报告出品方:华创证券
以下为报告原文节选
------
一、HBM 凭高带宽优势成 AI 芯片主流选择,三大存储厂引领市场
(一)HBM 具有高带宽优势,AI 需求爆发驱动 HBM 快速增长
HBM(High Bandwidth Memory)即高带宽存储器,是一种基于 3D 堆叠工艺的 DRAM 内存芯片,具有高内存带宽、低能耗、更多 I/O 数量、更小尺寸等优势。随着显卡芯片快速发展,GDDR5 已经逐渐不能满足对带宽的需求,技术发展也进入瓶颈期,阻碍了显卡芯片性能的持续提升。2009 年 AMD 开始着手 HBM 的研发,并联合海力士在 2013 年首次实现 HBM 的制造问世。


在每个 HBM 封装内部,多个 DRAM die 通过 TSV(硅通孔)和 Microbump(微凸块)连接,堆叠后连接到下层 DRAM 的逻辑 die;DRAM 再通过 uBump 和 Interposer(中介层)连接 GPU 芯片。Interposer 再通过 Bump 连接到 BALL,BGA ball 再连接到封装基板上。

HBM 技术快速迭代,向更大带宽、更快传输速率演进。2014 年推出的 HBM1 带宽为128Gb/s,高于 DDR4 和 GDDR5,容量为 1GB,同时较小的尺寸能够消耗较低的功率;海力士在 2018 年推出了 HBM2,性能是 HBM1 的 2-3 倍,带宽达到了 307GB/s,容量扩大到了 4-8 倍。2020 年海力士又推出了 HBM2 的扩展版本——HBM2E,带宽和容量进一步扩大,到 2022 年海力士推出并量产了全球首款 HBM3,堆叠层数达到了 8/12 层,容量已提高到了 16/24GB。2024 年 2 月,美光科技表示,其 HBM3E 内存已开始量产,并将用于英伟达的 H200 计算 GPU,预计于 2024 年第二季度发货。HBM3E 最大容量为36GB,每引脚最大数据速率为 9.2Gbps,最大带宽超过每秒 1.18TB。

大模型要求算力提升速度加快,HBM 助力突破存储瓶颈。ChatGPT 爆火 AI 大模型迎来快速发展,引爆算力需求。GPT-3 等超大语言模型对算力的提升速度要求已经突破了后摩尔时代算力提升速度的极限,“内存墙”已成为重要的性能瓶颈。内存墙问题不仅与内存的大小有关,还与内存的传输带宽有关。在过去 20 年间硬件的峰值计算能力提高了90000 倍,即使存储器从 DDR 发展到 GDDR6x,内存/硬件互联带宽也只提高了 30 倍。
HBM 相比 DDR 具有更高的带宽和更低的功耗,是高速计算平台的最优解决方案。

HBM3 成高端 AI 训练芯片主流选择。目前 NVIDIA 的 A100 和 H100,分别搭载了达80GB 的 HBM2E 和 HBM3,在 Grace Hopper 芯片中,单颗芯片的 HBM 搭载容量再提升20%,达到 96GB。2024 年 GTC 人工智能大会正式发布 Blackwell 芯片,单颗芯片的 GPU显存容量高达 192GB,搭载 HBM3E,显存带宽有 8TB/s。此外 AMD 的 MI300 也搭载HBM3,其中 MI300X 容量达 192GB,八颗 HBM3 堆栈带宽达 5.2TB/s。

HBM 市场规模迎来快速增长,预计 24 年全球达 169 亿美元市场空间。为应对 NVIDIA和大型 CSP 厂商对高带宽存储订单的不断增加,各大存储供应商持续扩大 HBM 产量,TrendForce 根据供应商当前的生产计划进行的预测表明,到 2024 年,HBM 位元供应量将增加 260%。2023 年至 2024 年将是 AI 发展的关键年,将引发对 AI 训练芯片的大量需求,从而提高 HBM 配置率。2023 年起市场主要需求将从 HBM2e 转向 HBM3,根据TrendForce 数据及预测,2022-2024 年 HBM3 需求占比分别为 8%/39%/60%,HBM3 凭借其卓越性能加持 ASP 显著高于前序版本,或进一步推动 HBM 市场规模在 2024 年达到169 亿美元,同比增长 288 %,届时 HBM 占 DRAM 产业产值比重或提升至 20.1%,同比提升 11.7pct。

(二)SK 海力士独占半壁江山,三星&美光紧随其后
SK 海力士具备先发优势,三星奋起直追,美光专注先进世代产品。当前 HBM 的量产厂商是三大存储厂,2012 年海力士成功研发 HBM1 后,三星奋起直追,2016 年即宣布开始量产 4GB HBM2 DRAM,并在同年开始生产 8GB HBM2。2019 年 8 月,SK 海力士宣布成功研发出新一代“HBM2e”;2020 年 2 月,三星也正式宣布推出其 16GB HBM2e 产品“Flashbolt”,于 2020 年上半年开始量产。2021 年 10 月,SK 海力士发布了全球首款HBM3,并于 2022 年 6 月正式量产,供货英伟达,击败了三星再度于 HBM 上拿到了技术和市场优势。而另一大存储厂商美光在 2018 年放弃 HMC 后才转向 GDDR6 和 HBM产品的研发,将更多研发投入 HBM3E 及更先进世代产品。

SK 海力士独占 HBM 市场半壁江山,三星有望逐步缩小差距。根据 TrendForce 数据,2022 年三大原厂 HBM 份额分别为 SK 海力士占比 50%,三星占比约 40%,美光(Micron)占比约 10%。SK 海力士目前在 HBM3 生产方面处于领先地位,是 NVIDIA 服务器 GPU的主要供应商。由于三星从 CSP 获得的订单数量不断增加,预计 2024 年三星与 SK 海力士之间的市场份额差距将大幅缩小。主要专注于 HBM3E 开发的美光科技未来两年的市场份额可能会略有下降。
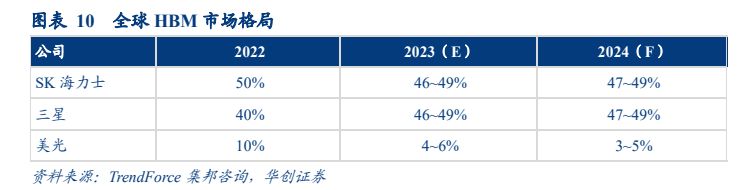
HBM 供应依然紧俏,2024 年订单量预计持续攀升。HBM Die Size 较 DDR5 同制程与同容量尺寸大 35~45%;良率(包含 TSV 封装良率),则比起 DDR5 低约 20~30%;生产周期(包含 TSV)较 DDR5 多 1.5~2 个月不等。HBM 生产周期较 DDR5 更长,从投片到产出与封装完成需要两个季度以上。因此,急欲取得充足供货的买家需要更早锁定订单量,据 TrendForce 集邦咨询了解,大部分针对 2024 年度的订单都已经递交给供应商,除非有验证无法通过的情况,否则目前来看这些订单量均无法取消。以 HBM 产能来看,三星/SK 海力士/美光至 2024 年底的 TSV HBM 月总产能有望达到 130K/120~125K/20K。

二、HBM 技术概述:TSV、MR-MUF 与混合键合为关键工艺
HBM 的加工流程包括前端的晶圆加工、后端的 Bumping(凸点)和 Stacking(堆叠)以及KGSD 测试。TSV 和 MR-MUF 封装技术是 HBM 技术应用的核心工艺,混合键合工艺应用前景良好。
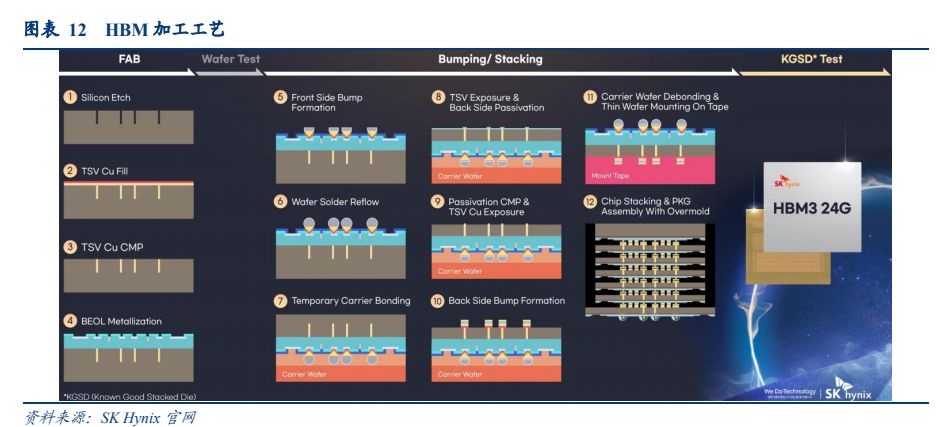
(一)TSV:HBM 制备核心工艺
TSV 封装可以提高堆叠密度,降低互联延迟。TSV(Through-Silicon Vias)即硅通孔技术,指在芯片上钻孔并通过铜、钨、多晶硅等导电物质的填充,实现芯片的垂直电气互联。
硅通孔封装的优势在于:1)可以实现较小的封装尺寸:随着堆叠芯片及连接引脚(Pin)的数量增加,引线复杂度提高并且需要更多空间容纳引线;而硅通孔芯片堆叠不需要复杂布线,封装尺寸更小。2)硅通孔封装可以实现芯片直接向下方芯片发送信号,而引线键合封装需先将信号传输至基板再传输至芯片,信号传输路径更长,因此硅通孔封装可以大大降低互联延迟,提高运行速度。TSV 结合微凸点,可以在三维方向获得最大的堆叠密度和最小的外形尺寸,同时大幅提高了芯片的速度和低功耗性能,被视为是继引线键合、载带自动键合(TAB)和倒装芯片之后的第四代封装互联技术。

HBM 并非一种全封装产品,而是一种半封装产品。当 HBM 产品被送到系统半导体制造商那里时,系统半导体制造商会使用中介层构建一个 2.5D 封装,将 HBM 与逻辑芯片并排排列。由于 2.5D 封装中的基板无法提供用于支持 HBM 和逻辑芯片的所有输入/输出引脚的焊盘,因此需要使用中介层来形成焊盘和金属布线,从而容纳 HBM 和逻辑芯片。然后,再将这些中介层与基板连接。

TSV 工艺价值量在 HBM 封装工艺中占比最高。根据 3DinCites 数据,配置为 4 层 DRAM core die 和 1 层逻辑 base die 堆叠的 HBM 结构,在 99.5%和 99%的芯片键合良率条件下,TSV 制造和 TSV 通孔露出工艺分别占其成本的 30%和 28%。

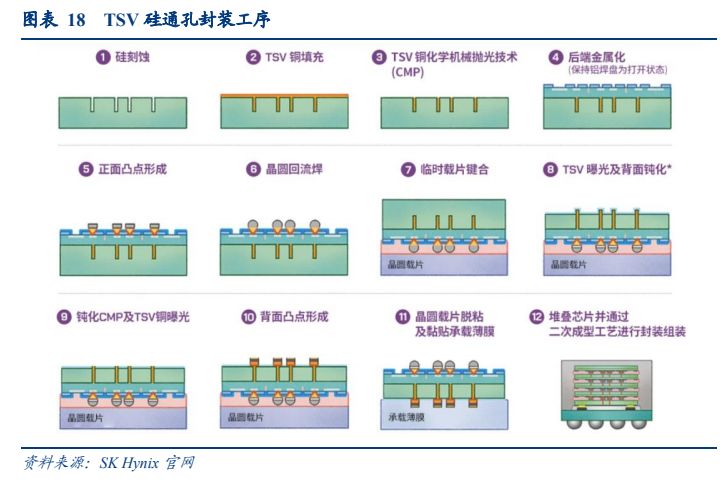
TSV 属于前道工艺,主要由存储原厂完成。用于生产 HBM 的 DRAM 颗粒需要在制造过程中预留 TSV 打孔的位置,属于定制颗粒。具体封装工艺流程:首先在晶圆制造过程中形成通孔(Via Middle)。随后在封装过程中,于晶圆正面形成焊接凸点。之后将晶圆贴附在晶圆载片上并进行背面研磨,在晶圆背面形成凸点后,将晶圆切割成独立芯片单元,并进行堆叠。
中通孔(Via Middle)的制备涉及刻蚀、沉积、电镀、抛光等工艺:首先在前道工序(Frontend of Line)中,在晶圆上制作晶体管,如互补金属氧化物半导体等。随后使用硬掩模(Hard Mask)在硅通孔形成区域绘制电路图案。之后利用干刻蚀(Dry Etching)工艺去除未覆盖硬掩膜的区域,形成深槽。再利用化学气相沉积工艺(Chemical Vapor Deposition)制备绝缘膜,如氧化物等。这层绝缘膜将用于隔绝填入槽中的铜等金属物质,防止硅片被金属物质污染。此外绝缘层上还将制备一层金属薄层作为屏障。此金属薄层将被用于电镀铜层。电镀完成后,采用化学机械抛光(Chemical Mechanical Polishing)技术使晶圆表面保持平滑,同时清除其表面铜基材,确保铜基材只留在沟槽中。然后通过后道工序(Back-end of Line)完成晶圆制造。
(二)MR-MUF:HBM3 领先核心技术
MR-MUF 相比目前主流堆叠工艺 TC-NCF 具有散热好等优势。MR-MUF(Mass reflow molded underfill)即批量回流模制底部填充,是将多个芯片放置在下层基板上,通过回流焊一次性粘合,然后同时用模塑料填充芯片之间或芯片与基板之间间隙的方法,该方法主要用于倒片封装和 TSV 芯片堆叠。目前主流的堆叠工艺是用 TC-NCF 的方式,即热压键合与非导电膜(NCF,Non Conductive Film)相结合。NCF 预先贴合在晶圆表面,覆盖凸点,在焊接过程中流动填充在芯片与芯片间,缓冲应力对芯片的影响的同时保护凸块。
MR-MUF 避免了 TC-NCF 在穿透中所需要的高温和压力,使用的 EMC 塑封料具有良好的导热性,可以将导热率提高两倍左右,有助于解决存储器的散热问题,具有显著优势。

MR-MUF 和 EMC 塑封料是 SK 海力士实现 HBM3 技术升级的关键工艺及材料。2016年,SK 海力士将批量回流焊技术应用在 8 层堆叠的 HBM2E 上,并使用具有优良导热性的塑封料作为间隙填充材料,改善了因存储器带宽增加而引起的散热问题,同时也大幅降低了 TSV 的制造成本。对于 12 层的 HBM3 产品,堆叠的 DRAM 芯片个数从 8 个(容量 16GB)提到了 12 个(容量 24GB),容量提升了 50%,同时还要保持产品的厚度不变,需要将 DRAM 芯片打薄 40%后再进行叠加,容易导致芯片弯曲等问题,芯片间隙也缩窄13%。SK 海力士进一步改进使用的 EMC 塑封料和 MR-MUF 技术,在成功实现 12 层堆叠的同时还将散热性提高了约 2.5 倍,重新获得了在 HBM 市场的领先优势。

EMC 是海力士实现 HBM3 快速迭代的关键材料。EMC(Epoxy Molding Compound,环氧树脂模塑料)中文简称环氧塑封料,是用于半导体封装的一种热固性化学材料,由环氧树脂为基体树脂,以高性能酚醛树脂为固化剂,加入硅微粉等填料,以及添加多种助剂加工而成,主要功能为保护半导体芯片不受外界环境(水汽、温度、污染等)的影响,并实现导热、绝缘、耐湿、耐压、支撑等复合功能。根据中国科学院上海微系统与信息技术研究所数据,90%以上的集成电路均采用环氧塑封料作为包封材料。

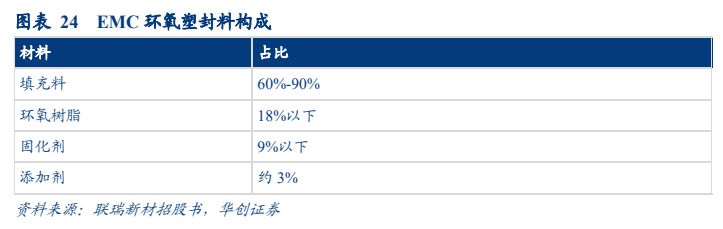
EMC主要构成为硅微粉填充料。目前常见的环氧塑封料主要组成为填充料(60%~90%)、环氧树脂(18%以下)、固化剂(9%以下)、添加剂(3%左右)。在微电子封装中,主要要求集成电路封装后高耐潮、低应力、低 α 射线,耐浸焊和回流焊,塑封工艺性能好。针对这几个要求,环氧塑封料需在树脂基体里掺杂无机填料,现用的无机填料基本为二氧化硅微粉,其含量最高达 90.50%。
球形硅微粉是重要的环氧塑封料填料。填充率与硅微粉的颗粒形貌相关,硅微粉按产品颗粒形貌不同可分为角形硅微粉和球形硅微粉。以高端芯片为代表的大规模集成电路要求封装材料中的填充料超细,而且要求其具有纯度高、放射性元素含量低等品质,特别是对于颗粒形貌提出了球形化要求。球形硅微粉具有高耐热、高耐湿、高填充率、低膨胀、低应力、低杂质、低摩擦系数等优越性能,成为超大规模和特大规模集成电路封装料中不可或缺的功能性填充材料。根据立木信息咨询《中国电子级硅微粉市场调研与投资战略报告(2019 版)》数据,当集成电路的集成度为 1M-4M 时,环氧塑封料应部分使用球形硅微粉,集成度 8M-16M 时,则必须全部使用球形硅微粉。

(三)混合键合:未来 HBM 主流堆叠键合技术
互联距离/互联密度/导热效率优势加持,混合键合或为未来 HBM 主流堆叠键合技术。目前 HBM 中所使用的 TSV 技术需要使用微凸块垂直堆叠多个芯片(通常为 4-12 个芯片)的方法。由于市场对高容量存储器产品需求不断增加,预计未来将需要 16 层甚至更高的多芯片堆叠技术。随着层数变高,会出现翘曲和发热等因素,同时还需满足当下 HBM 芯片的标准厚度 720 微米。为了实现这一目标,不仅需要减小芯片的厚度和凸块电极的尺寸,而且在不久的将来还需要应用混合键合技术,去除芯片之间的填充物,使其直接连接到铜电极上。
混合键合(Hybrid Bonding),主要用于在芯片的垂直堆叠中实现互连,最大的特点是无凸块,结合了金属键合和非导电粘合剂(通常是氧化物或聚合物)的方法,能够在微观尺度上实现芯片间的直接电连接。与使用微凸块的方法相比,混合键合方法可以大幅缩小电极尺寸,从而增加单位面积上的 I/O 数量,进而大幅降低功耗。与此同时,混合键合方法可以显著缩小芯片之间的间隙,由此实现大容量封装。此外,它还可以改善芯片散热性能,有效地解决因耗电量增加而引起的散热问题。

混合键合可以通过晶圆到晶圆 (W2W) 或芯片到晶圆 (D2W) 工艺来完成。W2W 将两个制造好的晶圆直接键合在一起,此方案提供更高的对准精度、吞吐量和粘合良率,因此应用更为广泛。在 DRAM 领域主要使用 W2W 方案。

混合键合更加依赖前道制造工艺。与基于凸块的互连相比,混合键合对表面光滑度、清洁度和粘合对准精度有非常严格的要求,因此该技术融入了十分复杂的工序,生产必须在标准接近前端晶圆厂级别的超洁净室、自动化工厂和工艺专业知识要求的环境中进行。
混合键合的工艺流程还涉及许多传统上仅由晶圆厂专用的工具,包括电镀、CMP、等离子体激活、对准、键合、分割和退火,以及颗粒和缺陷的检测工具。
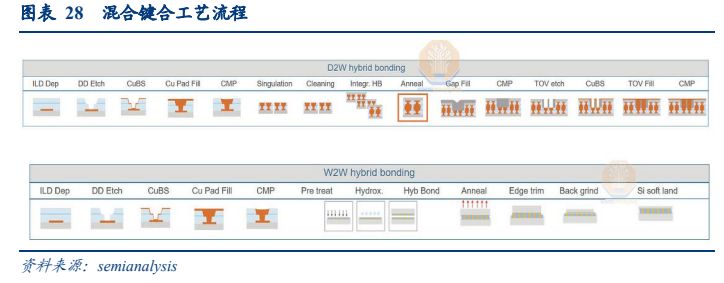
混合键合潜在应用良多,出货量有望快速增长。目前,混合键合技术已经成功应用于数据中心和高性能计算应用的高端逻辑芯片领域。AMD在其Ryzen 7 5800x的芯片设计中,采用了台积电的混合键合技术 SoIC,将 7nm 64MB SRAM 堆叠并键合到 7nm 处理器上,使内存密度增加了两倍,成为第一家推出采用铜混合键合芯片的供应商。Besi 预估,2024年逻辑芯片领域将迎来新一轮混合键合需求浪潮,而随着 HBM 需求持续抬升,存储领域将会接力逻辑芯片贡献明显增量,中性假设下全球 2030 年混合键合设备保有量有望达到 1400 台左右,混合键合技术为未来芯片互联技术的发展方向之一。混合键合设备的平售价将显著高于目前最先进的 Flip chip(倒装芯片)或 TCB 键合系统。据 Besi 估计,每台键合设备的成本在 200 万至 250 万欧元之间。

--- 报告摘录结束 更多内容请阅读报告原文 ---
报告合集专题一览 X 由【报告派】定期整理更新
(特别说明:本文来源于公开资料,摘录内容仅供参考,不构成任何投资建议,如需使用请参阅报告原文。)
精选报告来源:报告派科技 / 电子 / 半导体 /
人工智能 | Ai产业 | Ai芯片 | 智能家居 | 智能音箱 | 智能语音 | 智能家电 | 智能照明 | 智能马桶 | 智能终端 | 智能门锁 | 智能手机 | 可穿戴设备 |半导体 | 芯片产业 | 第三代半导体 | 蓝牙 | 晶圆 | 功率半导体 | 5G | GA射频 | IGBT | SIC GA | SIC GAN | 分立器件 | 化合物 | 晶圆 | 封装封测 | 显示器 | LED | OLED | LED封装 | LED芯片 | LED照明 | 柔性折叠屏 | 电子元器件 | 光电子 | 消费电子 | 电子FPC | 电路板 | 集成电路 | 元宇宙 | 区块链 | NFT数字藏品 | 虚拟货币 | 比特币 | 数字货币 | 资产管理 | 保险行业 | 保险科技 | 财产保险 |
