1. 需求:AI时代的矛盾:
Moore's Law v.s. Scaling Law
1.1AI新时代,算力需求爆发式增长
NLP领域突破,AI内容生成成为热点。自1950年图灵测试以来,人工智能工具和技术已经取得了令人难以置信的进步,其中许多突破性进展一直在业界的关注下被频繁发掘。2015年CV类视觉识别超过人,可部分替代人眼/耳,主要用于物体识别和发现,催生了千亿级智能安防产业。2022年底基于 NLP的ChatGPT学会思考习,用于理解和生成,GPT-4已初步具备自主学习和思考能力,在文本/图像/音频/视频/代码等脑力劳动场景中已达到人类80%的水平,可替代较高端脑力劳动工作。2023年以来,应用于各类场景的大模型层出不穷,涉及百姓生活的方方面面,AI内容生成、知识传递已成为当前行业热点。

Scaling Law尚未见顶,AI时代算力需求巨大。自2022年ChatGPT问世以来,全球正式进入AI时代,各类大语言模型层出不穷,催生巨大的算力需求。所谓的尺度定律(Scaling laws)是一种描述系统随着规模的变化而发生的规律性变化的数学表达。而大语言模型的尺度定律描述的是模型的性能与模型的参数量大小、训练模型的数据大小、训练模型使用的计算量之间的关系。简单来说可认为模型参数量越大,训练模型所用的数据越多,训练模型的计算量越大,对应模型的性能越好。因此通常也用Scaling Law来表征算力需求的规模。据华为算力白皮书测算,当前大模型的参数量仍在扩大,多模态数据成为大模型训练的主要数据,对算力需求的拉动将会是普通文本数据的上百倍,由此得出结论:未来大模型算力需求将维持每6个月翻一番的趋势直到2030年,也即是维持每年翻4倍的高速增长。当前除了大模型的训练需求,各类推理应用同样呈现快速发展趋势,如办公应用中通过文字生成极大提升公文,邮件,新闻等编辑效率;软件开发中辅助代码生成以提升开发人员的工作效率;多媒体设计领域图像、视频生成类功能已嵌入各大主流设计软件。未来在训练+推理的双轮驱动下,整体市场规模将会持续高增。

1.2摩尔定律趋缓,芯片单位面积的算力提升困难
摩尔定律趋缓,芯片晶体管数量提升愈发困难。摩尔定律的核心内容为:集成电路上可以容纳的晶体管数目在大约每经过18个月便会增加一倍。自1965年摩尔定律问世以来,这一定律在过去几十年里一直被证实,推动了计算机技术的快速发展。然而,随着技术的不断进步,摩尔定律也面临着物理极限的限制,使得单芯片的算力提升速度趋缓。芯片的算力与其所容纳的晶体管数量直接挂钩,可简单拆分为晶体管密度和芯片面积的乘积。当前这两个变量的提升速度都趋缓或停止,单纯从摩尔定律已无法提升芯片性能,需要通过如Chiplet、3D IC等先进封装延续摩尔定律。

晶体管密度:过去30多年,晶圆制造的制程从3um提升到3nm,尽管每代制程下的晶体管密度依旧在提升,但是提升速度越来越慢。据Tech Centurion数据,台积电16/10/7/5nm制程对应晶体管密度分别为每平方毫米28.2/60.3/96.5/171.3百万个。另外据Tech Insights数据,台积电N3/N2/14A制程对应晶体管密度分别为每平方毫米283/313/392百万个,由此可以测算各代制程下晶体管密度的复合增速。据我们测算结果,当制程提升到3nm以后,晶体管密度的复合增速将降为个位数,制程提升对芯片晶体管数量增加的帮助趋缓。

芯片面积:在芯片制造的过程中,由于受到最大光刻面积的限制(reticle limit),单芯片的面积不能无限制增加,当芯片面积超过858mm2时,一次曝光无法覆盖整个芯片,此时需要多次曝光进行拼接,对应的工艺难度将大大提升,芯片良率将显著降低。以英伟达产品为例,早期的Tesla K40芯片面积仅为551mm2,到H100时芯片面积已经增加到814mm2,并且近三代产品的芯片面积都没有超过858mm2。由于增加芯片面积以提升整体晶体管数量的方式在GPU产品这类大芯片领域逐渐失效,
英伟达B200芯片才会采用Chiplet的方式将两颗B100芯片进行拼接,以此增加横向面积。若在横向空间受限的领域,则只能通过垂直堆叠进行算力的扩充,3D IC这一先进工艺由此而生,在不增加横向面积的条件下,增加芯片晶体管密度


►►►
2. 摩尔定律趋缓,
3D IC延续芯片垂直堆叠之路
2.1 3D IC:垂直堆叠,续写摩尔定律
何谓3D IC?
3D IC(three-dimensional integrated circuit)平台是一种新型的集成电路技术,它将多个芯片堆叠在一起,通过垂直连接实现互联。3D IC通常是指具有多个器件层的IC封装,芯片设计人员可以通过在晶体管和功能模块尺度上的互连来优化集成电路结构。不同器件层上集成电路之间的互连长度可以从毫米级别减少到微米级别,使不同层集成电路之间的互连信号的传播速度与同一个集成电路的一样快。随着摩尔定律的逐渐失效,缩小芯片尺寸的挑战日益艰巨。但随着新工艺和技术接连涌现,芯片设计规模仍在持续拓展。通过3D IC,可以将硅晶圆或裸晶垂直堆叠在同一个封装中,与传统的二维封装相比,3D IC平台具有更高的封装密度、更低的功耗和更高的性能。

多种3D互连形式,适用于不同应用场景。广义来说,裸芯片或者晶圆在纵向进行堆叠就可以认为是3D互连,互连的形式包含键合金丝连接(Wire Bonding)、封装堆叠(Package on Package,PoP)、TSV硅通孔(Through Silicon Via)等。严格来讲,Wire Bonding形式的互连属于传统封装,多应用于闪存、分立器件等低传输、低算力的场景;PoP形式的互连通过球栅阵列将多个已经封装好的芯片进行进一步的连接,一般用于手机DRAM和SoC之间的连接;TSV硅通孔形式的互连则更多为裸芯片与晶圆/晶圆与晶圆之间的连接,整体结构在同一个封装中,多应用于CMOS、HBM等相对传输速率较低的场景。

3D IC在存储领域早已量产,未来应用领域广阔。Wire Bonding互连形式作为3D IC的初级形态,早已广泛应用于存储领域,通过将DRAM颗粒进行垂直堆叠,颗粒之间采用固晶胶/固晶膜进行粘接固定,再通过键合金丝进行各个DRAM颗粒的连接通信,最后形成多种容量大小的DRAM模组。而在CMOS领域,通过晶圆-晶圆的键合方式,可以将图像传感器和图像处理器进行纵向集成。在高性能计算(HPC)领域,通过TSV硅通孔将多层DRAM进行堆叠互连,实现高带宽高传输的HBM产品,助力AI大模型的训练与应用。在CPU架构方面,AMD通过TSV硅通孔将SRAM和CPU进行纵向连接,增大SRAM的容量,降低整体系统功耗。未来,HBM4有望置于CPU/GPU上方,减少中介板带来的额外成本,提升系统性能。

与2.5D同为最高端先进封装,3D封装突破摩尔定律。3D封装和2.5D封装的主要区别在于:2.5D封装是在中介层(Interposer)上进行布线和打孔,而3D封装是直接在芯片上打孔和布线,连接上下层芯片。两者同为目前最高端的封装形式,2.5D封装根据中介层的特点可分为全硅中介层、RDL层以及局部硅中介层。台积电据此推出了CoWoS系列封装,三星则推出I-Cube/H-Cube系列封装。而3D封装在不同应用领域中具有不同的产品形态,海力士/三星/美光等存储原厂采用3D封装发布了HBM高带宽存储,台积电/英特尔/三星等晶圆厂则是推出SoIC/Foveros/X-Cube等多种形式的逻辑产品。摩尔定律预测,集成芯片上的晶体管数量每两年翻一番。几乎所有的高性能计算系统都是如此,包括CPU、GPU、FPGA、移动AP和特殊的人工智能加速器。尽管晶体管数量通过制程提升得以继续增加,但不断升级的AIGC需要新的高性能计算,越来越大的系统推动行业超越目前的单片SoC。因此,3D封装是突破摩尔定律限制的重要方式。
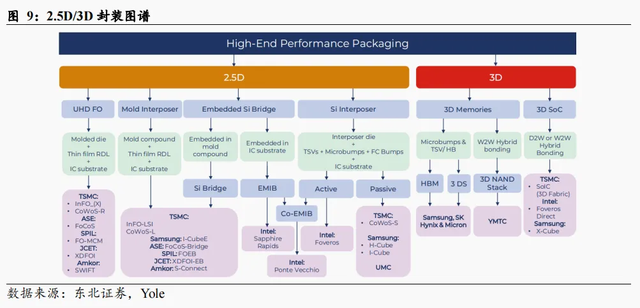
2.5D/3D封装市场规模稳定高增,成长空间可期。据Yole数据,2022年全球2.5D/3D 封装市场规模约为90.13亿美元,预计2022-2028年的复合增长率将达到20.1%,2028年全球2.5D/3D 封装市场规模将达到270.32亿美元。2022年全球2.5D/3D封装出货量达到45.08亿,预计2022-2028年的复合增长率将达到15.3%,2028年全球2.5D/3D 封装出货量将达到105.78亿。


2.2 3D IC关键技术,助力芯片纵向高密度互连
2.2.1 TSV:打开芯片纵向延伸之路
TSV为3D IC核心技术之一,铸造信号高速传输通道。硅通孔(Through Silicon Via, TSV)互连技术是指在硅中介板(Interposer)、晶圆或裸芯片上制作微通孔,然后填充导电材料以实现芯片之间的互连导通;载体、晶圆或裸芯片在硅通孔间进行相互连接即可成为硅通孔互连。通过TSV工艺,可以获得尺寸更小、质量更轻的封装,大幅度提高封装密度;显著减少互连长度,增加信号传输速度;有效降低功耗;获得更宽的数据位宽,相应获得更宽的带宽。但是由于工艺流程复杂繁琐、技术难度高、设备昂贵、成本高,目前 TSV 互连技术大多数应用在高端产品上。TSV作为实现3D IC系统各个层次之间通信的关键技术,其制造步骤主要包括蚀刻、隔离、金属化以及表面平坦化四大过程。

TSV刻蚀:打开芯片纵向连接之路
TSV孔是高深宽比的硅蚀刻,也称为深硅蚀刻。等离子体硅蚀刻法是在20世纪80年代末和90年代为微机电系统(MEMS)而开发的,该技术已改进为TSV蚀刻技术。最常见的TSV蚀刻工艺为时间多路复用交替工艺,也被称为Botch工艺,它交替进行侧壁钝化和蚀刻步骤。Botch蚀刻工艺的蚀刻速率为5~10μm/min,对光刻胶的选择性为50-100。该过程通过以下步骤进行:(1)利用六氟化硫作为蚀刻剂的Si蚀刻;(2)与C4F8气体结合,生成良好的钝化膜,在下一个硅蚀刻步骤中防止横向Si;(3)利用定向离子轰击法在六氟化硫等离子体中进一步蚀刻硅层,形成深硅蚀刻。然后,通过氧气和氩等离子体清洗钝化层。然而,该工艺不可避免地会导致侧壁扇形粗糙度,进而影响电介质、阻挡层和Cu种子层的覆盖范围,从而导致漏电和可靠性问题。因此,随着TSV尺寸的减小,侧壁扇形需要被最小化。

TSV隔离:隔绝信号传输干扰
TSV刻蚀后,需要使用化学气相沉积(CVD)在侧壁内镀上介电膜来达到电绝缘的目的,然后进行屏蔽层和种子层的沉积。典型的介电膜层的厚度范围在0.1-3.0μm之间。介电层的工艺要求包括良好的步长覆盖和均匀性、无泄漏电流、低应力、较高的击穿电压,以及由于不同的TSV而造成的处理温度限制。二氧化硅或氮化硅通常用作等离子体增强化学气相沉积(PECVD)或次常压化学气相沉积(SACVD)的介电层。然而,当TSV的直径小于3μm时,介电层需要通过原子层沉积(ALD)来沉积。下图展示了尺寸为3×50μm的TSV通孔附近,ALD工艺下介电氧化层覆盖在TSV周围的情况,侧壁和底部氧化层厚度约为95 nm。

介电层沉积后,需要在温度为400℃的退火过程中沉积阻挡层,以防止Cu原子从Cu TSV中扩散。此外,阻挡层还是介电层和铜层之间的粘附层。作为阻挡层的常用材料有钛、钽、氮化钛和氮化钽。通过PVD工艺可以沉积钛和钽,这种方法在工艺过程中具有低温的优点,但对于高深宽比的刻蚀,其步长覆盖率较差。因此,往往需要沉积较厚的金属阻挡层,以克服较差的台阶覆盖范围,但是生产成本会增加。氮化钛和氮化钽阻挡层的沉积多采用CVD方法,具有均匀性好的优点,但需要较高的加工温度。
种子层的导体材料应与最终填充所用材料相同。常见的材料是铜、钨和多晶硅。由于铜具有很低的电阻率,通常填充铜进行上下互连,但是铜很容易扩散到下面的介电层中,因此必须使用阻挡层来防止扩散。种子层的沉积可以通过多种工艺进行,其中PVD因其沉积层纯度高、成本低,是最常用的工艺方法。CVD工艺也可以进行阻挡层和种子层的沉积,因为其非常低的粘附系数会导致很好的共形性。然而,CVD薄膜通常比PVD薄膜有更多的杂质,从而导致更高的电阻率。除了薄膜性能外,CVD工艺的成本通常也高于PVD。薄膜纯度、抗性、密度和成本的结合决定了PVD方法在屏障层和种子层的沉积方面优于CVD方法。
TSV金属化:铸造信号传输通道
TSV金属化过程即通孔的填充过程,而电镀(也称为电沉积或电化学沉积,ECD),由于成本较低,是TSV填充的首选工艺。铜具有优越的电学性能,如高电导率和相对较低的电迁移率,是TSV填充中最常见的材料。电镀铜需要在TSV通孔的底部和侧壁上提前镀上种子层,一般情况,在铜自下而上电镀过程中,底部填充速率慢于顶部填充速率。镀层溶液的成分对沉积质量起着非常重要的作用,阻挡层和种子层的质量对于防止镀铜层中的空隙至关重要,而铜覆盖层显著影响后续制备工艺。

TSV表面平坦化:多层堆叠关键环节
晶圆键合需要表面具有非常高的平整度,因此需要用化学机械抛光(CMP)对表面进行平整化。CMP材料去除率会影响整体的成本和性能,施加在晶圆上的压力、晶圆相对抛光垫的运动速度、材料性能和浆料组成均会对CMP的速率产生影响。对于TSV工艺,晶圆表面的形貌主要是由镀铜影响。在抛光时,即使在某些区域清晰后仍会继续抛光,以便完全清除铜残留物,但可能导致铜在阻挡层和介质层界面处产生不良凹陷。除了对晶圆表面进行平坦化之外,CMP工艺还用于晶圆的减薄,使得TSV硅通孔得以露出,实现上下层的互连。
2.2.2 键合:助力芯片高效稳定互连
键合是3D IC的另一大关键技术,奠定多芯片稳定连接之基。多个晶圆/芯片形成垂直堆叠,晶圆/芯片之间的连接固定即为键合过程。键合工艺是通过化学和物理作用将两块已抛光的晶圆紧密地结合起来,进而提升器件性能和功能,降低系统功耗、尺寸与制造成本。一般来说,在Wire Bonding的互连形式中,晶圆之间用固晶胶/固晶膜进行粘接固定;在芯片正面-正面连接中或较低互连密度的TSV通孔工艺中,通常用焊球阵列进行连接;在更高密度的TSV通孔工艺中,则会用到混合键合等更精细的键合方式。
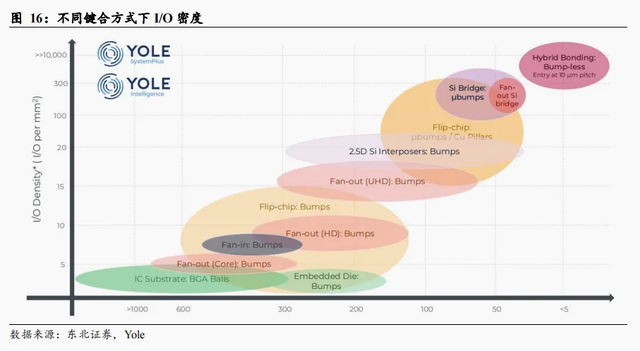
逻辑/存储皆有应用场景,键合方式因地制宜。3D封装的应用场景主要在3D存储和3D SoC,前者通过TSV+微焊球(micro bumps)/混合键合可以制造HBM,一般通过晶圆-晶圆(Wafer to Wafer,W2W)之间的混合键合可以制造3D NAND;后者通过裸芯片-晶圆(Die to Wafer,D2W)/W2W之间的混合键合进行连接。

热压键合(TCB):高精度+低翘曲,应用于多种封装场景
当制程升级到14nm工艺后,基板和芯片的厚度都将成倍下降,热应力下的翘曲效应使得凸点桥接(Solder Bump Bridge)失效异常严重。为了弥补传统回流焊的不足,热压键合凭借更好的贴放精度和极快的加热降温能力,已经广泛用于各种先进封装场景。其主要过程包括:(1)将喷涂了助焊剂的基板固定在真空板上,减小基板随热发生的翘曲形变;(2)Bond Head(贴片头)自带加热源,将芯片迅速加热到临界锡球融化温度;(3)经过相机对位后,Bond Head把芯片精准贴放到基板的凸点阵列区;(4)在基板和芯片的凸点物理位置接触的一瞬间,Bond Head从压力敏感控制转为位置敏感控制,并迅速加热到锡球融化温度以上保持数秒,之后Bond Head迅速冷却,使得上下凸点之间的连接变为固相。

混合键合(Hybrid Bonding,HB):下一代高密度互连首选
混合键合属于铜-铜直接键合,不需要中间材料,是目前高端3D封装主要使用的方式。简单来说,其键合过程包括芯片/晶圆表面CMP、等离子体表面激活、常温下对准键合以及低温退火几大步骤。

混合键合具有以下有点:(1)能够实现最大的I/O密度,从而实现更快的数据传输速率以提高系统性能;(2)可以实现低于10μm的键合间距,使更小的组件和器件能够集成;(3)不需要焊球,在提高性能的前提下没有功率和信号损失,同时扩大带宽和改善信号传输效果;(4)可集成高密度内存,允许在更小的空间中存储更多的数据。与此同时,混合键合具有以下难点:(1)为了达到较好的粘接强度,晶圆表面要求高平整度以及洁净度,防止污染物对粘合过程产生负面影响,从而导致性能和粘接强度降低;(2)互连对齐要求高,对低接触电阻至关重要。错位会导致电气连接不良,从而导致设备性能降低;(3)高退火温度,300-400℃对于内存和逻辑等敏感的高端器件来说仍然过高,可能会导致器件退化和故障;(4)键合前后测试难度较高。
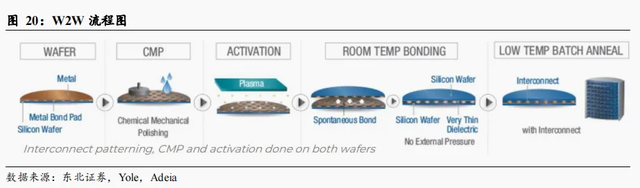
W2W流程示例
以Adeia公司给出的W2W为例,其混合键合过程包含以下步骤:(1)晶圆表面铜衬底沉积(2)CMP表面研磨,介质漏出(3)晶圆表面用等离子体进行活化(4)室温下两片晶圆对准(5)低温退火,上下铜生长连接。
D2W流程示例
据Adeia公司给出的D2W为例,其过程主要包括Die预处理、Wafer预处理、室温键合以及低温退火几大步骤。与W2W不同的是,D2W需要对贴装的芯片进行提前划片,然后对芯片和晶圆分别进行表面激活,再将芯片上的凸点和晶圆上的对应位置对齐并在室温下进行对准键合。

2.2.3 海外大厂全产业链布局,国内厂商发力关键环节
9大工艺环节,海外大厂全覆盖,国内厂商覆盖关键环节。2.5D/3D封装全流程包含深硅刻蚀、光刻、CMP、键合、金属化、绝缘层钝化、夹取、划片、测试等9大工艺环节。目前海外已有完整的供应链,实现全流程覆盖。相对来说,国内企业处于追赶阶段,但也已经实现关键工艺环节的技术布局。设备端来看,由于封装所用到制程相对晶圆制造而言要求低很多,如光刻机、刻蚀机、镀膜设备、清洗设备、CMP等均已实现国产化。如深硅刻蚀环节,中微公司已经可以实现60:1的高深宽比刻蚀,并计划于2025年推出90:1的深硅刻蚀;光刻环节,上海微电子后道光刻机早已量产;CMP环节,华海清科打破应用材料和日本荏原的垄断,成功实现国产替代;金属化环节,拓荆科技ALD产品可在20:1深宽比下实现95%的台阶覆盖率,北方华创的镀膜产品可满足3D NAND的需求。而后端封装过程,精度要求较高的塑封机、倒装固晶机以及研磨切割等设备目前主要采用海外大厂的产品,国内公司在键合领域进展较快,拓荆科技的W2W混合键合产品已通过客户验证并取得重复订单,芯源微临时键合设备早已进入客户端批量销售。


2.3 3D IC后续发展重点:散热&异构集成
芯片堆叠增加功耗密度,催生高效散热需求。尽管3D IC可以通过芯片堆叠在面积不变的前提下提高芯片的晶体管密度,但是其散热要求也比单芯片的散热要求更高,如何高效把热量导出一直是业界关心的重点。为了增强高性能计算领域的芯片散热能力,台积电提出开发新的热界面材料来代替一般的液态金属热界面材料(Liquid Metal TIM,LMT)、集成微型硅冷却器(Integrated Si Micro-Cooler,ISMC)辅助散热以及直接水冷(Direct Water Cooling,DWC)等方案。相比一般的LMT,新的Ox TIM,使得芯片表面热阻相比采用LMT时减少了50%,在大尺寸芯片(>500mm2)领域提供了kW级散热解决方案。与此同时,DWC方案将促进液冷领域从板级向芯片级发展。

满足高速率+低功耗需求,硅光集成趋势已成。在AI高速发展的背景下,硅光集成凭借高速率+低功耗的优势,有望成为数据中心互连的重要方案之一。目前大多采用高速铜缆/光模块来进行数据中心组网,但是前者存在信号损失而只能用在短距传输,后者则由于需要经过多个转换环节导致较高的能耗,而光学共封装(Co-packaged Optics,CPO)可以实现信号无损失的高效传输。相比一般的光模块,CPO将光学引擎和芯片直接集成在载板/硅中介板上,大大减少了电子传输过程中的能耗。3D IC不仅可以将硅基芯片进行高度集成,同样也可作为硅光集成的重要平台,实现异构集成。

►►►
3 海外大厂竞相布局,逻辑/存储皆有应用
3.1台积电SoIC:目前唯一大规模量产的3D封装平台
异构芯片集成助推芯片工艺发展,SoIC实现优异互连性能。台积电的3D SoIC工艺平台是推进缩小尺寸和提高性能的异构芯片集成领域的关键技术,同时也是目前唯一大规模量产的3D封装技术,具有超高密度垂直堆叠的高性能、低功率和最小的RLC(电阻电感电容)。SoIC将有源和无源芯片集成到一个新的系统中,与单一SoC具有相同的电气特性,从而可以实现更好的外形和性能。SoIC技术通过I/O逻辑芯片和核心电路芯片的叠加,实现SoC划分和重新集成,使系统具有更好的成本和性能。
SoIC还提供了设计和集成的灵活性,在不同的技术节点、材料、功能和芯片尺寸上的异构芯片之间进行混合和匹配,以创建真正的异构3D IC。通过直接芯片对芯片互连,可以实现优越的功率完整性、信号完整性和更低的通信延迟,超过20Tbps的内存带宽,以支持未来的HPC、AI、5G和边缘计算应用。

兼容各种封装工艺,SoC外观与异构集成功能兼备。SoIC将同质和异构芯片集成到一个类似SoC的芯片中,占地面积更小,轮廓更薄,可以整体集成到任何先进封装平台中,如倒装芯片(Flip Chip,FC)和晶圆级局部硅中介层(Wafer Local Silicon Interposer,WLSI,也被成为CoWoS)。从外观上看,SoIC就像一个通用的SoC芯片,但却嵌入了所需的异构集成功能模块。

相比传统堆叠封装,SoIC具有更高的键合密度。台积电已经在InFO_PoP平台上实现了业界第一个具有逻辑堆叠集成的SoIC。与典型的3D IC_PoP相比,SoIC嵌入式InFO_PoP提供了更高的互连I/O密度、更低的功耗和更薄的封装轮廓。SoIC技术可以显著提高键合的密度,达到10K/mm2的水平,对应键合尺寸小至10μm以下。在倒装芯片封装中,受限于焊球材料的限制,键合密度约为SoIC键合密度的1/100。与一般的2.5D/3D IC相比,SoIC也有超过10倍的键合密度。

多性能指标优异,SoIC优势明显。系统性能,如互连凸点/键合密度、电气性能和热性能,对于满足移动和HPC系统对高计算效率、数据带宽、低延迟、每比特数据操作低能耗的要求至关重要。相比2.5D、一般的3D IC,SoIC在诸多性能上均有明显优势。
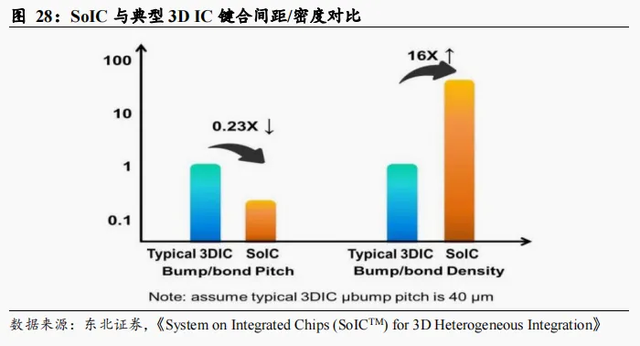
高密度键合,实现微距互连。在键合密度方面,据台积电分析,假设典型3D IC的焊球间距是40μm,归一化尺度下SoIC的键合间距仅为采用微焊球的3D IC的23%,密度为16倍。
低插入损耗,RCL性能均优于传统3D IC平台。在电气性能方面,低插入损耗对于实现两个SoC芯片之间的高速、高频数据传输的互连性能至关重要,特别是在5G通信应用中。在频率小于30GHz时,SoIC几乎没有插入损失,而倒装芯片封装随着频率的增加,插入损失不断增大。除了插入损耗,降低RC(电阻电容)延迟和IR(电流电阻)损失,对保证信号完整性和功率完整性非常重要。在归一化尺度下,SoIC和采用微焊球的3D IC在2 GHz的时候,前者电阻R仅为后者的8%,电感L仅为后者的1%,电容C仅为后者的8%,也即SoIC比采用微焊球的3D IC在RC延迟方面性能高出156倍,在IR损失方面性能高出12.5倍。

聚焦能耗与热管理,SoIC表现优异。在能耗与热管理方面,热管理在异构系统集成中变得越来越重要,特别是对于3D芯片的堆叠。超过允许的工作温度,芯片可能无法正常工作,造成严重的漏电流问题。一般来说,垂直堆叠的芯片在散热方面都存在较大挑战,单位面积的功耗降随着堆叠的芯片数量成倍增加,因此如何实现较好的散热效果一直是业界关心的核心问题,同时催生了一系列的芯片散热方案,包括芯片级、板级、系统级等等。与典型的3D IC堆叠相比,SoIC在本质上提供了更高的金属路径密度,使热流能够向上和向下流动,从而可以更有效地消散热流量。据台积电分析,SoIC在单位比特数据上的能量消耗仅为采用微焊球的3D IC时的9%,在热阻上为50-80%。在固定的功率下,单位数据花费的能量越少,可以传输的数据量就越多。

3.2 英特尔Foveros:多芯粒堆叠的典型代表
以多芯粒堆叠为核心,布局多种工艺平台。在3D封装领域,英特尔在2019年就推出第一代Foveros工艺,通过高密度、高带宽和低功耗的互连方式,将多个制程工艺制造的模块组合成复合芯片,并于今年1月25日宣布正式进入大规模生产。作为英特尔IDM 2.0商业模式的重要组成部分,Foveros与EMIB(嵌入式硅桥技术)、Co-EMIB(EMIB与Foveros混合使用)共同组成其先进封装领域堆叠工艺平台。

性能较EMIB大幅提升,Foveros未来可期。Foveros工艺下,焊球间隔为25-50μm,密度约大于400-1600/mm2,每bit数据消耗能量0.15pJ,各参数均优于EMIB封装工艺。此外,为进一步扩展Foveros工艺平台,英特尔发布了Foveros Omni和Foveros Direct工艺,其中Foveros Direct工艺首次采用混合键合,键合间隔小于10μm,密度大于10000/mm2,每bit数据消耗能量大于0.05pJ。
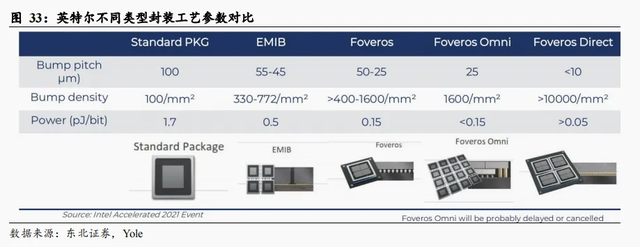
I/O die与逻辑die垂直堆叠,发力消费电子领域。Foveros 3D封装是英特尔的有源中介板技术,在有源硅中介板中集成了低功耗的I/O,通过硅通孔和顶部堆叠的高性能计算逻辑芯片形成电气互联。在这一设计下,每bit数据传输的功率非常低。有源硅中介板包含了传输信号及能量的硅通孔和路径,同时集成了平台路径控制器(PCH,英特尔于2008年起推出的一系列芯片组,取代以往的I/O路径控制器)或者I/O。第一代Foveros工艺通过间距为50μm的微焊球实现了10nm逻辑die和22nm I/O die的互连,目前最新酷睿Ultra系列产品Meteor Lake已经基于Foveros Direct正式量产。除此以外,在移动/平板电脑SoC等低功耗领域,三星Galaxy Book S、微软Surface Neo和ThinkPad X1在2020年就搭载了使用英特尔Foveros工艺的Lakefield处理器。


3.3 三星X-Cube:“超越摩尔定律”的异构集成技术
以延续和扩展为基,开辟“超越摩尔定律”技术方向。芯片开发历史上占主导地位的集成技术演进方向包括了“延续摩尔定律”(More Moore)和“扩展摩尔定律”(More Than Moore),前者追求的是尽可能缩小芯片上的晶体管和连线的尺寸,此种做法实现了计算和电子技术的革命性发展。然而,随着市场对计算能力的需求激增,芯片上需要集成的晶体管数量越来越多,“延续摩尔定律”已经达到了自身极限;后者追求的是创建专业化和多样化的芯片架构,以更好地适应广泛的功能需求。三星开发人员基于这两大技术方向,开辟了“超越摩尔定律”(Beyond Moore)的技术方向,即先进异构集成技术,将多个分别制造的芯片组件集成到单个封装内,并能简化和改进整个封装过程。先进异构集成技术可显著提高生产效率和产品性能,以更少的成本实现更多产能,达到事半功倍的效果。

三大先进封装技术,奠定晶圆代工未来。三星基于“超越摩尔定律”方法的异构集成技术,以及在晶圆代工业务中的实践。沿着水平集成和垂直集成两种方向,三星先后研发出三大先进封装技术:I-Cube、H-Cube和X-Cube。其中I-Cube是一种2.5D封装解决方案,其中的芯片并排放置在中介层上。为提高计算性能,I-Cube的客户通常会要求增加中介层面积。对此,三星推出两种I-Cube方案:I-CubeS和I-CubeE。H-Cube,全称为“混合式Cube”(Hybrid Cube),是三星推出的另一种2.5D封装解决方案。该方案抛弃了大面积的ABF基板,采用面积较小的ABF基板或FBGA基板叠加大面积的HDI基板的方式,能够为客户带来先进的PCB解决方案,其性能更优、封装成本更低、PCB供应链管理也更方便。3D IC封装通过垂直堆叠组件,使用更短的互连线长度,进一步提高了性能,实现了超高垂直互连密度和更低的寄生效应,同时节省了大量芯片上的空间。X-Cube技术通过3D集成大幅降低大型单片芯片的良率风险,以更低的成本实现高系统性能,同时保持高带宽和低功耗。三星基于微凸块的3D IC技术实际上是为HBM而开发,并成功用于生产数千万个HBM。这种3D IC技术可谓经过大规模生产验证且具有成本效益。而正在准备的无凸块混合铜键合通过消除接头间隙,提供了更高的互连密度和热性能。


3.4 典型逻辑芯片案例:AMD 3D V-Cache
垂直堆叠高速缓存,提升CPU和内存间传输速度。AMD 3D V-Cache是AMD新推出的处理器技术之一,它使用了垂直晶体管技术将高速缓存(L3 Cache)集成到处理器芯片的底部。这种技术可以大幅提高处理器的性能和效率,同时还可以在不增加电源消耗和散热负担的情况下实现更高的频率。具体来说,AMD 3D V-Cache将64MB的L3高速缓存集成到处理器芯片上方,这比以前的处理器要多出约1.5倍的缓存大小。这使得处理器在进行复杂计算或执行大型应用程序时可以更快地访问存储器,从而提高整体性能。此外,AMD 3D V-Cache 还可以减少处理器与内存之间的延迟,进一步提高响应速度。

多级缓存结构,芯片面积限制缓存容量增加。在CPU中有三级缓存:L1、L2和L3。每个级别之间的主要区别归结为速度和容量:L1最小但也是最快的,而L3慢一点但也是容量最大的。L3缓存可视为一个通用内存池,CPU可以在其中存储指令,L2/L1缓存可以根据需要从中检索或发送内容。 内存池(L3)越大,CPU可以同时存储和快速检索的指令就越多,执行这些指令的速度也就越快。在CPU SoC外部,通常还会连接DRAM作为更大的存储池,实现数据传输的作用。通常来说,L3级缓存是SRAM类型,每个单元由6个晶体管组成,因此集成度相对较低。如果是平面集成的SRAM,受限于芯片面积,不能做到很大容量。因此,如何提升SRAM的容量,成为提升CPU性能的关键点。

基于台积电SoIC,AMD 3D V-Cache大放异彩。AMD的3D V-Cache技术采用台积电的SoIC技术,64MB的L3缓存die通过TSV硅通孔技术与直接Cu-Cu键合技术和下方的I/O die形成互连,两侧再连接最多8个CCD核心,实现了大容量L3缓存与逻辑die的垂直堆叠。

AMD-TSMC合作:新的处理器和新的3D缓存。目前,AMD第三代AMD Epyc处理器和下一代锐龙,都采用了台积电D2W混合键合技术。与2D Chiplet技术相比,连接密度提升了200倍;与微焊球3D封装技术相比,互连密度提升了15倍,能效提升了3倍。


3.5 典型存储芯片案例:HBM
打通存算墙,多芯片堆叠助力高带宽存储。HBM(High Bandwidth Memory)全称为高带宽存储器,这是将多个DRAM颗粒进行垂直堆叠的新型存储产品,可以突破传统冯·诺依曼架构下的带宽限制以及功耗限制。由于HBM距离GPU更近,同时可提供超过1000个位宽,因此GPU与存储之间可以实现快速且高带宽的互连。英伟达H200相较H100,HBM容量增加76%,在GPU不变的情况下,大模型运算效率也线性提升约75%,突显打破存算墙、补足内存短板的重要性!而我国当前在AI算力芯片被锁死之时,通过HBM堆叠突破带宽与容量限制,有望将短板做成长板,提高综合性能。

HBM的制作流程:TSV+3D堆叠
前道芯粒制造+后道堆叠封装,TSV打通纵向连接通道。HBM的制备分为DRAM颗粒的制备以及多个DRAM颗粒之间的垂直堆叠两大步骤。存储原厂在制备HBM所需的DRAM颗粒之前,会先对裸硅片表面进行TSV,这被称之为先通孔工艺过程。由于TSV 孔在产生晶体管之前制作,因此只有已知的无缺陷TSV晶圆可用于后续步骤,并且它允许更高的通孔密度。通孔完成后进行电镀铜填充,便于后续上下层信号连通,经过表面处理后在进行晶体管的制备。前道晶体管制备完成后,在TSV通孔上方电镀出铜柱并植上焊球,采用临时键合将其保护起来。接着通过CMP对晶圆背面进行研磨使得TSV通孔漏出。然后电镀制备铜柱后就完成了单颗DRAM颗粒的处理。最后将多个DRAM颗粒对准,采用TCB的方式将其连接。由于层间存在空气间隙,同样需要填充underfill来保护焊球。最后在表面采用颗粒状环氧塑封料进行塑封,隔绝外部水汽等干扰。

►►►
4. 3D IC的机遇与挑战
4.1 深孔刻蚀为芯片堆叠核心,高密度通孔迎发展新机遇
高密度互连源于高密度通孔,3D IC为深硅刻蚀带来机遇。TSV作为3D IC的核心工艺,如何实现高深宽比、高密度的通孔是整个3D IC高性能的基础。良好的垂直度、超过20:1的深宽比对深硅刻蚀设备以及刻蚀气体/刻蚀液提出非常高的要求,目前中微公司的深硅刻蚀设备可实现60:1的高深宽比刻蚀,并计划于2025年推出90:1的深硅刻蚀设备;江化微、广钢气体、华特气体等公司也已实现刻蚀液/刻蚀气体的国产化。除深孔刻蚀外,如何沉积高质量的介电层/阻挡层/种子层以及致密的铜填充也是TSV的关键环节,多采用PVD/CVD/ALD/电镀等多种沉积工艺。均匀的阻挡层将有效防止信号传输时发生短路,种子层将作为铜填充的基底,致密无缝隙的铜填充是信号稳定高速传输的基础。当前在PVD/CVD/ALD/电镀等沉积工艺环节均已实现设备国产化。未来随着3D IC的发展,深孔刻蚀及后续沉积环节的重要性将稳步提升,为相关产业链带来成长机遇。
4.2 深孔刻蚀为芯片堆叠核心,高密度通孔迎发展新机遇
万丈高楼“平”地起,足够平坦的芯片表面将是垂直堆叠的基础。在建筑领域,只有每层楼都具有极高平整度,才能搭建出足够高的楼层,这在芯片领域更是如此。在TSV工艺后,晶圆表面的形貌主要由镀铜影响。如果在抛光时不能达到足够的平整度或者完全清除铜残留物,将会导致表面出现不良缺陷,进而带来信号完整性、传输时延、散热、漏电等多种问题,影响整体芯片性能。在此背景下催生了芯片表面高平整度需求,带动如CMP设备、抛光液、抛光垫等多种上游发展。
4.3 高晶体管密度带来高功耗密度,芯片散热成为重要挑战
芯片堆叠增加功耗密度,催生高效散热需求。3D IC可以通过芯片堆叠在面积不变的前提下提高芯片的晶体管密度,但同时也增加了芯片的功耗密度,如何高效把热量导出一直是业界关心的重点。传统2D封装多采用热界面材料(TIM)或者金属盖辅助芯片散热,但是这些方法只能将最上面的芯片产生的热量快速导出,位于整个堆叠下方的芯片产生的热量并不能有效导出,芯片散热成为3D IC发展的重要挑战。目前台积电已经提出开发新的热界面材料来代替一般的液态金属热界面材料(Liquid Metal TIM,LMT)、集成微型硅冷却器(Integrated Si Micro-Cooler,ISMC)辅助散热以及直接水冷(Direct Water Cooling,DWC)等方案。半导体热电制冷技术也已应用于消费电子、通信、医疗实验、汽车、工业、航天国防、油气采矿等领域,未来是否能实现HPC领域芯片级应用值得期待。除此以外,TSV通孔也可作为芯片散热的重要方式,通过专门的导热TSV可将底部芯片产生的热量快速传导至芯片表面,加快整体热量导出。

4.4 高密度互连源于高精准度对准,助力芯片信号传输与散热
3D IC具有超高的I/O密度,催生高精度对准需求。相比传统2D 封装,3D IC之所有具有更高的封装密度、更低的功耗和更高的性能,很大程度上是由非常密集的I/O所决定的,而其物理实现形式就是间距极小的焊球/铜柱以及对应的TSV通孔。在芯片键合时,密集的I/O需要极高精度的对准,如混合键合中,I/O的密度可以高达100万个/mm2,也即是单个I/O的间距约等于1um,粗略估算其对准精度将小于100nm(以间距的10%测算)。如果对准精度过低,TSV通孔对接时将出现较大偏差,进行影响信号传输与热量导出。因此,高密度互连催生了高精度的对准需求。
来源:北京集成电路学会

半导体工程师
半导体经验分享,半导体成果交流,半导体信息发布。半导体行业动态,半导体从业者职业规划,芯片工程师成长历程。204篇原创内容公众号
