处理上下文的时候容易出现“lost in the middle”的位置偏差,即它们倾向于关注提示中开头和结尾的信息而忽略中间信息。特别随着上下文越来越长,这种位置偏差带来的性能效果愈发严重。
这个问题是所有LLMs的通病,连像ChatGPT这样的强大模型也难以避免这一问题。文献[1]就指出,GPT-3.5-Turbo模型在试验多文档问答任务时,将答案放置在提示中间与末尾的性能差异高达22分。
3.5研究测试:hujiaoai.cn4研究测试:askmanyai.cnClaude-3研究测试:hiclaude3.com
这到底是怎么一回事?位置偏差的根源是什么?是否与LLMs的结构有关?我们又该如何减轻这一问题?接下来,我们将通过清华大学的一项研究来探讨这些问题。
论文标题:Mitigate Position Bias in Large Language Models via Scaling a Single Dimension
论文链接:https://arxiv.org/pdf/2406.02536
出现位置偏差的原因位置偏差的微观表现大模型的一大基本组成结构是Transformer,注意力机制又是Transformer的关键组成部分。自回归模型的注意力可以用以下方程表示:
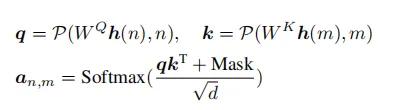
其中是隐藏状态,是第个token的隐藏状态。, 是线性层的权重,是位置编码函数,是查询和键状态的维度,和是位置顺序信息。是因果掩码。
为了探索Transformer中位置偏差的微观表现,作者分析了包含关键信息的句子的注意力权重。
主要设计了一个KV检索任务,要求模型从包含50个键-值对的列表中检索给定键的真实值,结果如下图所示:
 在深层中,模型表现出类似检索的行为,专注于真实信息,形成了图b中观察到的对角线模式。而在其他浅层中,它总是将大部分注意力集中在提示的开头或结尾,无论关键信息位于何处,都呈现出垂直线模式,如图a所示。作者提取了对关键信息的注意力(层15~25的平均值)与不同上下文长度的关系,如图c所示,随着上下文长度的增加,关于位置的注意力权重的衰减变得更加显著,几乎在中间部分达到零。
在深层中,模型表现出类似检索的行为,专注于真实信息,形成了图b中观察到的对角线模式。而在其他浅层中,它总是将大部分注意力集中在提示的开头或结尾,无论关键信息位于何处,都呈现出垂直线模式,如图a所示。作者提取了对关键信息的注意力(层15~25的平均值)与不同上下文长度的关系,如图c所示,随着上下文长度的增加,关于位置的注意力权重的衰减变得更加显著,几乎在中间部分达到零。也就是说当关键信息位于提示的开头或结尾时,注意力权重集中在它上面相对较高,而在中间部分则明显较低。
因果掩码对位置偏差的影响根据以上注意力的公式,位置嵌入允许LLMs获取位置信息,而最近研究也指出因果掩码也可以引入位置信息。因果掩码(causal mask)就是让模型在预测当前Token时不能看到未来的Token。
为了确定这两个因素是否通过修改基础KV对的不同属性来影响位置偏差。引入以下三个基线:
Crop Mask:裁剪掩码,修改因果掩码,使基础KV对只看到自身而不看到之前的tokens。PE to Beginning:将基础KV对的位置ID减少到与第一个KV对相同。PE to End:将基础KV对的位置ID增加到与最后一个KV对相同。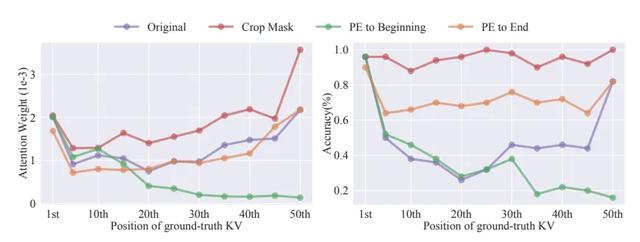
从图中可以看到原始结果出现了“中间丢失”现象,不仅影响准确性,也影响注意力权重。PE to End对模型性能有一定帮助,但远不如基础KV对位于提示首尾时的效果。PE to Beginning时性能显著下降,且当标准答案KV接近结尾时,注意力权重减少。相比之下,修改因果掩码显著增强了注意力,特别是对后续KV,几乎达到了开头位置的性能。
因此,除了位置嵌入,因果掩码也是影响位置偏差和注意力权重的关键因素,且仅调整位置嵌入无法彻底纠正位置偏差。
因果掩码在特殊的隐藏状态下存储了位置信息为了深入探究transformer中位置信息的传递方式,作者定义了一种特殊的隐藏状态——位置隐藏状态,它直接反映绝对位置信息,并与位置ID紧密相关:
Positional Hidden States.:令表示每个token位置上隐藏状态的第维。将位置隐藏状态定义为其值与位置序列一致且单调变化的隐藏状态。因此,它们的导 数(经过曲线拟合后)应始终为正或负:

上图的实验结果显示,因果LLM在多数层中持续表现出这种隐藏状态,即使模型没有明确的绝对位置嵌入。这表明因果掩码可能是提供绝对位置信息的关键。
综合以上分析,可以得出:因果掩码在特定隐藏状态中存储位置信息,并影响注意力权重,从而引发位置偏差。
减轻位置偏差的方法尽管因果掩码深刻影响位置偏差,但由于事先无法知道提示中有效信息的位置,因此也没法直接修改因果掩码。作者提出了一种通过扩展位置隐藏状态来减轻位置偏差的方法,包括两个步骤:识别位置隐藏状态并将其按因子进行缩放。如下图所示:
 问题定义
问题定义给定一个预训练的LLM θ 和一个通用数据集 ,目标是找到最优的位置隐藏状态 和相应的缩放因子 ,以最大程度地减少位置偏差:

其中, 表示ground-truth在提示 中的不同位置集合,θ 表示在其隐藏状态的第 维度上通过缩放因子 对 LLM θ 进行缩放操作, 表示修改后模型通用下游任务的损失。
识别位置隐藏状态为了高效地从LLMs的隐藏状态集中搜索位置隐藏状态,作者提出了基于先验的搜索算法:
确定隐藏状态中单调性超过ε层且尽可能平滑的前个维度ρ使用小型验证数据集评估分别扩展这些位置隐藏状态的影响, 并选择能导致最小损失的位置隐藏状态:缩放位置隐藏状态为了最小化对LLMs语义的影响,作者提出仅通过缩放位置隐藏状态来影响最后一个token,具体来说,对于最后一个token之前的token,注意力计算保持与原始相同。对于长度为l的序列的最后一个token的注意力计算,通过缩放位置隐藏状态获得修改后的查询状态(第l个token,即最后一个token)和键状态K(所有token)。

这里表示的第维被因子缩放。因此,相应的注意力计算如下:
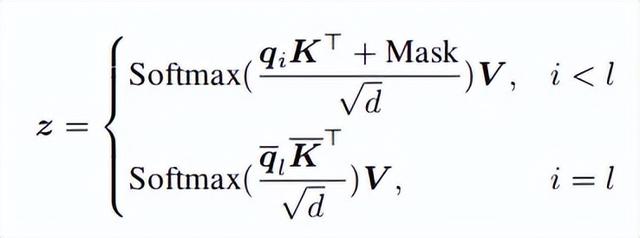
作者使用FlashAttention 来实现,开销最小。在获得合并的注意力权重后,剩余的计算与原始方法相同。
实验作者分别在NaturalQuestions(20个文档)和KV检索(140个KV对)数据集以及LongBench基准上测试不同模型的不同方法的性能。

 本文方法在NQ、KV检索和LongBench基准上的性能分别提升了9.3%、15.2%和4.7%,但KV检索中的LLaMA-2-13B除外。与SoTA方法Ms-PoE相比,本文方法在NQ、KV检索和LongBench上的性能提升显著,分别高达6.3%、97.5%和14%。Ms-PoE在KV检索中的不佳表现可能是由于插值导致的信息丢失。本方法有效增强了LLMs对提示中后部分信息的理解,对提示开头的关键信息性能与基线相当。针对最后四个位置,在NQ和KV检索中,对原始结果的改进分别增加到11.3%和16.8%,对Ms-PoE的改进分别为8.7%和97.5%。此外,该方法不仅适用于RoPE模型,也适用于像Vicuna-16K这样的上下文窗口扩展模型。同时,它能适应不同的位置嵌入,如Alibi的MPT模型,在NQ、KV检索和LongBench上分别实现了2.6%、15.2%和1.2%的改进。在LongBench的不同任务中,本文方法展现了不同程度的性能提升。其中,在少样本学习任务中最为显著,提升达到22.9%;在代码任务中提升8.6%;在合成任务中提升4%;在单文档QA任务中提升9.2%;在多文档QA任务中提升1.9%。在摘要任务中,性能与原始结果基本持平。从偏见到平衡:调整缩放因子
本文方法在NQ、KV检索和LongBench基准上的性能分别提升了9.3%、15.2%和4.7%,但KV检索中的LLaMA-2-13B除外。与SoTA方法Ms-PoE相比,本文方法在NQ、KV检索和LongBench上的性能提升显著,分别高达6.3%、97.5%和14%。Ms-PoE在KV检索中的不佳表现可能是由于插值导致的信息丢失。本方法有效增强了LLMs对提示中后部分信息的理解,对提示开头的关键信息性能与基线相当。针对最后四个位置,在NQ和KV检索中,对原始结果的改进分别增加到11.3%和16.8%,对Ms-PoE的改进分别为8.7%和97.5%。此外,该方法不仅适用于RoPE模型,也适用于像Vicuna-16K这样的上下文窗口扩展模型。同时,它能适应不同的位置嵌入,如Alibi的MPT模型,在NQ、KV检索和LongBench上分别实现了2.6%、15.2%和1.2%的改进。在LongBench的不同任务中,本文方法展现了不同程度的性能提升。其中,在少样本学习任务中最为显著,提升达到22.9%;在代码任务中提升8.6%;在合成任务中提升4%;在单文档QA任务中提升9.2%;在多文档QA任务中提升1.9%。在摘要任务中,性能与原始结果基本持平。从偏见到平衡:调整缩放因子如下表所示,当关键信息不位于开头时,本文方法表现更佳。这暗示了位置隐藏可能使得模型忽略了上下文的后半部分,而过分关注开头部分。为了解决这个问题,扩展这一维度可以帮助模型更均衡地分配注意力,不再过分偏重于开头。

作者通过测试不同的比例因子来验证这一观点,如下图所示,缩放因子直接控制位置隐藏状态对位置偏差的影响程度和方向。

当缩放因子为正时,模型更偏向关注开头;为负时,则更偏向关注结尾。经过测试,缩放因子在0.5到-1之间时,模型的注意力分布最为均衡,同时准确性也达到最佳。这证实了调整位置隐藏状态可以影响LLM对开头信息的过度关注,并通过适当设置系数来有效缓解这种偏见。
消融实验为了评估不同组件的重要性,进行了以下消融研究:
调整搜索算法,分别在不考虑单调性、平滑性和验证集的情况下观察模型性能变化。调整两个维度的规模,并改变前两个位置的隐藏状态,以观察其对模型性能的影响。修改受缩放操作影响的tokens范围,包括仅修改最后16个tokens和修改所有tokens的情况。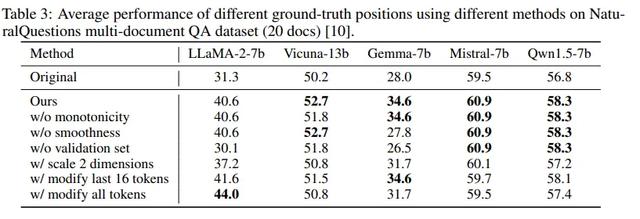
结果如下表发现:
如果不考虑单调性或平滑性进行过滤,模型性能会有所降低;而去除验证集则会导致性能进一步下降。此外,当受缩放影响的tokens范围或维度扩大时,大多数模型性能会有所损失。综合考虑这些因素,最终选择仅修改最后一个tokens和顶部第一个位置的维度,以实现最佳性能。
结语本文揭示了LLMs存在位置偏差的原因,即transformer中的注意力权重存在位置偏差,并且除了位置嵌入外,因果掩码也会引入这种偏差。这种偏差通过包含绝对位置信息的隐藏状态传递给模型的其他部分。
为了应对这一问题,开发了一种基于先验知识的位置隐藏搜索算法,并通过扩展这些搜索到的位置隐藏状态来减轻位置偏差,显著提升了模型性能。

