经常要捣鼓excel的小伙伴们,你们有福了,今天就来介绍下pandas这个强大、开源的数据分析处理工具,直接以“例”服人,没有多余废话,直接就能上手开干。也希望本文能够起到抛砖引玉的作用,让被excel表格处理缠身的你从此着迷pandas,掌握pandas大法可以从此让你高效工作,“人生苦短,我用pandas”。
安装pandas本文的示例基于python3.12版本,首选需要安装pandas依赖库,还需要安装openpyxl以提供excel文件的支持,另外示例中还会展示简单的图表,这里使用的是plotly库,它可以生成交互式的图表。运行如下pip命令可以同时安装这三个依赖库。pip install pandas openpyxl plotly
另外,强烈推荐使用jupyter notebook来运行文中的示例,如果你使用的是visual code编辑器也可以搜索安装jupyter插件直接在编辑器中开启jupyter,jupyter提供了一种交互式的方式来运行python代码,比如你需要读取一个非常大的excel文件,使用jupyter就只需读取一次,后续的代码就可以直接使用读取的数据而不必再次读取,而直接使用python代码方式运行就没有这个便利。如果你不清楚如何安装使用jupyter,建议网上搜索相关指导。
读取excel文件首先需要说明pandas支持的远不止excel这一个类型,它可以读取和写入下图所示的多种类型的数据格式,这里重点以excel为例进行讲解。

pandas处理的数据类型主要是表格型数据,也就是包含行和列的二维数据,在pandas中称为DataFrame类型。
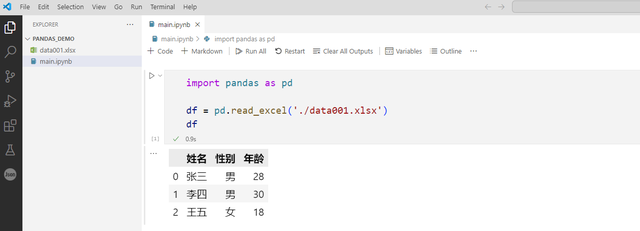
通过调用pandas的read_excel方法可以方便地读取excel文件的数据,并返回DataFrame数据类型,传入的参数为excel的文件路径
# 导入pandas模块,简写为pdimport pandas as pddf = pd.read_excel('./data001.xlsx')df读取当前目录下的excel文件并显示表格数据,这里展示了jupyter文件的后缀和相关文件目录结构,后面将主要展示代码和数据部分。
接下来,我们就通过一个个具体的示例来演示pandas的具体使用。
数据的清洗与过滤在工作中,很多时候你要处理的excel数据可能是来自他人提供的,或者通过各种渠道收集来的,出现数据字段缺失或错误是很常见的,规范整理这些数据需要花费大量的时间。pandas在数据清洗和过滤方面可谓得心应手,这里构造一份简单的人员信息的表格,其中有不少字段是空值。

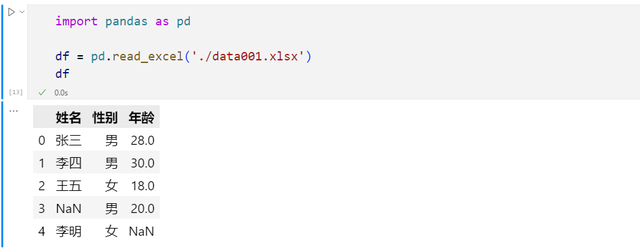
通过pandas读取此excel信息并显示其中的数据,其中空值部分显示为NaN,表示为缺失数据。
dropna方法可以丢弃为空的数据,仅保留无缺失的记录

fillna方法可以为缺失数据提供默认值,比如这些员工信息只是漏填了某些字段,如果直接移除可能影响统计总数

isna方法可以检测某个单元格是否为空值,使用它可以方便地筛选出指定列缺失的数据,以及反数据

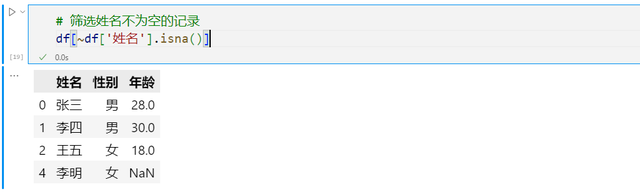
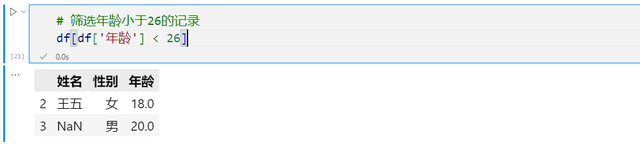
还可以指定其他的筛选条件,比如按照年龄大小
 数据的分组与聚合
数据的分组与聚合通过数据的清洗和过滤处理之后,就需要对数据进行统计分析和呈现了,重新构造一份学生成绩信息的excel表格数据来进行相关的演示。

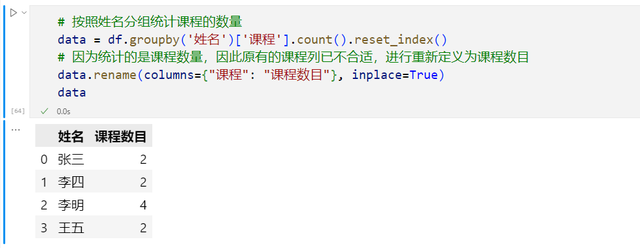
结合groupby和count方法,按照姓名进行分组可以统计学生考试课程的数目,count对课程进行计数
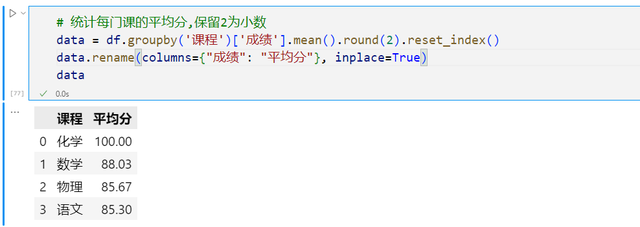
结合groupby和mean方法,按照课程进行分组可以统计每门课程的平均分,mean对成绩一列求平均值
这里使用此数据绘制一个饼图来呈现课程平均分的占比,演示如何使用plotly绘制饼图
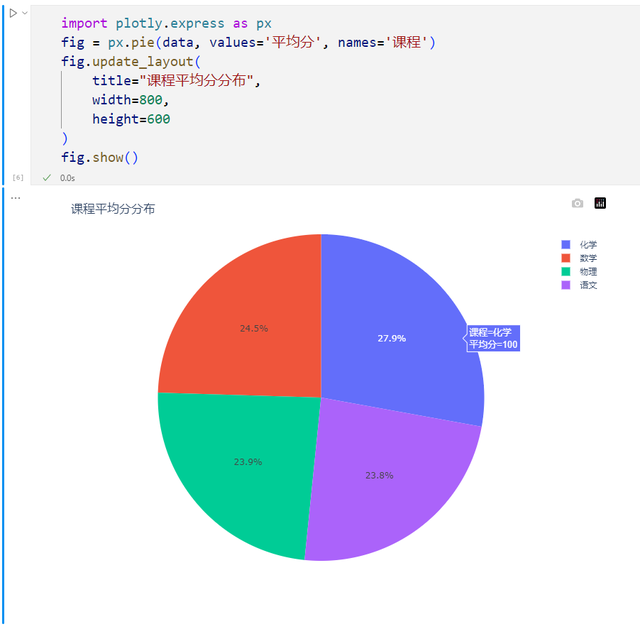
提示:使用plotly绘图如果遇到下面的报错信息,执行pip install nbformat,然后重启内核后重试
ValueError: Mime type rendering requires nbformat>=4.2.0 but it is not installed结合groupby和sum方法,按照姓名进行分组可以统计学生的总分数,sum对成绩一列求和

这里使用此数据绘制一个直方图来呈现学生总分并降序排列,演示如何使用plotly绘制直方图
 数据的合并
数据的合并在数据的过滤和清洗示例中,我们给出了excel文件中瑕疵数据的各种处理手段,还可能存在一份完整的原始数据需要从很多表格中汇总的情况。再次构造两个包含员工的信息excel文件,仔细观察会发现两个表格中姓名和名字是相同的意思,其中一个表格还多了身高这一列,也就是说这两个表格数据并不完全一致,如果这样的表非常多,合并起来岂不是头大,说不定会边干活边爆粗口。
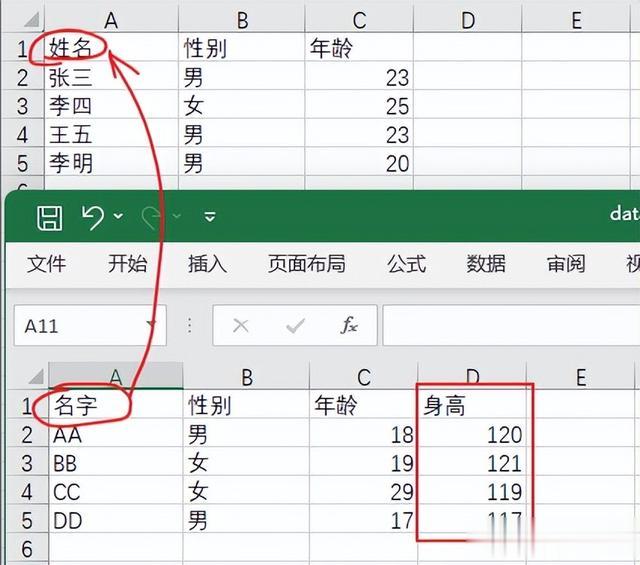
pandas可以轻松搞定这项工作,这里仅以两个表格为例进行演示,首先读取每个表格的数据,至于包含很多表格的情况,只需要使用循环读取即可。

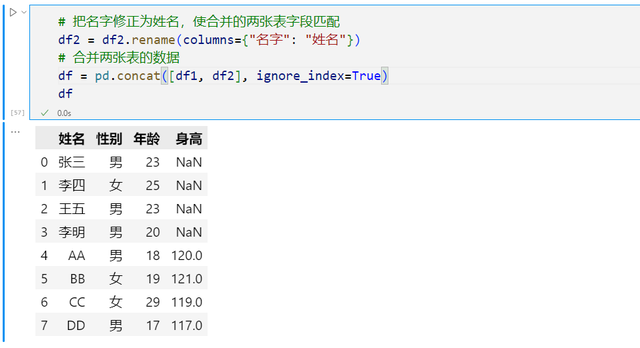
接下来,首先需要做的就是把姓名和名字这两个字段名称统一,将名字改为姓名,然后使用pd.concat就可以把所有读取到的excel数据的列表进行合并了。合并结果如下,不包含身高信息的员工身高一列被填充为空,还需要强调的是合并的表格列名顺序不必一致,只要相同名称就可以正确合并,这就是pandas的强大之处。
 输出excel文件
输出excel文件数据分析完了还需要把分析好的结果输出为excel文件,to_excel方法可以将DataFrame数据写入到excel文件中,传入参数为excel文件的路径。
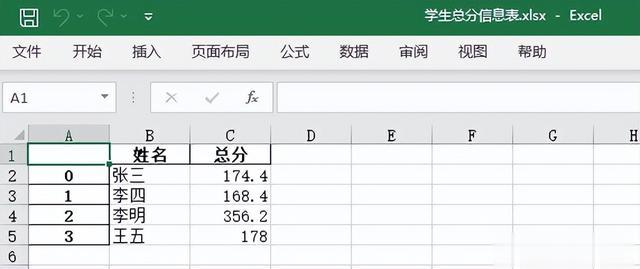
比如前面得到的学生总分信息的数据可以直接写入excel文件

打开excel文件显示结果如下
 参考文献
参考文献[1] https://pandas.pydata.org/[2] https://plotly.com/python/[3] 《利用Python进行数据分析 第2版》Wes McKinney著
