






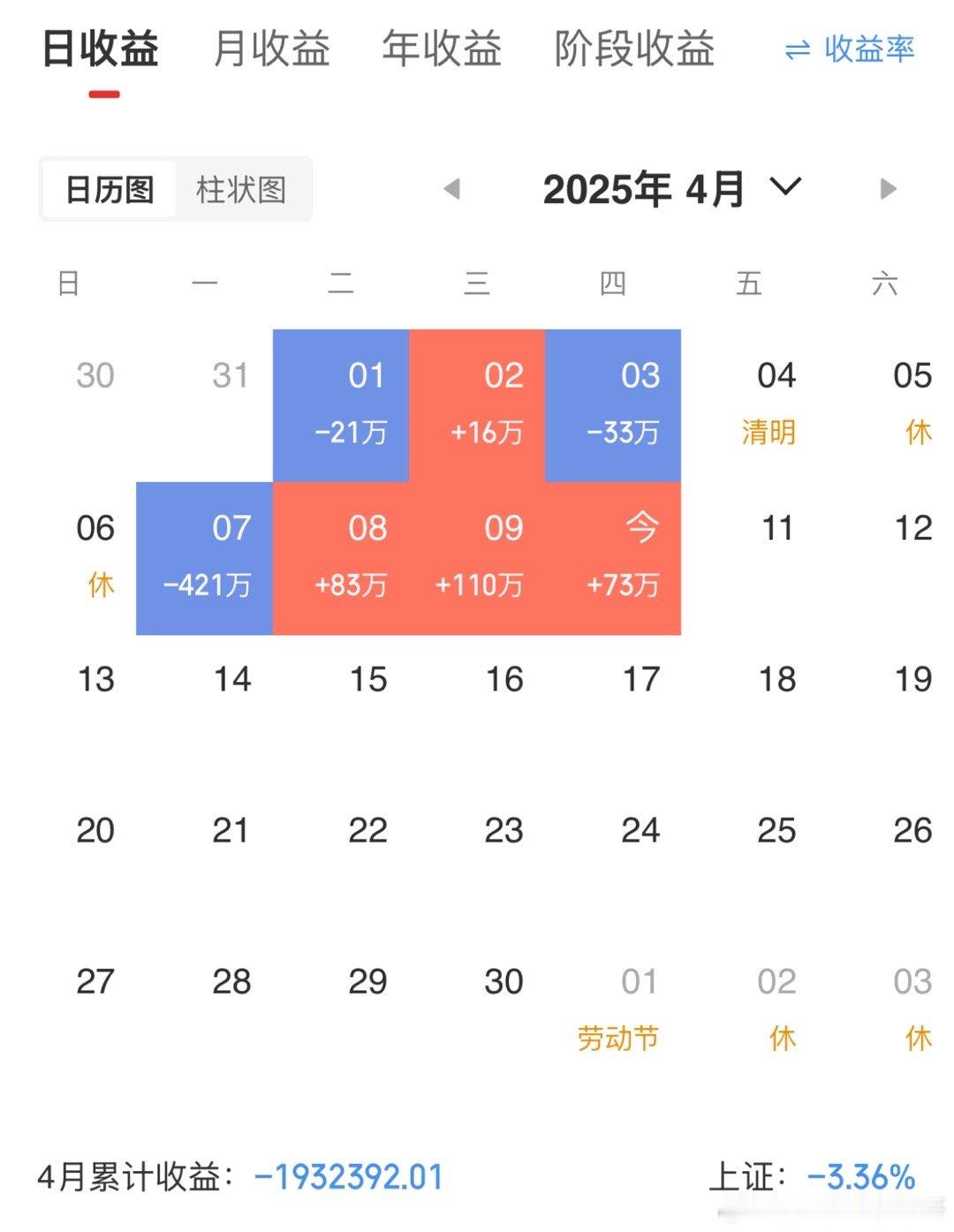
我老公去年不知道哪根筋搭错了,突然从银行借了750万。这钱到账后,我没花,直
15评论
13点赞

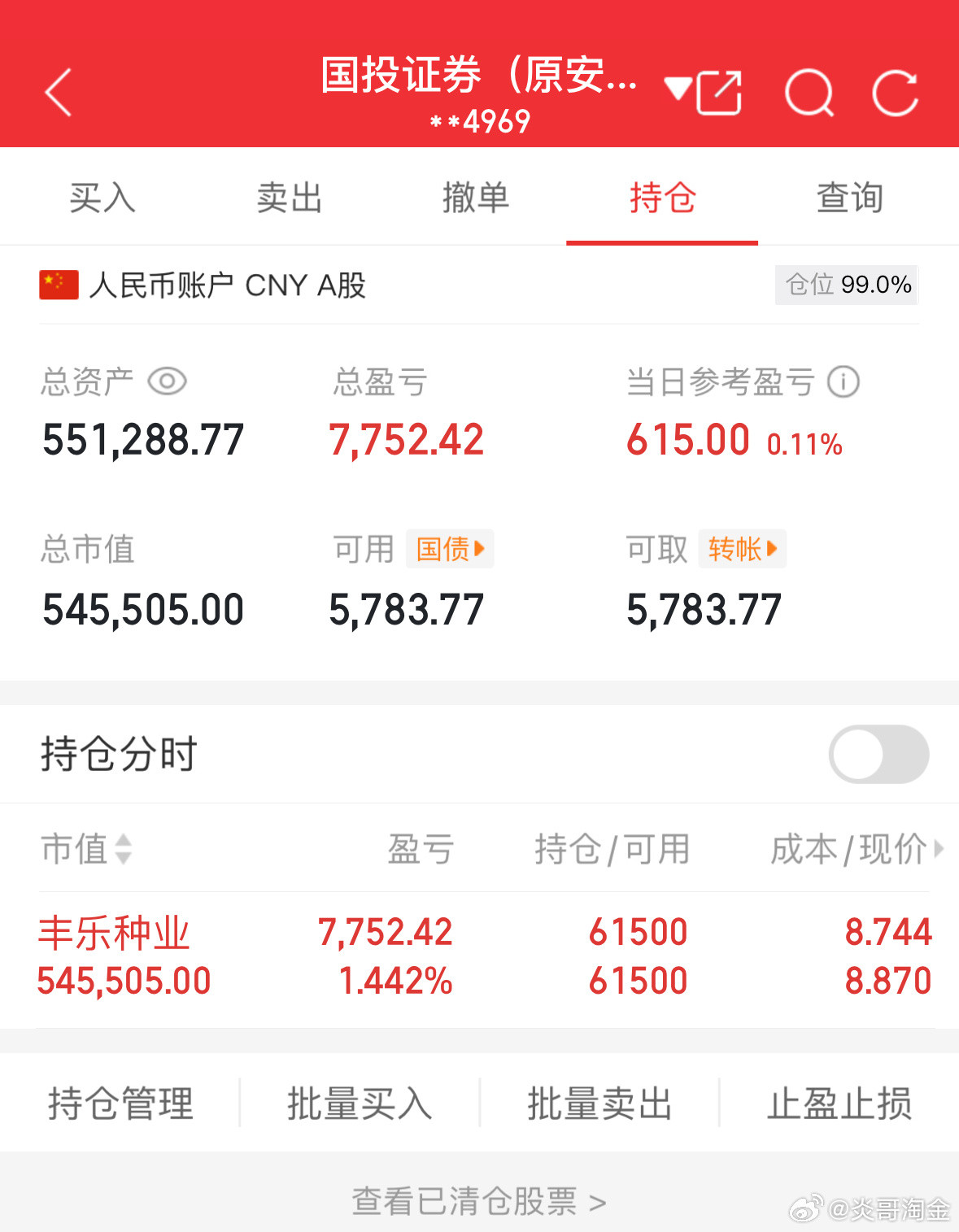

退市风险名单。注意避雷
12点赞
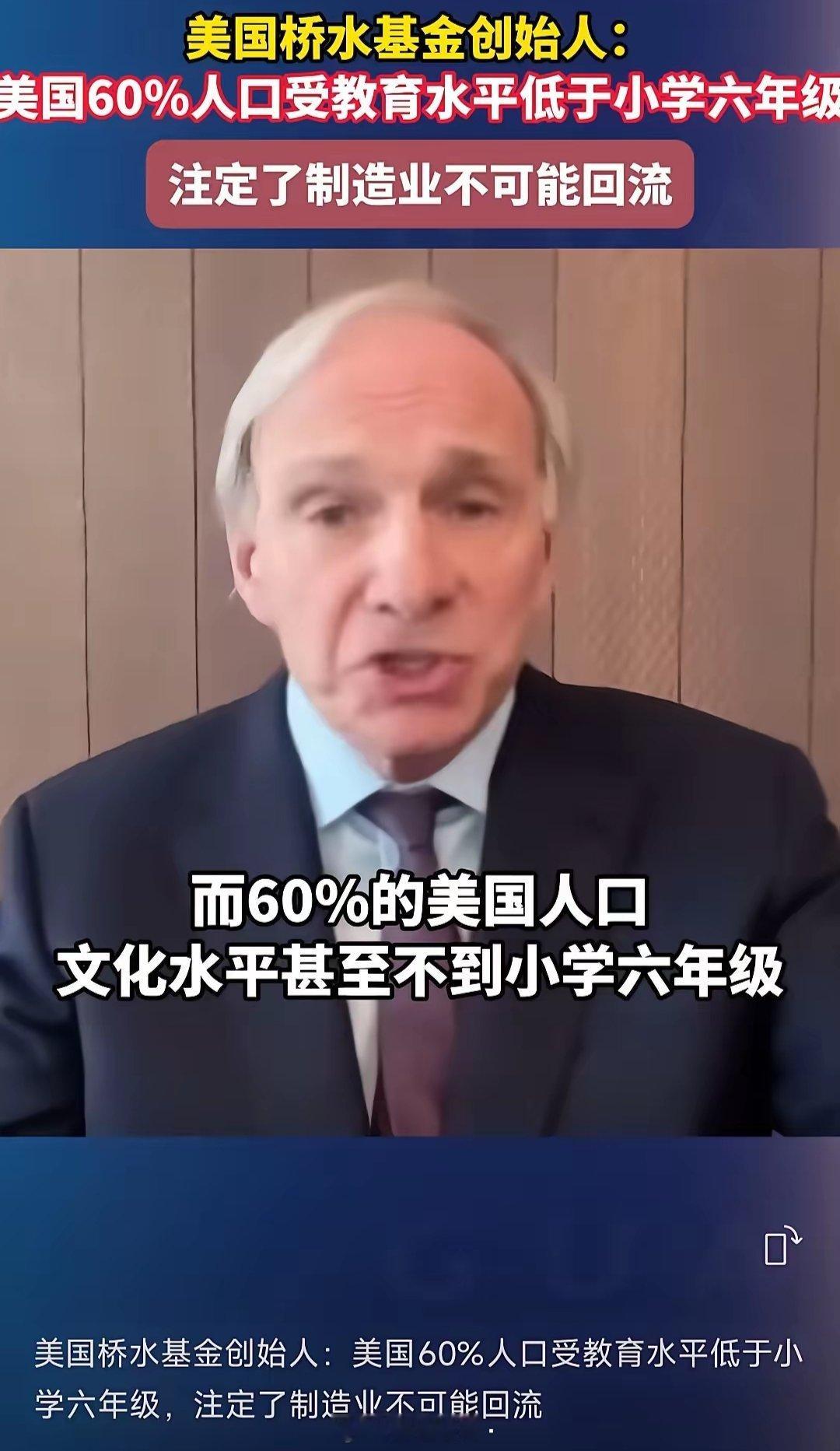
被震惊了!美国桥水基金创始人爆料:美国制造业无法回流不是因为受教育程度高,不愿意
102评论
38点赞

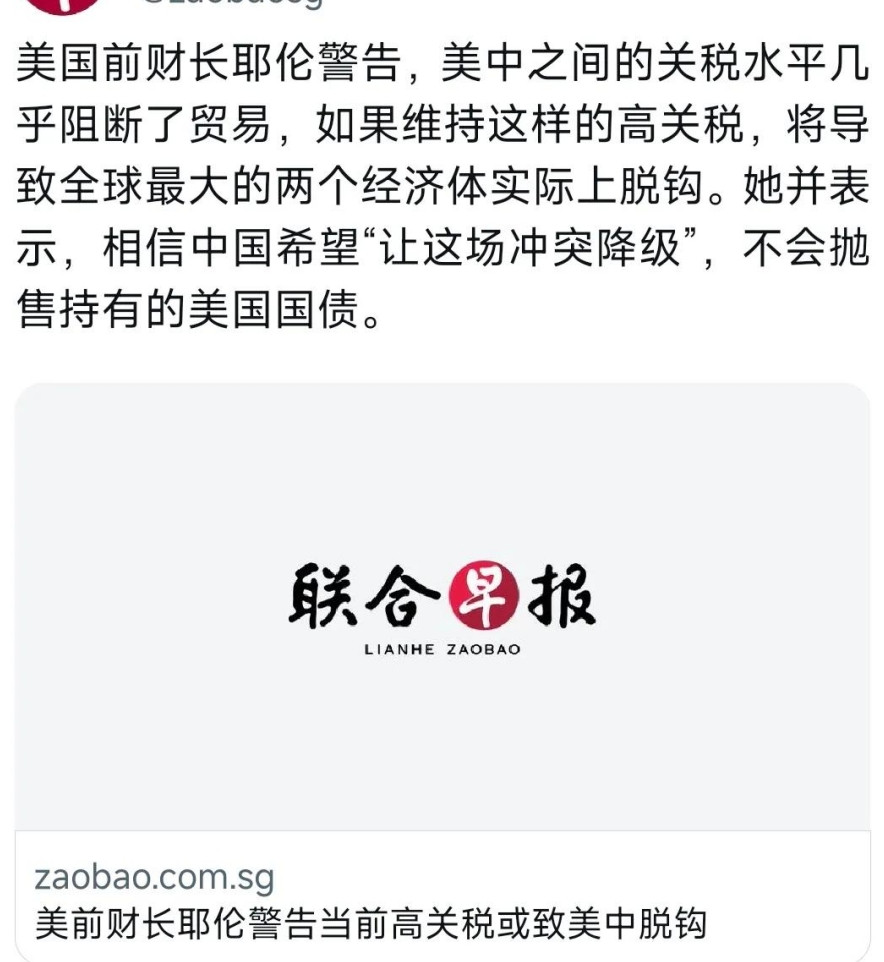






美国对东大抛售美债表态了!4月14日消息,美国贸易代表贾米森·格里尔发话了,他说
36评论
38点赞
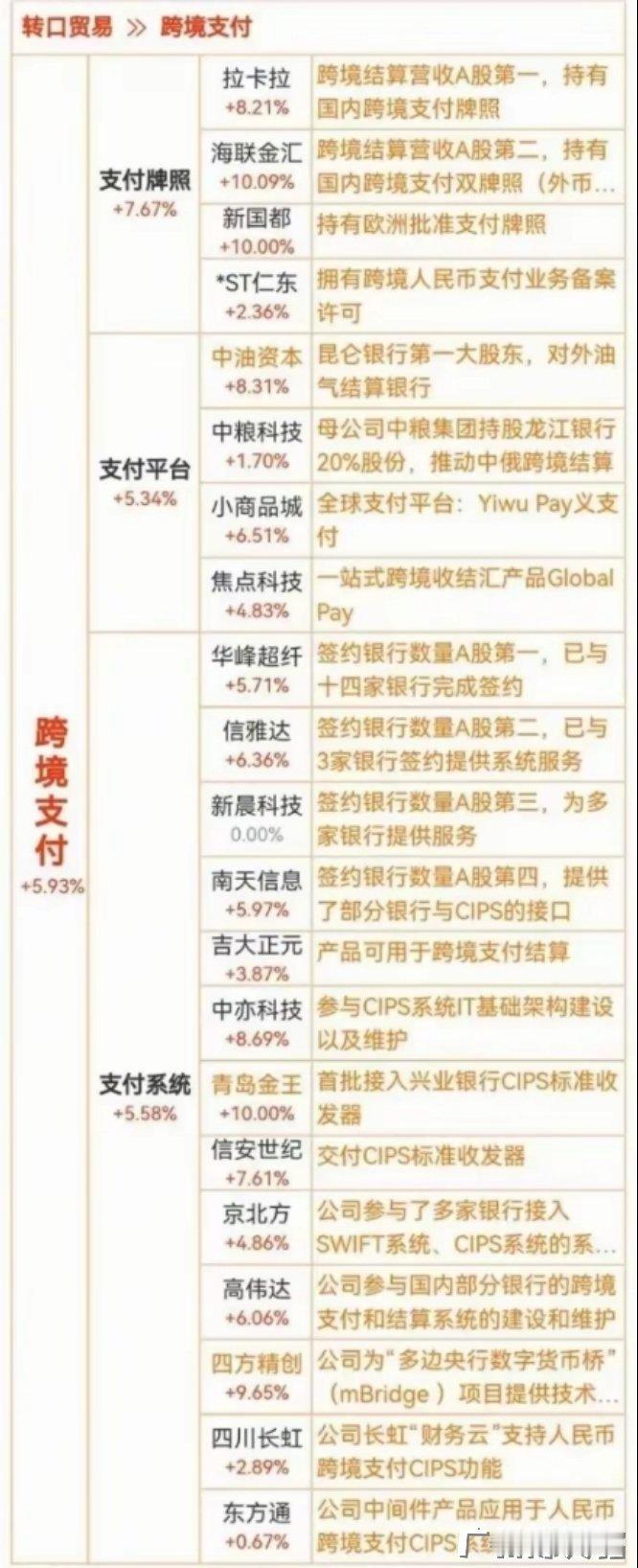
关税反制利好概念农业概念
1点赞


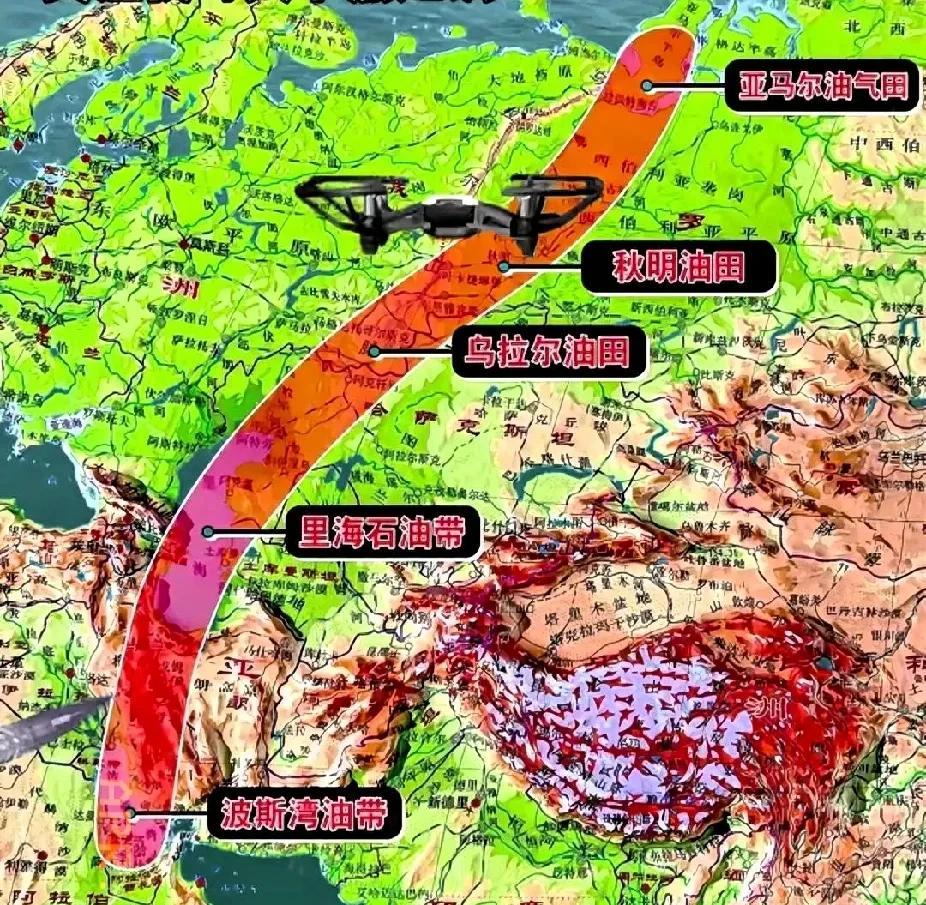

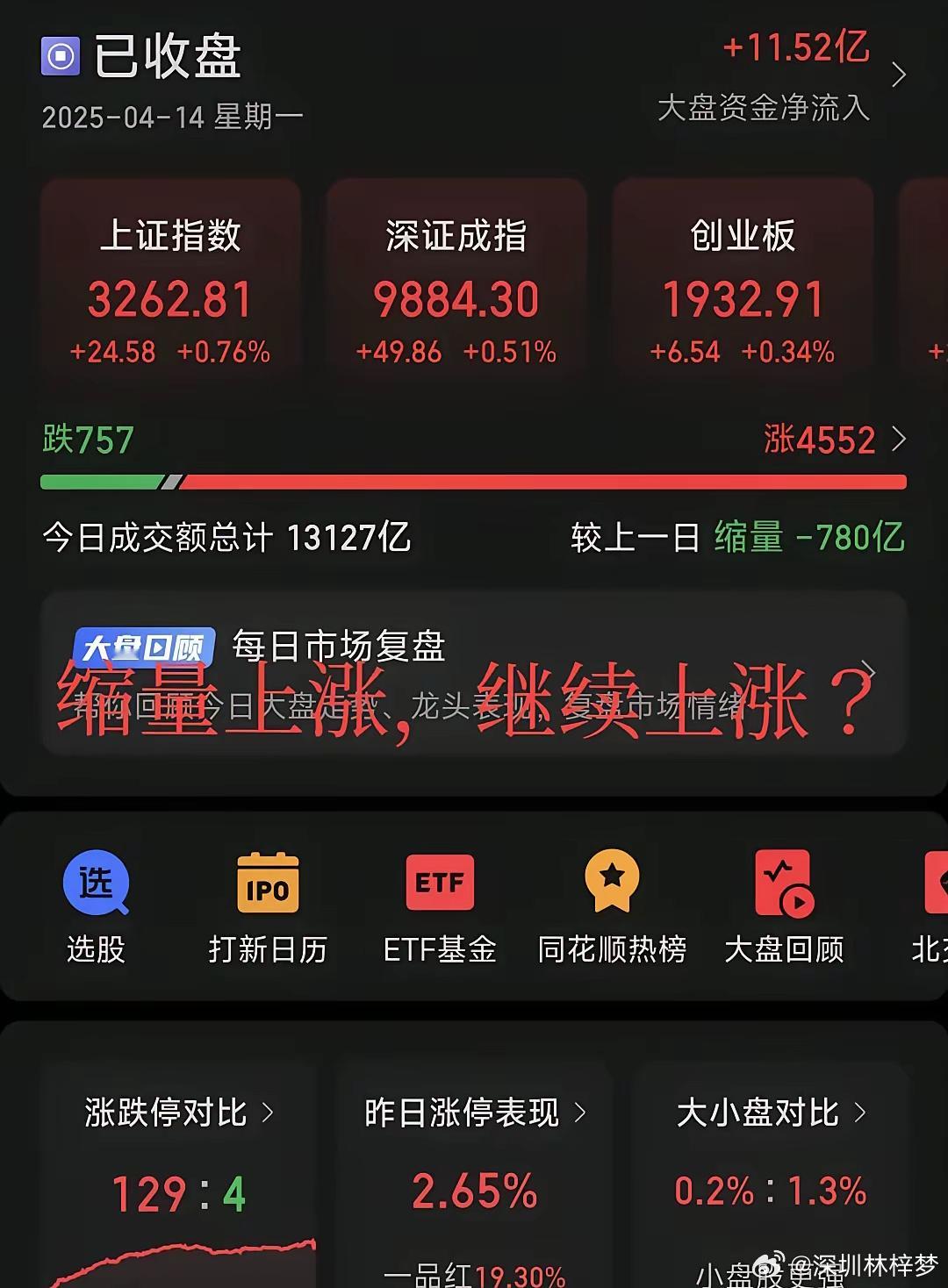
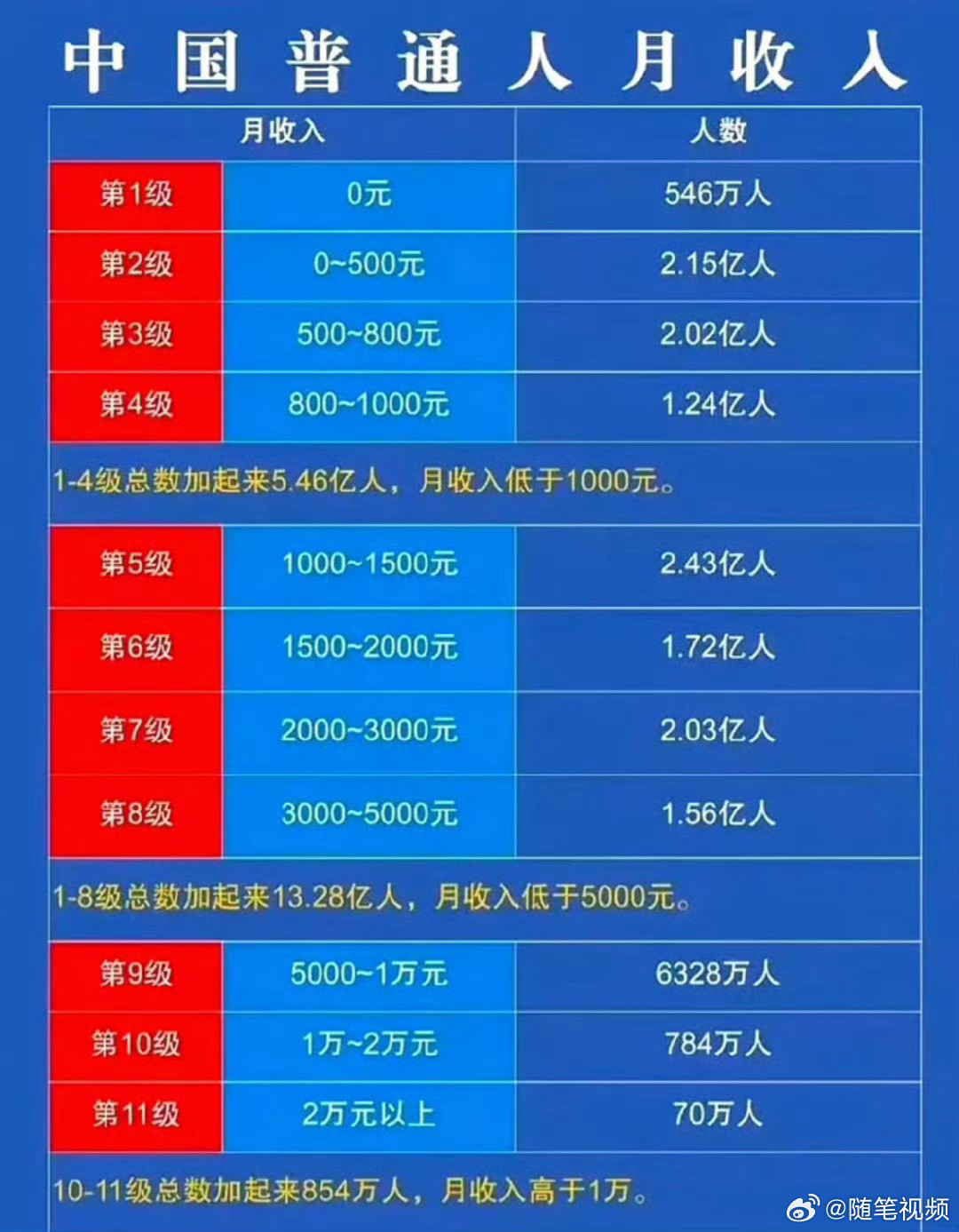

这一轮中美贸易战,彻底撕下了遮羞布!4月13日曝光的四条猛料,让全世界看清了中美
10评论
12点赞
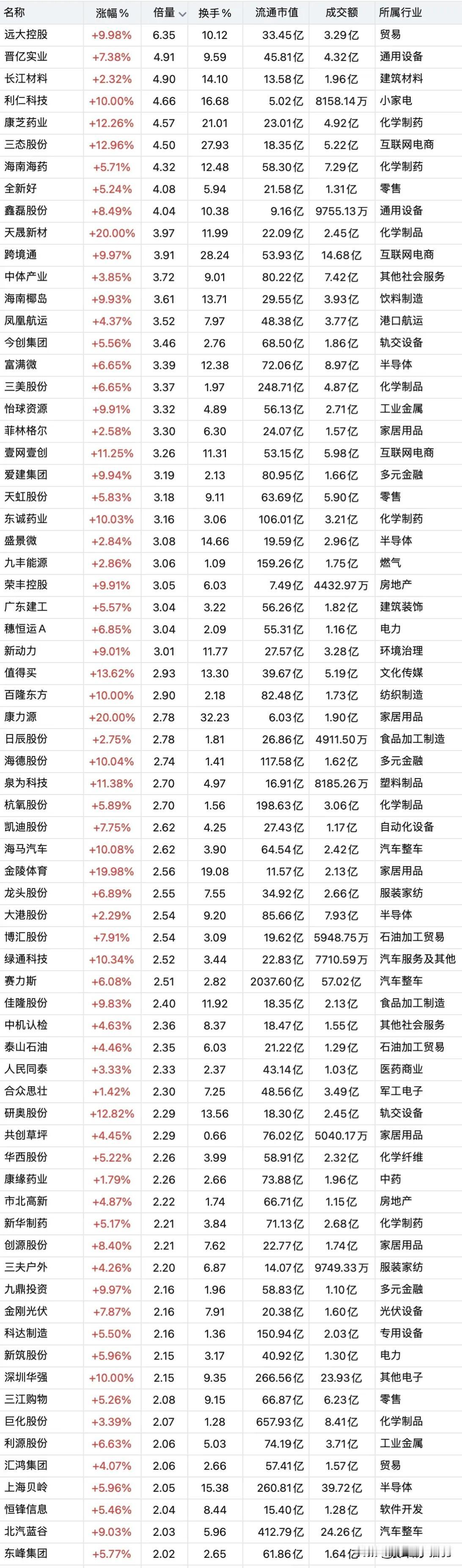

中阿货币互换协议,通俗点说就是:中国拿350亿人民币,放到阿根廷,阿根廷拿同等价
92评论
57点赞
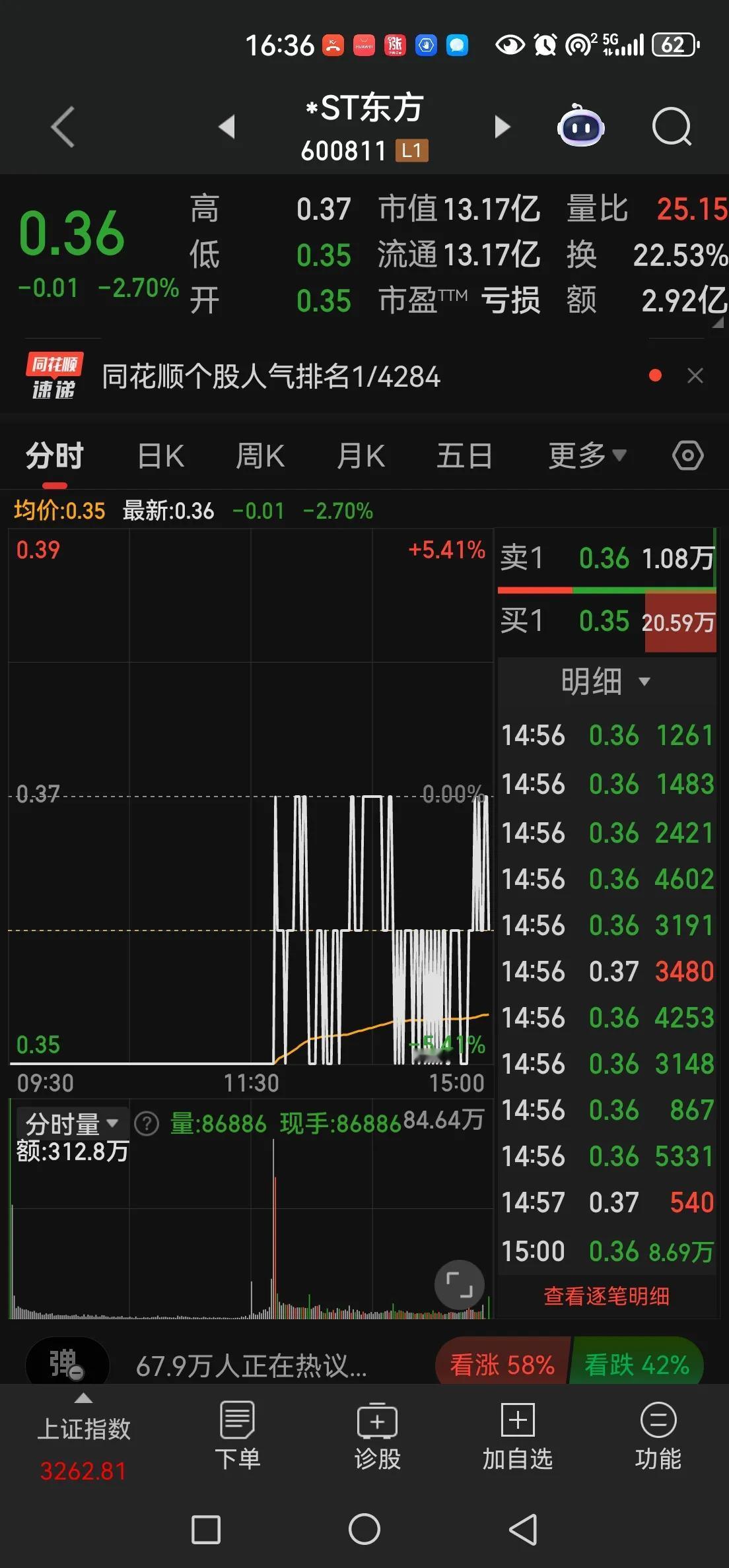


好消息!全国首个!全国首个!全国首个!中国刷出王炸!!!
59评论
107点赞

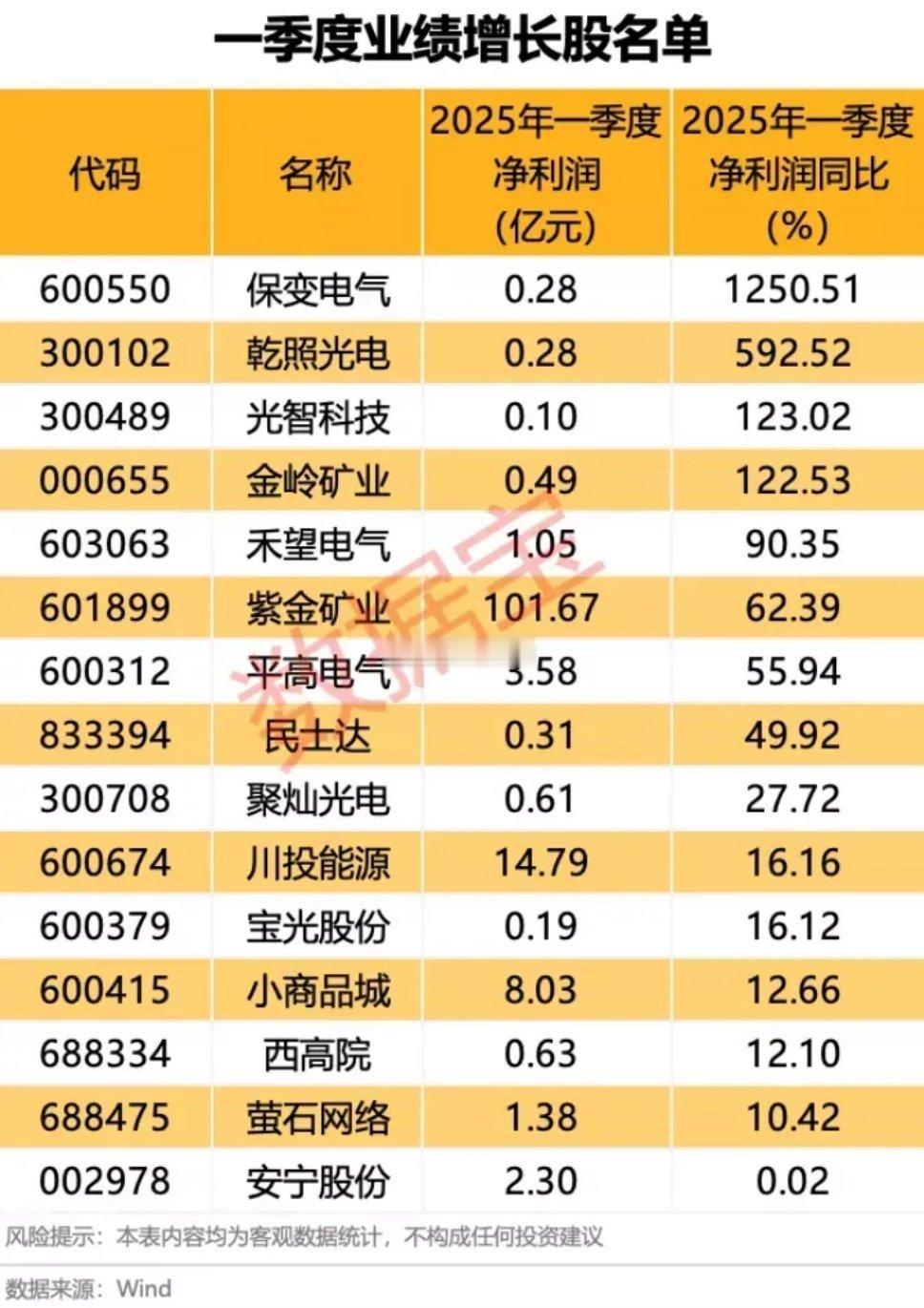
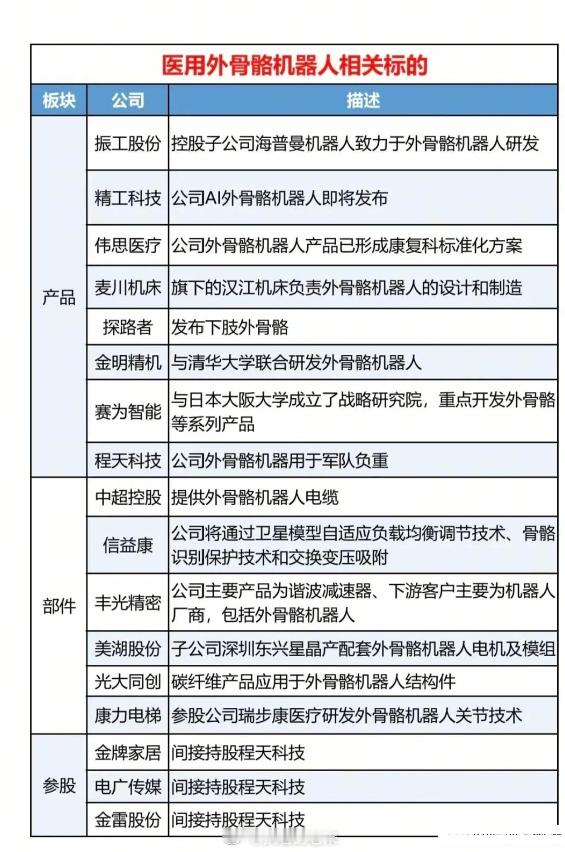
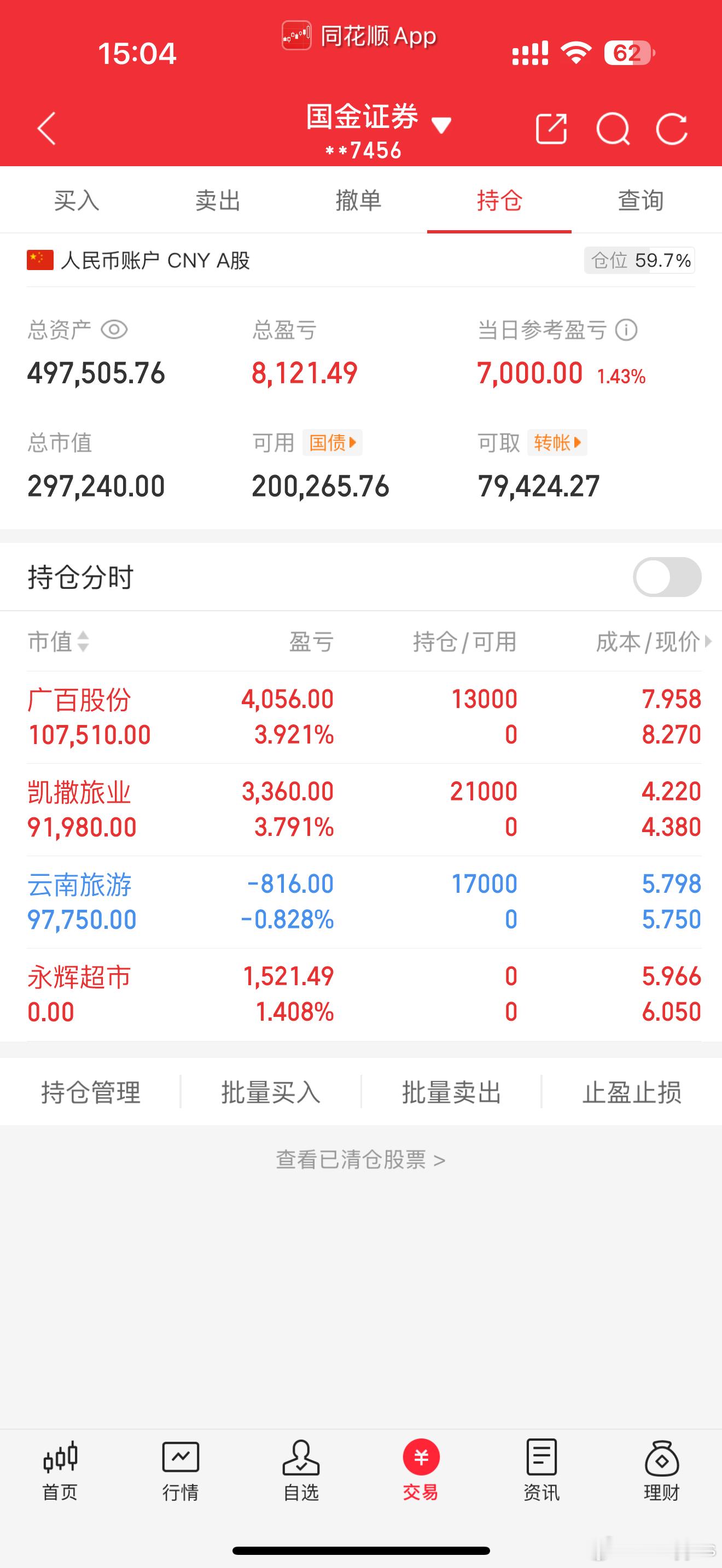
一季度业绩增长股票名单:
10点赞


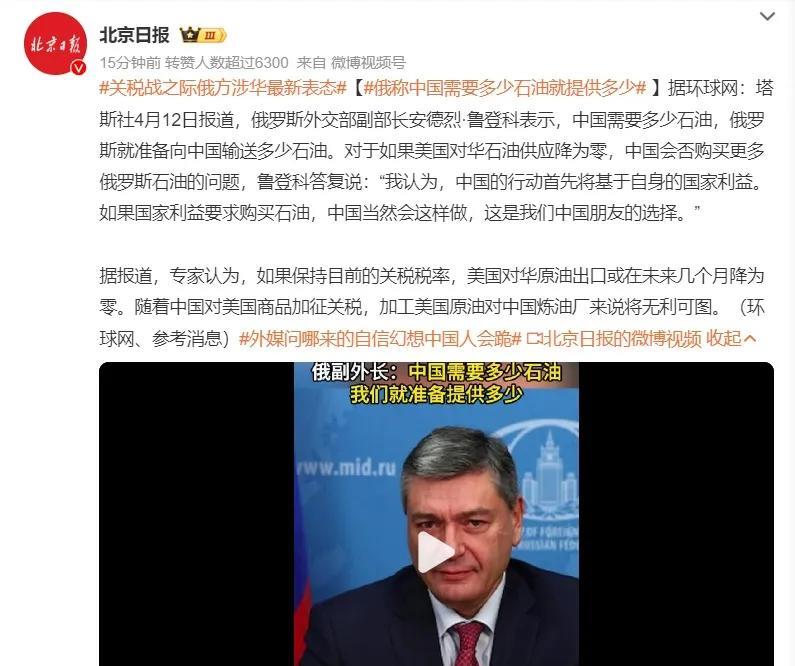
中美贸易战消息2024年,中国从俄罗斯进口了10847.13万吨石油,总金额是
86评论
73点赞

多亏贸易战,国内才揪出来这么多内鬼!某军工研究院的卫某,将1000多份机密文件出
88评论
57点赞



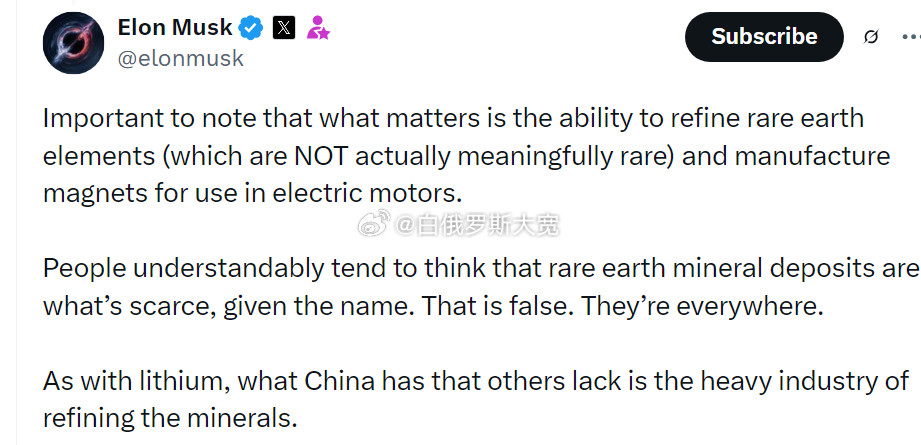
中国暂停了六种稀有重金属的出口,想要得申请许可证。4月13日,马斯克发推:稀土无
25评论
15点赞







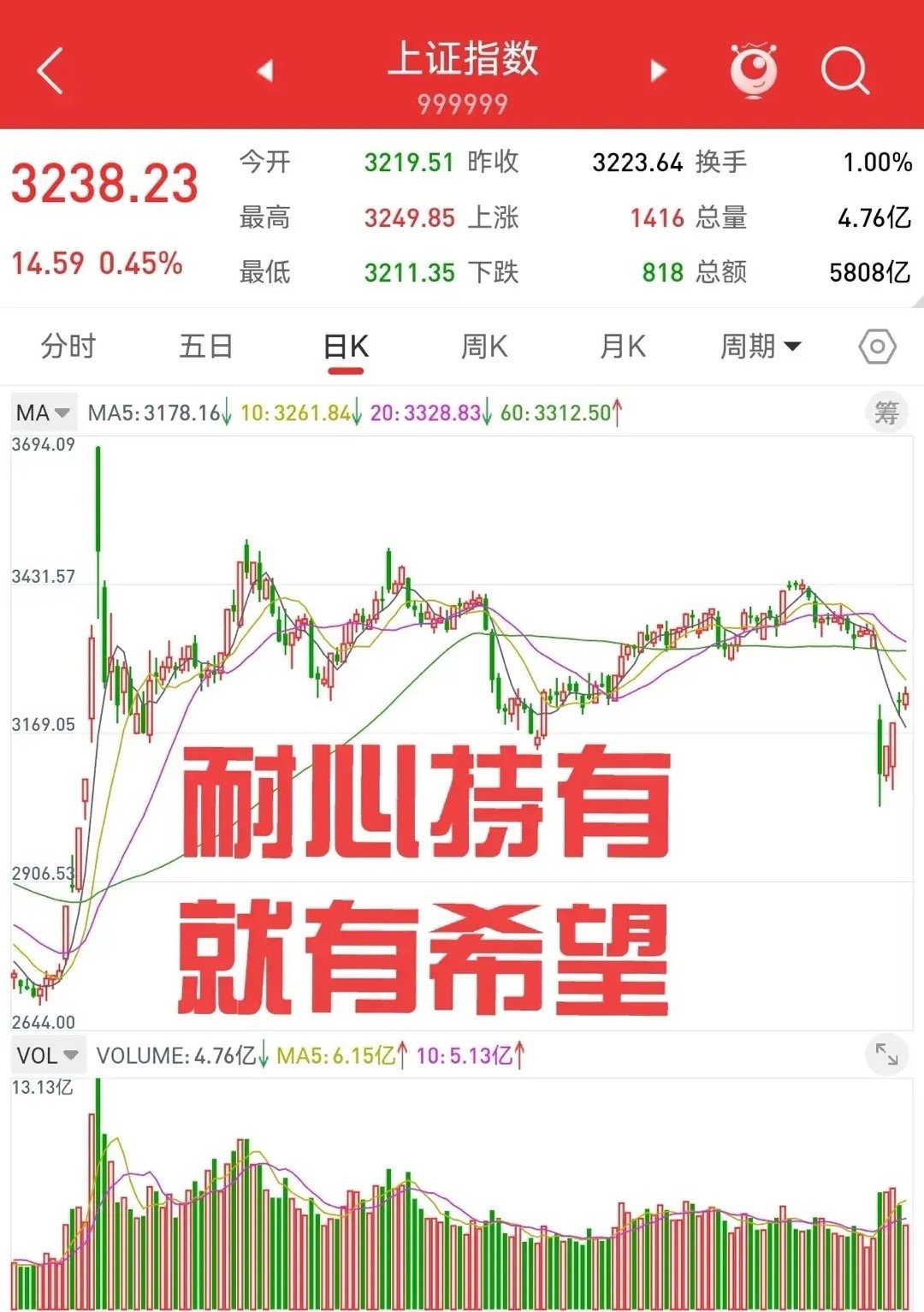
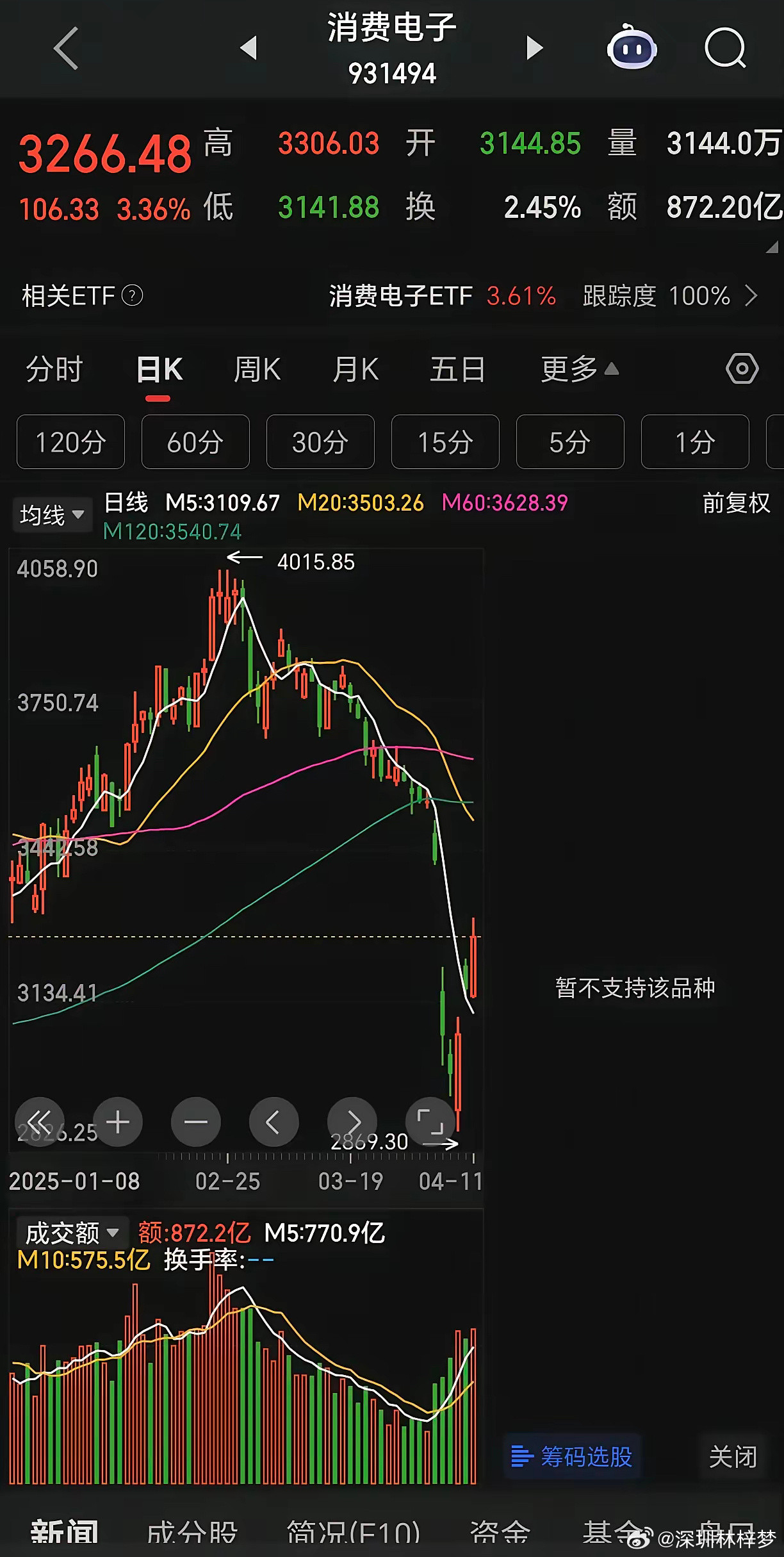

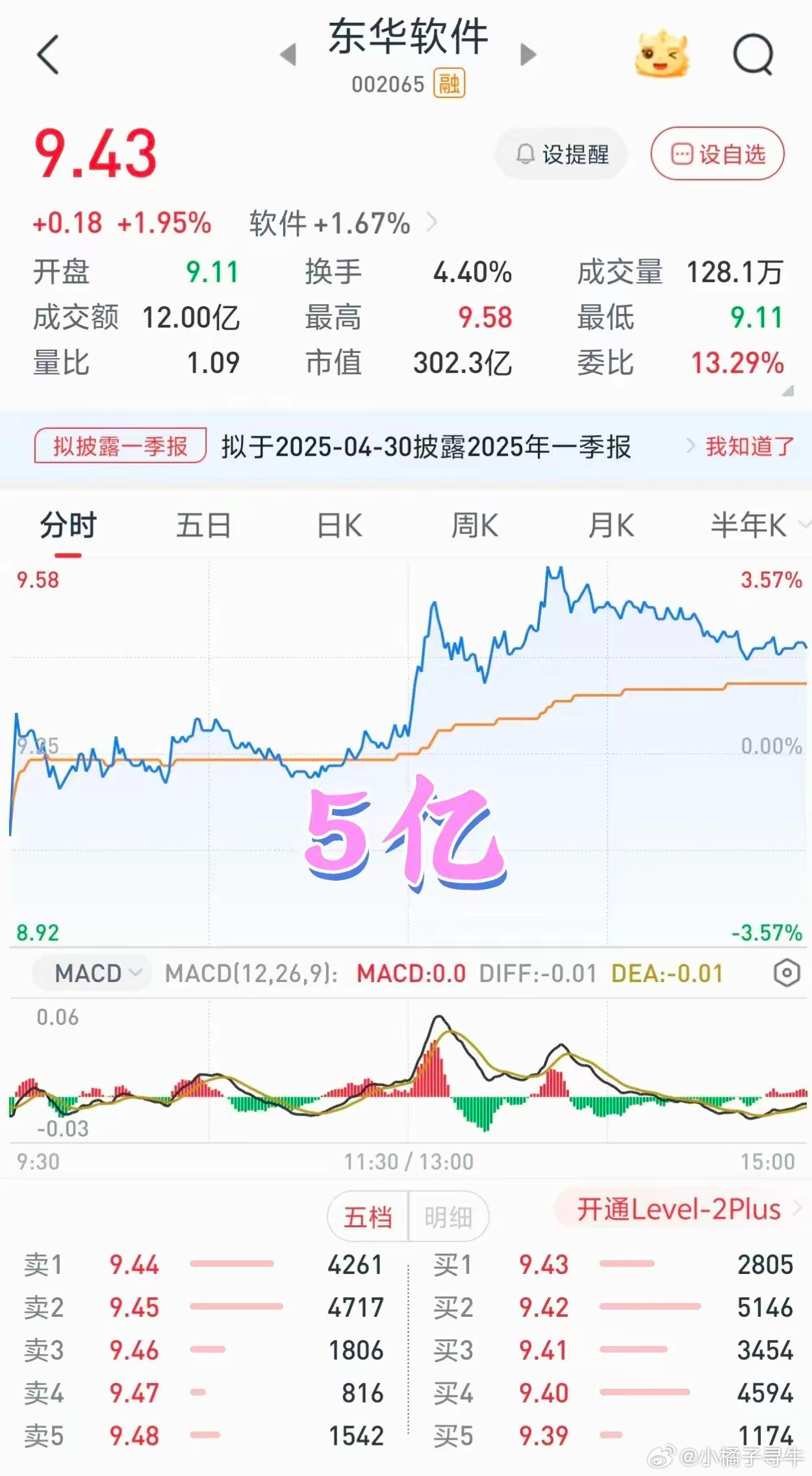

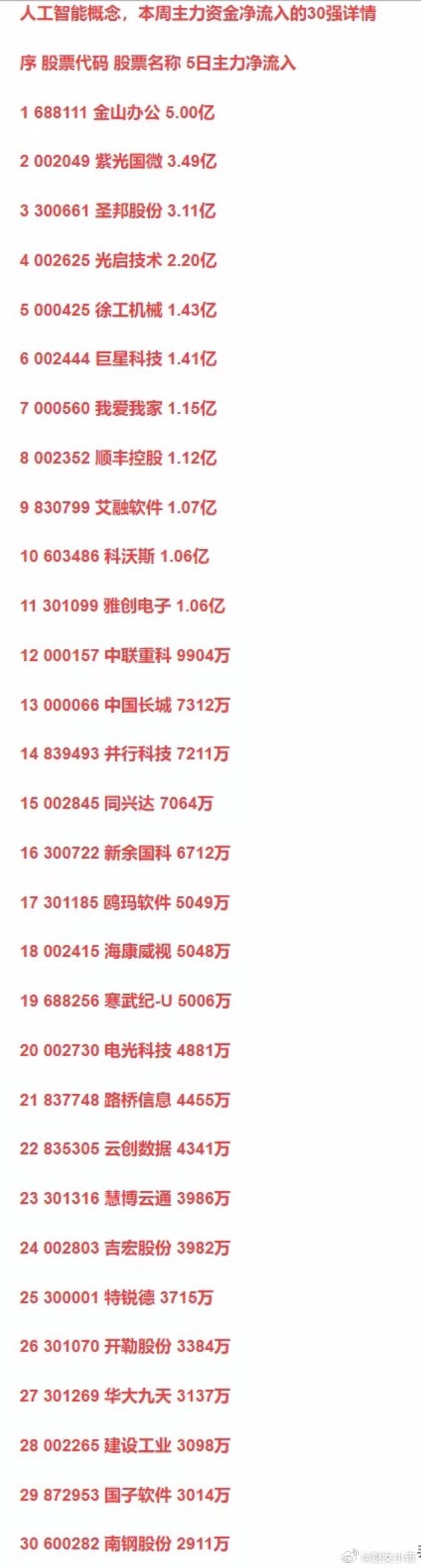


美国财长贝森特近几日呼吁东方大国不要抛售美债,他给出的理由是:美债和美元近几日都
37评论
16点赞
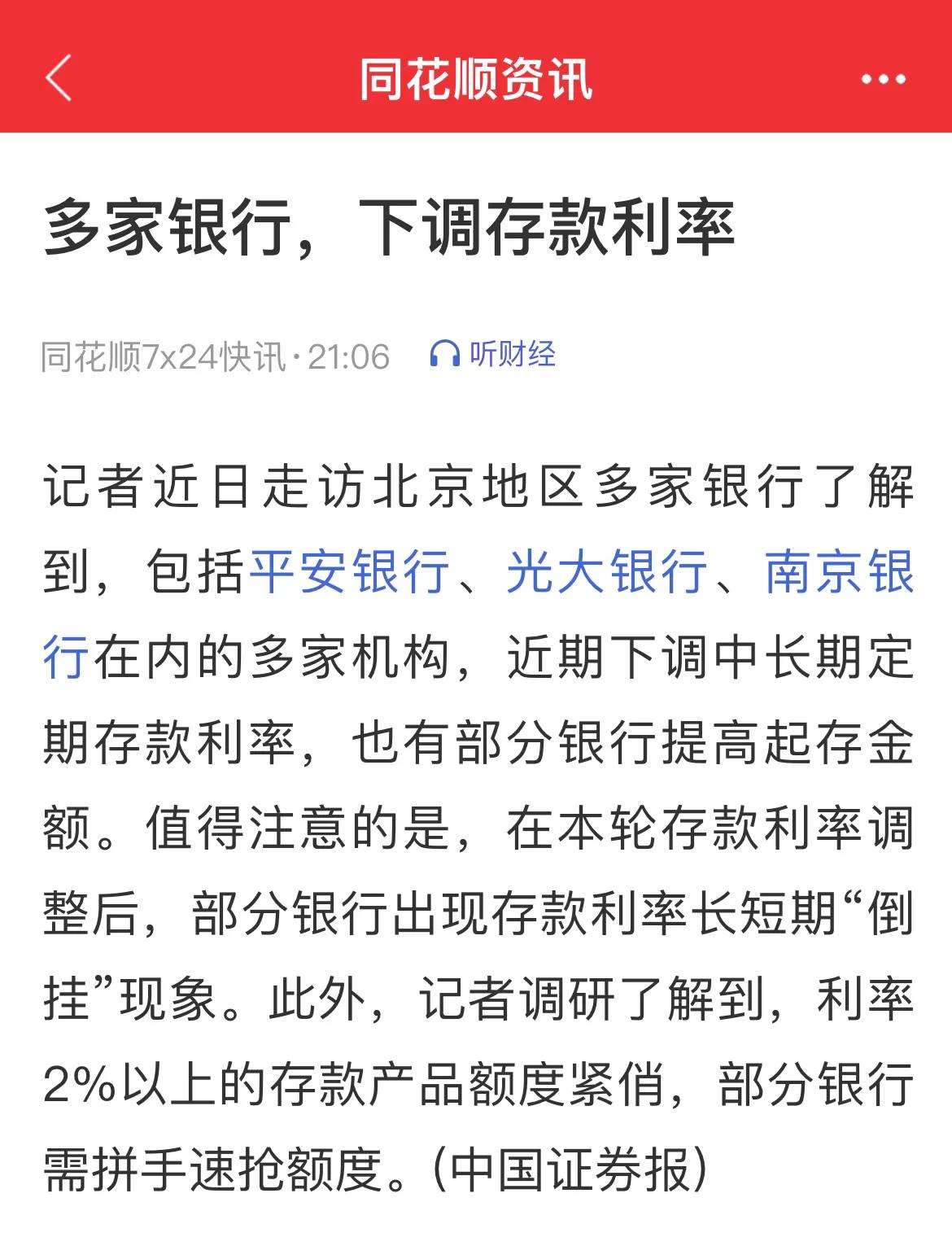
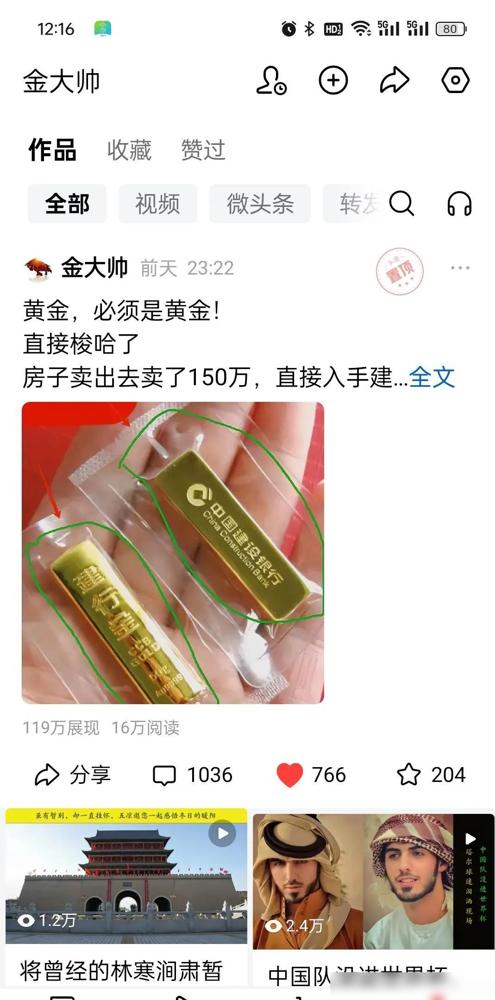
这哪是炒黄金?简直是玩命!上周五国内金价跌到712元/克,杭州张大哥两个月亏了七
13评论
12点赞
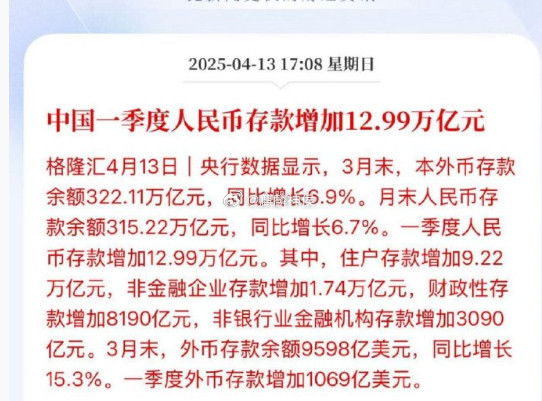



6G卫星通信产业链概念股
2点赞