编辑 | 言征、伊风
出品 | 51CTO技术栈(微信号:blog51cto)
在炒作将近9个月后,OpenAI代号“草莓”的模型o1终于深夜突然亮相,一时间具备试用资格的大牛纷纷开始了测评,业内许多AI项目、公司的大佬如英伟达高级研究经理JimFan、Devin的DeepWisdom创始人纷纷发表了自己对于o1的使用感受。
整体上看分两派:一派认为o1代表着Scaling Law以外的新赛道的开启,另一派则认为——
“炒作大于实际”、“有坑”、“很难说”。
这里不再花篇幅去介绍这款主打“慢思考”的模型的官宣能力。仅仅长话短说地列举开发者最关心的几个信息。
一、开启复杂任务推理新赛道通用模型GPT5发布前,开启复杂推理模型赛道OpenAI o1。o1在回答前,会反复的思考、拆解、理解、推理,然后给出最终答案。
通过Self-play RL,o1学会了回溯、打磨自己的思维链并完善所使用的策略,学会了将复杂步骤拆解为更简单的子步骤,并能识别和纠正自己的错误。

o1工作原理:先思考,再总结输出 图源:赛博禅心
二、两款:preview主打强推理,mini主打代码o1-preview:预览版具有很强的推理能力和广阔的世界知识,但还没有达到满血o1的性能,还会持续更新和改进;
o1-mini:更快、更便宜(o1-mini 比 o1-preview 便宜 80%),在代码方面特别有效,特别适合开发人员使用。
三、速率限制和价格不过主打“慢思考”的草莓,OpenAI对外开放的相当吝啬:竟然以周为单位来计算对话条数:
o1-preview 的每周速率限制为 30 条消息o1-mini 的每周速率限制为 50 条消息而对于开发者而言,只面向Tier5级别(付费超过1000美元)的用户开放,每分钟并发限制20次。
不过,价格上面却是个令人头疼的家伙。
API的价格上,o1预览版每百万输入15美元,每百万输出60美元,o1-mini会便宜一些,每百万输入3美元,每百万输出12美元。
而对于这个价格,赛博禅心认为这个模型有坑:在正常使用中,o1 的开销,会比 4o 贵百倍!因为,从 pricing table 上看,o1 的价格是 4o 的 6 倍,但这是有迷惑性的!o1 计费并不按最终输出,其中间思考过程所消耗的 token,并被视作 output tokens,这意味着 100 tokens 的内容输出,可能会被按 10000 tokens 计费。
这一点也得了“NLP工作站”博主刘聪NLP的认证:内在思维链比思维链长的多。
o1展示的外部思维链:

图片
但内部隐藏的未对齐的思维链却非常长:

图片
四、幕后团队可以看到在基础贡献一栏里,大佬Ilya赫然在列。完整表单见:
https://openai.com/openai-o1-contributions/

图片
此次,OpenAI还特别发布了一支幕后团队的特别短片,来聊聊他们对o1的想法。

图片
第一个发言的男生就是华人面孔,领导了整个o1研发的Mark Chen,他解释了o1的命名背后的原因:“与GPT-4o等以前的型号相比,您可能会感到不同。正如其他人稍后会解释的那样,o1是一个推理模型,因此它会思考更多。”

他从麻省理工大学毕业,已经在OpenAI工作了6年之久,现任研究副总裁一职。

图片
五、网友实测1.9.8和9.11的无限反思小红书网友@小水刚醒 反馈,“一上难度就崩溃……让模型比较9.8和9.11的大小,结果无限循环发疯般CoT”

图片
另一位网友@ChRlesWaa在评论区吐槽o1依旧没主见,“很垃圾,和以前一样一反问就改答案”。

图片
2.卡兹克:“中秋国庆调休”问题没有翻车“这是中国2024年9月9日(星期一)开始到10月13日的放假调休安排:上6休3上3休2上5休1上2休7再上5休1。
请你告诉我除了我本来该休的周末,我因为放假多休息了几天?”
在o1思考了整整30秒以后,给出了一天不差的极度精准的答案。

图片

图片
不过据小编观察,卡兹克这次的提问应该有运气的成分,因为有其他博主测试了同样的问题,翻车了:最后的回答是多休了2天~
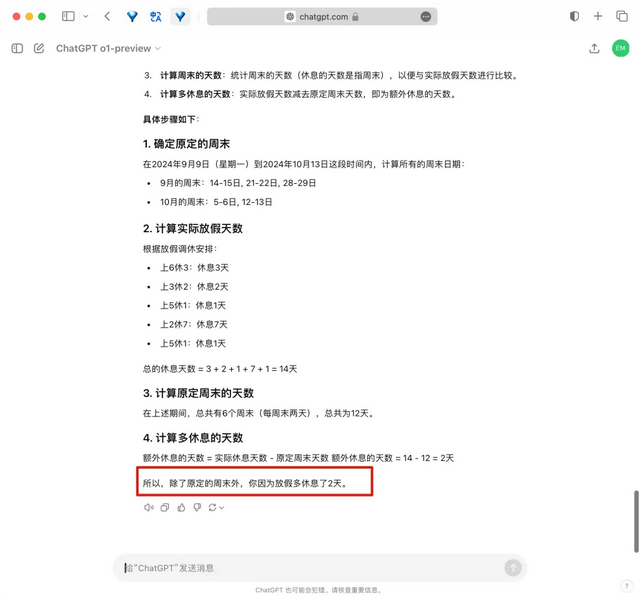
图片
3.赛博禅心:有坑,更像是工程优化赛博禅心随后进行了与其说是模型优化,不如说是工程优化

图片
因为他从训练数据和训练时间发现,o1的截止时间是2023年10月,而GPT-4-turbo的时间则更晚是2023年12月,新旧立见了~ GPT-4在o1之后。
此外,o1与4o的输出语言风格高度类似,可以猜测是草莓视4o进行对齐之后的agent版本。

图片
4.预训练工程师:小修小补,很难说是突破小红书上的一位大模型预训练算法工程师,则发表了更为消极的看法,“深夜看到o1发布,感觉我的职业生涯结束了”,他认为o1实际还在做“小修小补”,并且也将难以看到范式上的其他突破了。他说,未来的方向也许是“功能专精模型和多模态真正融合”。

图片
六、Devin:自我反思与传统提示词的革新时刻过去几周跟OpenAI有密切合作的Cognition团队也第一时间对o1的推理能力进行了测试。
团队使用简化版本的Devin进行了测试,与4o相比,o1具有惊人的反思和分析能力。它通常会回溯并考虑不同的选择,然后才能得出正确的答案,并且产生幻觉或自信的错误的概率也很低。
并透露:使用o1-preview时,Devin更容易正确诊断问题的根本原因,而不是解决问题的症状。
并举了一个例子:Devin遇到了一个错误,o1就像人类一样搜索互联网,并经过几步后找到了与其问题相关的Github问题。
但是,o1需要的提示词明显更加密集,对混乱和不必要的token也会更加敏感。传统的提示词方法通常会有冗余,这会对o1的性能造成负面影响。
不过关于这一点,有人士发表了不同的看法,AI沃茨体验o1后表示:以前的提示词模版还能继续沿用几个月。

图片
七、JimFan:o1的飞跃不再是Scaling Law,而是搜索英伟达大佬Jim Fan透露o1的重点从此前的“学习”转向了“搜索”,也就是说,此次让o1能力飞跃的不再是scaling law了。他的完整贴文翻译如下:
OpenAI Strawberry (o1) 发布了!我们终于看到推理时间缩放的范式在生产中流行并得到部署。正如Sutton在《苦涩的教训》中所说,只有两种技术可以无限扩展计算:学习和搜索。现在是转向后者的时候了。
1.你不需要一个巨大的模型来进行推理。很多参数都专门用来记忆事实,以便在像智力问答这样的基准测试中表现良好。可以将推理与知识分开,即一个小的“推理核心”,它知道如何调用浏览器和代码验证器等工具。预训练的计算量可以减少。
2.大量的计算资源转移到了服务推理,而不是预/后训练。LLMs是基于文本的模拟器。通过在模拟器中推出许多可能的策略和情景,模型最终会收敛到良好的解决方案。这个过程就像AlphaGo的蒙特卡洛树搜索(MCTS)一样,是一个被广泛研究的问题。
3.OpenAI 很久以前就已经掌握了推理缩放定律,而学术界最近才刚刚发现。上个月Arxiv上相隔一周发表了两篇论文:
大语言猴子:使用重复采样扩展推理计算。Brown等人发现DeepSeek-Coder在SWE-Bench上从一个样本增加到250个样本时,性能从15.9%提升到56%,超过了Sonnet-3.5。有关论文可以移步:https://arxiv.org/abs/2407.21787v1
在推理时最优地扩展LLM的计算比扩展模型参数更有效。Snell等人发现,在MATH上,PaLM 2-S 在测试时搜索上击败了一个体积大14倍的模型。4.将 o1 投入生产要比达到学术基准更加困难。对于野外的推理问题,如何决定何时停止搜索?奖励函数是什么?成功标准是什么?何时调用代码解释器等工具?如何考虑这些CPU进程的计算成本?他们的研究文章中没有分享太多相关信息。
5.Strawberry 很容易变成一个数据的飞轮。如果答案是正确的,整个搜索跟踪就成为一个小型的训练样本数据集,其中包含正面和负面的奖励。这反过来会改进未来版本的GPT的推理核心,就像AlphaGo的价值网络——用来评估每个棋盘位置的质量——随着MCTS生成越来越精细的训练数据而改进一样。

图片
八、MetaGPT创始人吴承霖:没有其他秘密,最简单的自我博弈DeepWisdom公司CEO吴承霖深夜发出了自己的想法:(裸推理极限)
1.self-play 可行,设计空间也不大
2.OpenAI 只做了最简单的 self-play
3.记忆模块仍然没有任何突破
4.思维模式仍然难以琢磨,很难说 o1 是好的思维模式
5.没有其他秘密,这就是现在的裸推理极限,所以 OpenAI 核心成员都去了其他公司
self-play是一种强化学习手段,可以理解为:智能体通过与自身副本或历史版本进行自我博弈而进行演化的方法。

图片
九、写在最后其实,就连奥特曼自己也承认o1并非完美之作。

图片
不过,当人们实际上手o1时,巨大的落差感可能在所难免。
在OpenAI官方的演示视频中,o1已经在玩量子物理、奥赛数学了,但在实际的测评中,面对9.11和9.8哪个大的“经典老题”时,o1依然自顾自的重复着“wait,9.8 is 9.80”……。不由得让人长叹,“理想很丰满,现实很骨感”。

图片
这体现了模型能力发展中巨大的不平衡,也提醒着我们,即使AI已经看起来如此的聪明,但通往AGI的道路仍然扑朔迷离。
然而,OpenAI找到了一个尚可前进的方向。
在看到o1的命名法则时,有人调侃说,“原来GPT-5永远不会来了”。但是,由o1生成数据进行训练的下一代模型“猎户座”,终将会与人们见面,不是吗?
也许,科技最有魅力的地方,也许不是当下的成果有多么惊艳。而是告诉我们:边界尚未抵达,这里仍有无限期待。
想了解更多AIGC的内容,请访问:
51CTO AI.x社区
https://www.51cto.com/aigc/
来源: 51CTO技术栈
