对大多数的计算机爱好者而言,“流水线级数”和“发射数”是两个既熟悉又陌生的词语。因为我们经常看到“某款CPU的流水线有多少级、某款CPU是几发射”这种的说法,但并不是很清楚到底什么是流水线,什么是多发射,也不是很明白流水线和发射数如何影响频率和IPC。
从单周期到流水线最先出现的是单周期处理器,然后是多周期处理器,最后指令流水线才成为现代CPU的标配。
单周期处理器每条指令基本在一个时钟周期内完成,每个时钟周期必须完成取指、译码、读寄存器、执行、访存等一系列的组合逻辑。为了保证在下一个时钟到来之前完成所有处理,就需要把时钟间隔拉长,也就是必须降低处理器的频率。
处理器执行的功能可以划分成几个阶段,例如划分成三个阶段就可以是:取指、译码、执行。如果每个时钟周期只完成三个阶段其中之一的工作,那么就可以缩小时钟间隔,提高时钟频率。因为执行阶段耗时一般比取指和译码更长,而时钟周期必须以耗时最长的阶段为准,所以可以把执行阶段的任务继续拆解,划分成五个阶段:
取指:从指令存储器读出指令,同时确定下一条指令地址; 译码:对指令进行译码,识别指令,确定将要使用的执行单元和寄存器,并从寄存器中读出要使用的值; 执行:按照译码器给出的操作数和运算类型,使用对应的执行单元进行运算,给出运算结果; 访存:如果执行的是访存功能的指令,就会访问数据存储器,否则只将执行阶段的结果传递到写回阶段; 写回:将运算结果保存到目标寄存器。如下图所示,如果五个阶段的时间非常平均,都是完成全部任务的五分之一,那么频率就可以提高5倍。但由于每条指令需要5个时钟周期,因此与单周期处理器相比,实际性能并没有提升。

多周期处理器指令时空图
我们可以看到,多周期处理器要完成一条指令之后才处理下一指令,每个时钟周期都只有一个阶段的电路在有效工作,其它电路都处于闲置状态。很容易想到,只要把闲置的部分也利用起来,处理器的运行效率就能提高数倍。
像下图中示意的这样,在第1条指令的第一个阶段完成后,就立即启动第2条指令。在第6个时钟周期时启动第6条指令,此时第1条指令运行完成,还有4条指令在流水线中次第前进。以此类推,n个时钟周期启动n条指令,所有阶段的电路都被充分利用,这就是指令流水线。与多周期处理器相比,分成五个阶段的流水线,就有5倍的指令吞吐量。与单周期处理器相比呢,又保留了多周期处理器能达到更高频率的优点。
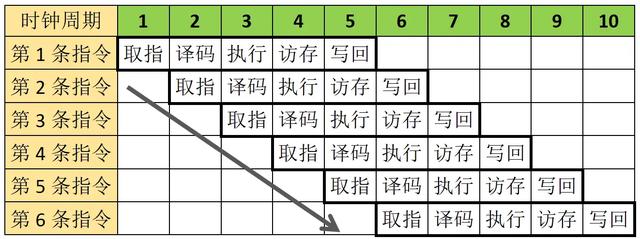
流水线处理器指令时空图
流水线级数不是越多越好既然多级流水线有这么多优点,那么把指令功能继续细分,比如分成一万个阶段,也就是10000级的流水线深度,是否就能把CPU频率提高到10000倍,指令吞吐量也达到10000倍呢?没有哪款CPU是这种做法,就说明这样的推论无法成立。不说10000级深度的流水线,Intel已经通过Pentium 4证明了:31级流水线深度就已经是得不偿失的设计。
超长流水线物极必反的原因,主要有以下几点:
指令功能可以细分的程度有限。Pentium 4最后型号的流水线达到了31级,但大多数指令功能无法细化到31个步骤,在运行这些指令时,流水线中大多数级别只有把上一级的结果传递给下一级的用途,等于这些电路大部分情况下是空闲的、浪费的。功耗不易降低。首先,在运行大多数指令时,31个阶段的大部分电路只是在浪费电能。然后,芯片的功率与频率成正比,与电压的平方成正比,通过多级流水得到的高频率也同时造成了高功耗。总之,Pentium 4没能通过高功耗获得对应的高性能。分支预测失败的损失大。Pentium 4是4发射的处理器,流水线分为31级,等于同时有124条指令处于流水线的不同阶段,一旦分支预测失败就必须清空流水线,会导致浪费掉124条指令的执行时间。动态调度效率低下。任何两条指令之间如果存在依赖关系,它们就不能在流水线中并行执行。Pentium 4的流水线可以容纳124条指令并行,但在指令流中很难找到那么多临近的且没有依赖关系的指令。另外,如果ALU等单元已被占用,后面依赖相同单元的指令就必须被阻塞,超长流水线会因阻塞浪费掉更多的时钟周期。因为这些原因,流水线经常处于饥饿状态,无法如预想的那样达到极高的吞吐率。当前大多数高性能CPU流水线是分为10~20级,嵌入式CPU流水线大多在5级左右。CPU必须面向产品用途和工艺水平,对频率、效率、功耗进行取舍,并据此设计流水线。各类CPU常见的流水线深度,都是通过无数次的实践得到的宝贵经验。
多发射就是超标量从单周期处理器到指令流水线,通过指令级的并行,已经实现了CPU性能的巨大跨越。在此基础之上,还能进一步扩展出多发射的数据通路,使并行的指令数量为流水线级数乘以发射数。
前面讨论的是单发射的指令流水线,流水线的每一级在每一个时钟周期,只能处理一条指令的一个功能阶段。多发射就是实现多条流水线,多条流水线能同时处理多条指令的同一个功能阶段。
像下图中这样,取指级在同一个时钟周期从指令存储器取出两条指令,译码级同时给两条指令译码,后续的各级也是一样同时运行两条指令的功能。这种每一级都同时处理两条指令的流水线技术就是双发射。还可以继续扩展以增加并行的指令数量,目前主流性能的CPU产品一般是6到8发射。

双发射处理器流水线时空图
单发射流水线中的指令,严格地说只是重叠了执行时间,但仍然是顺序的,每个周期只能发射一条指令。多发射流水线中的指令是真正地在并行处理,这种并行的模式称为超标量,多发射流水线也就叫做超标量流水线。
超标量结构需要数量更多的处理器资源,否则无法实现高效的多条流水线。取指需要一次取出多条指令,译码器的数量则一般不低于发射数。ALU(算术逻辑单元)、FPU(浮点运算单元)、VPU(向量运算单元)等可以少于发射数,因为在指令被提交之前,会通过指令重排序、阻塞执行等方式,以避免出现资源冲突的情况。但各种功能单元如果数量充足,就可以并行处理多个同类型计算,使效率得到提升。
因为流水线中正在处理的指令数量等于发射数乘以流水线级数,所以在4发射以上的处理器上,曾经困扰Pentium 4的动态调度、分支预测等问题也同样突出。只能通过更大的重排序缓冲区、更复杂的调度算法、更巧妙的分支预测方法等来减少影响。这些方面,以及多发射的运行控制和资源调度,都是特别考验CPU设计水平的地方。
不同团队,或者同一个团队在不同时期设计的CPU,即使是同样的发射数,效率也天差地别。例如龙芯在2006年就产品化了第一代4发射CPU核,但直到2020年仍在迭代4发射的设计,虽然都是4发射,但相同频率下的性能却提高到了4倍。在迭代4发射CPU核的同时,龙芯也陆续设计了6发射、8发射的CPU核心,现今龙芯CPU在相同频率下的性能已经跻身世界最先进的行列。
流水线级数、发射数,只是CPU结构框图和参考手册中能看到的部分,但这些参数并不能直接体现CPU企业的技术积累和设计水平。能说明一切的,只有CPU的性能。在相同的核心数量下,在相同的工艺水平下,性能最高的CPU,其设计团队就一定具有最强的实力。
