
多模态大语言模型(MLLMs)的发展迅速,成为了人工智能研究的一个关键领域。这些模型不仅能够处理文本,还能够理解并生成视觉信息,使其在许多应用中展现出卓越的潜力。尽管在某些领域取得了显著进展,但在复杂的视觉和数学推理任务上,MLLMs的表现仍有待提高。为此,来自亚马逊、微软、谷歌DeepMind 联合研究团队开发了POLYMATH,这是一个具有挑战性的基准,旨在系统地分析和评估这些模型在视觉复杂场景下的数学推理能力。通过5000个多模态推理问题,涵盖10个不同类别,POLYMATH为MLLMs的认知能力提供了全面的测试平台。
此次研究由一支由各领域专家组成的团队完成。核心团队成员包括Himanshu Gupta(亚利桑那州立大学,现供职于亚马逊)、Shreyas Verma(Asurion)、Ujjwala Anantheswaran(亚利桑那州立大学,现供职于微软)、Kevin Scaria(亚利桑那州立大学,现供职于亚马逊)、Mihir Parmar(亚利桑那州立大学)、Swaroop Mishra(亚利桑那州立大学,现供职于Google DeepMind)和Chitta Baral(亚利桑那州立大学)。团队成员均在各自领域有着深厚的专业背景,确保了POLYMATH基准的科学严谨性和技术先进性。
该项目的代码库可以在GitHub上找到,地址为:https://github.com/kevinscaria/PolyMATH,数据集则托管在Hugging Face上,地址是:https://huggingface.co/datasets/him1411/polymath,为研究人员提供了便捷的访问和使用途径。
相关工作
MLLMs的核心优势在于其能够同时处理文本和视觉信息,具备跨模态理解和生成能力。这些模型不仅在语言理解和生成上表现出色,还能够处理复杂的视觉任务,为多种应用场景提供了解决方案。
多模态大语言模型的发展得益于大语言模型(LLMs)和大型视觉模型的进步。近年来,OpenAI的GPT系列和Google的Gemini系列等模型在处理多模态任务上取得了显著成就。例如,GPT-4V不仅能够生成高质量的文本,还能够理解复杂的图像内容,展现了强大的视觉推理能力。这些模型通过结合自然语言处理(NLP)和计算机视觉(CV)技术,能够在教育、医疗、科学研究等多个领域中提供创新的解决方案。
在数学推理方面,MLLMs同样展现了巨大的潜力。现有的研究表明,这些模型在解决几何问题、图表理解和数学运算等任务中表现出色。尽管如此,MLLMs在处理涉及空间关系和抽象逻辑推理的复杂数学问题时,仍存在一定的局限性。这是因为这些问题不仅需要模型具备良好的视觉理解能力,还需要其能够进行深层次的逻辑推理和认知过程。

图1:MLLM在面对涉及视觉信息的问题时所采用的推理模式示例。在第一行,模型无法感知相邻半圆之间的关系;在最后一行,模型无法理解答案图像中的细节。
在评价MLLMs性能的过程中,研究人员开发了多种基准数据集,其中比较著名的包括GeoQA、VQA和UniGeo。这些基准在推动多模态模型的发展中起到了重要作用,但它们也存在一定的局限性。
GeoQA是一个专注于地理问题的问答数据集,主要评估模型在处理地理信息和地理推理任务上的能力。尽管GeoQA包含了一些复杂的地理问题,但其问题类型相对单一,未能全面覆盖多种数学和视觉推理任务。
VQA(Visual Question Answering)则是一个视觉问答数据集,旨在评估模型在理解图像内容和回答相关问题方面的能力。VQA的数据集包含了大量的日常场景和常识性问题,虽然在一定程度上考察了模型的视觉理解能力,但其数学推理任务相对较少,未能充分评估模型在复杂数学问题上的表现。
UniGeo是一个专注于几何问题的数据集,评估模型在处理几何图形和几何推理任务上的能力。尽管UniGeo在几何推理方面取得了一定的进展,但其数据集规模较小,问题类型也较为有限,未能全面反映模型在多模态任务中的综合能力。
为了解决现有基准的局限性,研究团队提出了POLYMATH这一具有挑战性的多模态数学推理基准。POLYMATH旨在全面评估MLLMs在复杂视觉场景下的数学推理能力,其数据集包含了5000个高质量的认知文本和视觉挑战,涵盖了图案识别、空间推理等10个类别。通过多样化的任务设置,POLYMATH能够全面测试模型的认知推理能力,特别是在处理复杂数学和视觉推理任务时的表现。
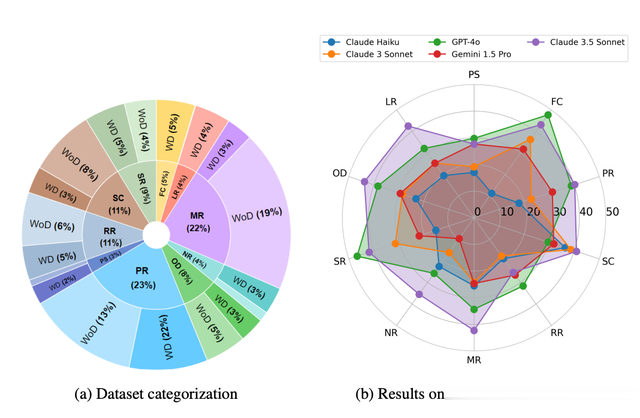
图2:POLYMATH的分布和难度概述(a)显示了数据集中5000个问题的类别划分,以及该类别的有图(WD)和无图(WoD)划分;(b) 比较各种MLLM的每类别性能。
POLYMATH不仅在数据规模上领先于现有基准,其任务设置也更加多样化和复杂化,能够全面评估模型在多模态任务中的综合表现。研究团队通过严格的数据收集和质量控制流程,确保了POLYMATH数据集的高质量和高可信度。此外,研究团队还提供了详细的文本描述和图像内容,以支持基于文本和视觉的双重评估。

图3:带图和不带图问题的示例。除了问题图像外,POLYMATH还包括上面显示的元数据。没有图表的问题不会出现在测试img中,而这两种问题都会出现在testmini中。
POLYMATH数据集的整理
为了系统地评估多模态大语言模型(MLLMs)在复杂视觉场景下的数学推理能力,研究团队开发了POLYMATH这一具有挑战性的基准。该数据集的整理过程包括精细的数据收集流程、严格的质量保证措施以及科学的分类架构,确保数据集的高质量和多样性。
数据收集是确保POLYMATH数据集高质量的关键。研究团队采用了手动和自动化相结合的方式,经过五个步骤来收集和整理数据:
生成唯一标识符:为每份试卷生成一个唯一标识符(UUID),以便识别并整理从中收集到的所有问题。手动收集图像片段:标注人员手动收集每个问题及其相关背景信息的图像片段,包括可能适用于多个问题的分离片段。图像合并:使用图像合并脚本自动识别并合并被页面分隔的问题图像及其相关背景图像,以保证完整性。文本转录和元数据生成:使用大语言模型(LLM)转录问题及其标准答案,并生成包括类别、是否包含图表、图像描述等附加元数据。所有元数据都经过人工检查,确保质量。生成标注文件:自动创建并填充注释文件,每行对应一个问题,详细记录相关信息。这一系统化的数据收集流程确保了POLYMATH数据集的高质量和多样性,为模型评估提供了坚实基础。
在数据收集和标注过程后,研究团队进行了全面的质量检查,以确保数据集的高质量和可信度。
样本筛选:剔除分辨率低、超出类别范围或缺少关键信息的样本。视觉噪声处理:去除带有显著水印或视觉噪声的样本,确保样本清晰可读。答案校正:领域专家标注员纠正提取错误的标准答案。类别验证:确保每个问题都属于指定类别,纠正观察到的分类错误。这些质量保证措施确保了数据集的准确性和一致性,使POLYMATH成为评估MLLMs性能的可靠工具。
为全面评估模型的多模态认知推理能力,研究团队开发了一个分类架构,根据提供的信息和评估的推理技能对问题进行分类。POLYMATH数据集包含以下10个类别,每个类别都有其定义和示例。
视角转换(PS):给定一个图形,要求解决者根据指示(如翻转、镜像、旋转等)进行变换。图形完成(FC):给定一个图形,要求完成图形并识别标记位置的缺失元素。图案识别(PR):要求理解并复制一对一关系或图案,例如根据a和b的关系,确定b和c的对应关系。序列完成(SC):给定一系列数字或图形,要求找到系列中的下一个元素。相对推理(RR):包含不同数据点及其相互关系,要求解决者推断未明确提到的关系。数学推理(MR):涉及数学计算,例如解方程。数值推理(NR):涉及计数提到的元素数量,元素可能是单一图形的一部分或符合指定图案。空间推理(SR):要求解决者通过观察进行推理,以得出答案。找出不同(OD):给定一组元素,要求识别与其他不同的元素。逻辑推理(LR):涉及简单的逻辑推理,例如蕴涵和矛盾。这一分类架构不仅涵盖了多种推理技能,还确保了数据集的多样性和复杂性,使其能够全面评估MLLMs在多模态任务中的表现。通过精细的数据收集流程、严格的质量保证措施和科学的分类架构,POLYMATH数据集为评估和提升MLLMs的性能提供了重要工具。
实验设计
为了深入分析多模态大语言模型(MLLMs)在复杂视觉场景下的数学推理能力,研究团队在POLYMATH基准上进行了系统的实验设计。这一实验设计包含了评估模型的选择、提示策略的应用以及具体的实验方法和附加实验分析。
评估模型的选择
在评估模型的选择上,研究团队综合考虑了闭源和开源MLLMs,旨在全面了解不同模型在多模态推理任务中的表现。闭源模型包括OpenAI的GPT-4o、OpenAI O1以及Anthropic的Claude-3.5 Sonnet和Gemini-1.5 Pro等。这些模型在处理多模态任务上表现出色,是当前技术前沿的代表。闭源模型的选择使得实验可以评估最先进的商业化模型的性能。
与此同时,研究团队也选择了多种开源MLLMs,包括LLaVA(如LLaVA-v1.6-Mistral-7B、LLaVA-v1.6-Vicuna-13B)、G-LLaVA(如G-LLaVA-7B)以及ShareGPT4V等。这些模型提供了一个开放的研究平台,允许学术界和开发者进一步研究和改进多模态推理能力。通过评估开源模型,研究团队不仅可以比较闭源和开源模型的性能,还可以识别开源模型在具体任务中的优势和不足。
提示策略的应用
提示策略在多模态推理任务中扮演着重要角色,研究团队采用了四种不同的提示策略,分别是零样本推理、少量样本推理、链式思维提示和退一步提示。这些策略旨在测试模型在不同信息量和提示方式下的表现。
零样本推理:在没有提供任何示例的情况下,直接对模型进行评估。这种策略测试模型在完全陌生情况下的推理能力。少量样本推理:提供少量示例(如2个)后进行评估,测试模型在有少量上下文信息时的表现。链式思维提示:使用链式思维提示(Chain-of-Thought),引导模型进行逐步推理,帮助其在复杂任务中保持逻辑连贯性。退一步提示:使用退一步提示(Step Back),鼓励模型在解题过程中重新审视和评估其推理步骤,以提高准确性和逻辑性。通过这些提示策略,研究团队能够深入分析模型在不同提示方式下的推理性能,揭示其在复杂任务中的潜在能力和不足。
附加实验分析
除了主要实验设置外,研究团队还进行了三项附加实验分析,以进一步验证和扩展实验结果。
test-img子集上的推理测试:test-img子集包含带有图表的问题,专注于评估模型的视觉理解能力。研究团队通过对这些问题进行推理测试,评估模型在处理图表信息时的表现。无图表问题的文本版本测试:将test-img子集中的图表替换为详细的文本描述,生成一个文本版本的test-img。通过对文本版本的测试,研究团队能够分析模型在文本描述和图表信息上的依赖程度和表现差异。OpenAI O1模型的无图表问题评估:评估OpenAI O1模型在不包含图表问题上的表现,并与人类基准进行比较,以了解其在文本推理任务中的能力。这些附加实验提供了进一步的分析视角,有助于全面了解模型在不同场景下的性能和局限。
实验方法
实验方法包括严格的设置和详细的操作步骤,以确保实验结果的可靠性和可重复性。具体方法包括:
实验数据集:使用POLYMATH基准中的testmini子集,该子集包含1000个经过严格筛选的问题,覆盖了10个不同的推理类别。提示策略实施:按照各提示策略的要求,对模型进行提示和引导,记录其推理过程和结果。结果评估:使用精确匹配进行答案对比,记录每个模型在不同提示策略下的准确率和错误类型。通过这些实验方法,研究团队能够系统地评估不同模型在多模态数学推理任务中的表现,揭示其在复杂视觉场景下的推理能力和局限性。
结果分析
在这项研究中,研究团队通过系统的实验,详细评估了多种闭源和开源的多模态大语言模型(MLLMs)在POLYMATH基准上的表现。通过比较模型在各类问题中的表现,我们可以深入了解其在复杂推理任务中的能力和局限性。以下是实验结果的详细分析。
闭源模型
在闭源模型的评估中,Claude-3.5 Sonnet和GPT-4o表现尤为突出。Claude-3.5 Sonnet在不同的提示策略下展现了强大的推理能力,特别是在Step Back提示策略中,准确率达到了41.90%。这一策略鼓励模型重新审视和评估其推理步骤,从而提高了准确性和逻辑性。GPT-4o紧随其后,尤其在零样本推理和Step Back提示下表现优异,显示了其强大的适应性和推理能力。
Gemini-1.5 Pro的表现相对中等,在所有类别中表现稳定,但未能在任何特定领域中占据主导地位。相比之下,Claude Haiku作为最小的闭源MLLMs,表现普遍较差,未能在复杂推理任务中展现出足够的能力。
开源模型
开源模型的评估结果显示,LLaVA-v1.6-Mistral-7B在整体表现上名列前茅,总体得分为15.2%。特别是在找出不同(OD)、空间推理(SR)、相对推理(RR)和数学推理(MR)类别中表现突出。这表明LLaVA-v1.6-Mistral-7B在生成精确、一致且相关的响应方面表现出色,即使在超出分布的数据样本中也是如此。

图4:不同问题类别中逻辑缺陷(LF)和空间误解(SM)错误的频率。我们报告每个模型的数据,以便比较模型的能力。由于这些问题需要大量的逻辑跳跃和视觉推理,它们在OD、PR和SC类问题中最为普遍。
ShareGPT4V(13B)模型在PR、SC、RR、MR、SR和OD类别中的表现也非常优异,总得分为12.8%。其他模型如LLaVA-v1.6-Vicuna-13B、LLaVA-1.5(13B)、G-LLaVA(13B)和LLaVA-v1.6(34B)在不同类别中表现各异,显示出其在处理多样推理任务时的个体优势和不足。
错误类型分析
在分析错误类型时,研究团队识别出了七种常见错误类型,并详细分析了其分布。
逻辑缺陷(LF):推理步骤违反了既定的逻辑规则或现实世界的原则,如等式或基数。空间误解(SM):模型误解了空间关系或错误地读取了给定图像的特定细节。记忆缺陷(MF):模型忘记了问题或解答过程中提供的信息。计算错误(CE):模型在数学计算中出错,或在方程中代入了错误的值。误对齐(MG):模型推理正确,但得出的答案错误,如识别了模式但选择了错误的选项。不完整(IC):模型生成的解决方案不完整,或输出达到了令牌限制。其他错误:包括其他未分类的错误。研究团队通过对236个错误样本的手动检查,发现逻辑缺陷(LF)是最常见的错误,接近60%的错误样本中出现。空间误解(SM)位居第二,占约25%。这些错误在找出不同(OD)、图案识别(PR)和序列完成(SC)类别的问题中尤为常见,因为这些问题要求模型进行不常见的逻辑跳跃和完全理解视觉信息,而这些正是模型的弱点所在。
此外研究还发现,模型在推理过程中常常犯相同的错误,例如假设某一模式在每行都适用,而正确的推理应涉及跨列的模式复制。特别是在PR类别中,GPT-4o、Gemini-1.5 Pro和Claude-3.5 Sonnet在近80%的样本中遵循了相同的错误推理结构。这表明尽管模型之间存在差异,但在实践中它们展示了相同的优势和不足。
人类评估
为了确认数据集的难度,研究团队邀请了六名研究生进行人类评估。每位研究生被分配到一个特定的问题类别,以避免从同一类别的其他问题中获得额外信息。他们只提供最终答案,没有详细的推理过程。
人类评估的结果显示,尽管模型在某些类别中表现优异,但与人类推理能力相比仍有显著差距。特别是在处理复杂逻辑和空间推理任务时,模型表现明显逊色。这一结果为未来的研究提供了明确的方向,强调了开发能够无缝结合数学推理和视觉理解的模型的必要性。
实验分析
在对多模态大语言模型(MLLMs)进行系统评估的过程中,研究团队发现了它们在视觉推理方面的依赖性和常见错误模式。以下是对模型依赖图像描述而非图像的表现差异分析,以及对模型常见错误的深入探讨。
模型依赖图像描述而非图像
通过对test-img子集的实验分析,研究团队发现大多数MLLMs在处理带有图表的问题时表现出明显的局限性。具体而言,当模型面对的是直接的图像时,其表现明显不如面对详细文本描述时的表现。为了验证这一发现,研究团队将test-img子集中的图表替换为详细的文本描述,生成一个文本版本的test-img进行测试。
结果显示,所有模型在处理文本描述问题时的表现提升了约3-4%。这表明,尽管这些模型在处理文本数据时表现优异,但在视觉推理任务中存在显著的不足。特别是GPT-4o和Claude-3.5 Sonnet这两个模型在文本描述中的表现提升尤为明显。这种现象表明,当前的MLLMs虽然在理解和生成文本方面已经取得了显著进展,但在处理复杂的视觉信息时,仍然依赖于能够清晰描述图像内容的文本信息。
这一发现对未来的研究具有重要启示:要进一步提高MLLMs在多模态任务中的表现,需要增强其对视觉信息的理解和推理能力,减少对文本描述的依赖。
模型错误的深入分析
在对模型错误类型的分析中,研究团队识别出七种常见的错误类型,其中逻辑缺陷(LF)和空间误解(SM)最为常见。以下是对这些错误类型及其对模型推理能力影响的深入探讨。
逻辑缺陷(LF)
逻辑缺陷是模型在推理过程中违反既定的逻辑规则或现实世界的原则。例如,当模型在解决数学问题时,未能正确应用等式或基数原则。研究发现,逻辑缺陷在接近60%的错误样本中出现,这一比例相当高。特别是在图案识别(PR)、序列完成(SC)和找出不同(OD)类别的问题中,逻辑缺陷尤为常见。这些问题通常要求模型进行复杂的逻辑跳跃和模式识别,而模型在这方面表现出的不足导致了高频率的逻辑错误。
空间误解(SM)
空间误解是指模型在理解图像的空间关系或特定细节时出现的错误。例如,当面对涉及空间布局和相对位置的问题时,模型未能正确理解图像中的空间信息。研究表明,空间误解占约25%的错误样本,这一比例仅次于逻辑缺陷。特别是在涉及几何图形和空间推理的问题中,模型容易出现空间误解。这种现象表明,尽管MLLMs在处理文本信息方面有一定的优势,但在处理需要深入理解空间关系的视觉信息时,仍存在显著的不足。
通过对逻辑缺陷和空间误解的深入分析,我们可以看到当前MLLMs在复杂推理任务中的局限性。为了解决这些问题,未来的研究需要专注于增强模型的逻辑推理能力和空间理解能力。例如,可以通过引入更多的空间推理任务和复杂逻辑推理问题来训练模型,从而提高其在这两个方面的表现。
总结
通过深入探讨模型在视觉推理方面的依赖情况和常见错误模式,我们可以更好地理解当前MLLMs在复杂推理任务中的表现和局限。尽管这些模型在文本描述方面表现优异,但在处理复杂的视觉信息时仍存在显著的不足。未来的研究需要专注于增强模型的视觉理解和逻辑推理能力,从而全面提升其在多模态任务中的表现。通过不断改进和优化,MLLMs有望在更多应用场景中展现出更加卓越的性能和能力。(END)
参考资料:https://arxiv.org/pdf/2410.14702

波动世界(PoppleWorld)是噬元兽数字容器的一款AI应用,是由AI技术驱动的帮助用户进行情绪管理的工具和传递情绪价值的社交产品,基于意识科学和情绪价值的理论基础。波动世界将人的意识和情绪作为研究和应用的对象,探索人的意识机制和特征,培养人的意识技能和习惯,满足人的意识体验和意义,提高人的自我意识、自我管理、自我调节、自我表达和自我实现的能力,让人获得真正的自由快乐和内在的力量。波动世界将建立一个指导我们的情绪和反应的价值体系。这是一款针对普通人的基于人类认知和行为模式的情感管理Dapp应用程序。
