 来源:PaperWeekly
来源:PaperWeekly本文约3400字,建议阅读10分钟
本文分析了三种来评估模型质量好坏的指标。
单位 | 微软亚洲研究院研究员
研究方向 | 视觉生成
当今视觉生成问题非常火热,文生图,文生视频等方向取得了很好的进展。然而视觉生成中仍然有非常重要的一些问题亟需解决,本文将对这些问题进行梳理。
生成模型的目标是拟合目标数据分布,然而,目标数据分布往往过于复杂,难以直接拟合。因此,往往需要将复杂的信号做拆分,拆分成多个简单的分布拟合问题,再分别求解。根据信号拆分方式的不同,产生了不同的生成模型。
一、视觉信号拆分问题
为什么大语言模型这么成功呢?作者认为,最本质的原因是文本信号拆分具有“等变性”。具体来说,对于一个文本序列 会根据位置把 的联合数据分布拆分成多个条件概率分布拟合问题: 对于一个文本,比如说“我喜欢打篮球”,用自回归的方式进行拟合,那么从“打”回归“篮球”这个任务,和位置没有关系。
也就是说,对于第一个任务 还是第三个任务 ,分布的拟合其实是“一致”的,或者叫“等变”的。因此,可以利用一个模型,同时去解决这些相关性很高的任务。
这里给等变性做一个定义:
对于目标数据分布 拆分的多个子任务 我们用网络 去拟合第 t 个任务 。那么,对于任意的两个任务 t 和 k,如果满足:
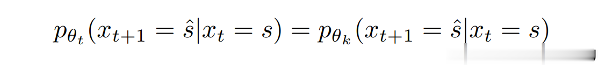
或者

那么,我们称这种任务拆分方式具有等变性(equivariant)。

下面我们从等变性的视角,来重新回顾图像信号的常见拆分方式:图像块拆分,深度拆分,噪声强度拆分,以及可学习拆分。
图像块拆分将图像根据空间位置分成图像块,后面的图像块根据前面的进行生成,代表性的工作有 iGPT [4],DALL-E [5] 等。由于图像不同位置有独立的 inductive bias,具体来说,虽然单行的块内具有连续性,但是一行的最后一个块与下一行的第一个块之间却缺乏这种连续性。
再比如对于人脸数据集,人脸大多出现在图像的中间位置,而不是图像边缘。这些都说明了,根据空间位置来进行划分,不同任务学习目标有差异,不具备“等变性”。
深度拆分的代表性工作包括 VQVAE2 [6],RQVAE [7] 等。一般遵循 coarse-to-fine 的方式进行生成,前期拟合低频信号,后期拟合高频信号。因此,这个学习目标的不同也导致了缺乏“等变性”。此外,这类方法还可能导致“无效编码”问题,我们将在后文介绍。
扩散模型根据噪声强度对图像信号进行拆分。对于数据集中的图像 ,我们将其加噪成一个序列 ,其中 几乎是纯噪声,生成过程在解决 N 个去噪任务:。然而,之前的工作(MinSNR,eDiff-I)发现尽管都是去噪任务,但是不同噪声强度之间仍然有很大的冲突,不具备“等变性”。
最后一类是可学习的拆分方式。代表性工作包括 VDM [8],DSB [3] 等等。这类想法大多基于扩散模型的噪声强度拆分,不过加噪过程是学习得到的,而不是提前的定义好的。其中 VDM 学习加噪过程中的参数,DSB 通过一个网络来学习如何加噪。然而,这些工作目前只是有潜力保证“等变性”,在实践中尚未成功。此外,他们目前仍然存在一些挑战(SDSB [2])。
“不等变性”导致的问题是:既然各个任务有冲突,那我们用不用共享参数的模型来拟合这些分布呢?如果用,那共享参数的模型很难拟合这些不一样的任务,如果不用,会导致模型的参数量爆炸,实际不可行。实践中可能会同时使用多种信号拆分方式来简化分布复杂度,作者认为会存在一种“等变”的信号拆分方式。
基于图像信号拆解的“非等变性”,会引发一系列问题。文章的后续章节讨论的问题和图像拆解的“等变性”都息息相关。下面将简单进行介绍:
二、Tokenization问题

Tokenization 的作用是将高维数据分布以“相对无损”的方式压缩成低维分布,这通常更有利于数据分布的拟合。
如果采用 RQVAE 进行编码,很容易出现当编码长度比较长的时候,后续的编码不能帮助提升重建质量,甚至对重建质量有损害的问题。作者通过一定的数学简化,对该问题提供了一个直观的解释,分析了该问题出现的原因。
假设 D 代表解码器,I 代表原始输入图像。不同深度的编码由 x0,x1,x2,…xN 表示,其中 N 是编码的深度在本例中假设为 4。
因此,RQVAE 的重构损失 L 可以被认为是以下四个重构损失的组合:

为了简化分析,提出两个假设。首先,假定解码器执行线性变换,以便更简单地分析结果。其次,按照常规配置,对四种损失赋予相同的权重。基于这些假设,可以按以下方式简化重构损失的计算:

因此,最小化图像级重构损失的潜在空间表示将是:

这不能保证 x0+x1+x2+x3 比 x0+x1+x2 更接近 arg min X。假设不同深度的编码共享一个通用代码本,并独立同分布,那么后者肯定比前者更接近理论最小值。因此,这导致了无效编码问题。
三、扩散模型是最大似然模型吗?
尽管 DDPM 从最大似然的角度出发,推导了扩散模型的理论。然而,有很多发现似乎表明,扩散模型并非最大似然模型。
VDM++ [9] 证明了,当不同噪声强度处的损失函数权重满足单调关系时,扩散模型是最大似然模型。然而,实际训练中,往往并不采用这样的损失函数权重。在测试阶段,Classifier-free guidance 的采用也使得优化目标不再是最大似然。在评估阶段,直接用 NLL 损失作为衡量指标,并不能准确评估生成模型的好坏。这都引出了一个问题:为什么最大似然的方法并不能获得最优的结果?针对该问题,作者从“等变性”的角度,给出了一种理解方式。
得分匹配与非规范化最大似然密切相关。通常,得分匹配可以避免最大似然学习中学到的所有数据点的等概率的倾向。对于某些特殊分布,如多元高斯分布,得分匹配和最大似然是等价的。
VDM++ 的研究表明,使用单调损失权重 ω(t) 实际上等同于为所有中间状态最大化 ELBO。然而,单调权重并不能表征不同噪声强度任务的训练难度差异。
如前所述,图像数据通常不具备这种等变性。在实际训练中,学习似然函数的难度随噪声强度变化;直观上,最大的困难出现在中等噪声水平,在这里似然函数往往学习得不够准确。在生成过程中,使用无分类器引导可以看作对学习不佳的似然函数的矫正。
在模型评估过程中,鉴于不同噪声水平的任务对最终结果的重要性不同,对这些 NLL 损失应用相同权重无法有效衡量最终生成输出的质量。
四、怎么平衡扩散模型中不同噪声步间的冲突?
从 VDM++ 的训练损失出发:

要调节训练过程中不同噪声强度的冲突,要不改变损失函数 ,要不改变采样频率 。理论上两者是等价的,然而实际训练过程中,改变 相当于改变 learning rate,改变 相当于给更重要的任务提供了更大的采样频率,增多了这部分任务的计算量(Flops),这往往比改变损失函数更有效。最近的工作 [1] 经验性的给出了一种解决方案。然而,对于不同的数据分布,如分辨率不同时,最优的噪声策略会不一样,该方向值得继续探索。
五、扩散模型存在scaling law吗?
大语言模型的成功很大程度上归功于 scaling law。对于扩散模型,存在 scaling law 吗?
这个问题的关键在于采用什么指标来评估模型质量的好坏。文章中分析了三种做法:
1. 用 [1] 中的难度系数当重要性系数,给不同任务的损失加权,当成衡量指标。对模型参数量,训练迭代次数和最终性能的关系分别建模,可以得到下面的结果。然而,该指标不能确保与人类的偏好完全一致。

2. 利用已有的生成模型衡量指标,如 FID 等。这类方法有两个问题,第一,FID 等指标自身的 bias,比如 FID 假设数据抽取特征后的分布满足高斯分布,这会带来系统误差。第二,这些指标是在衡量生成数据分布和目标分布直接的差异,这在 in-the-wild 场景下可能会产生和人类偏好的差异。
3. 直接采用人工标注衡量模型质量。收集好大量文本-图像数据,用生成模型从这些文本生成图像,并让用户评估生成结果和 ground truth 的偏好度,该指标可以作为模型 scaling law 的衡量指标。这种做法的缺点是需要大量人力,但是可以对生成结果做到真正的 align。并且可以指导测试方法的选择。
参考文献
[1] Hang, Tiankai, and Shuyang Gu. 'Improved Noise Schedule for Diffusion Training.'arXiv preprint arXiv:2407.03297 (2024).
[2] Tang, Zhicong, et al. 'Simplified Diffusion Schr\' odinger Bridge.'arXiv preprint arXiv:2403.14623 (2024).
[3] De Bortoli, Valentin, et al. 'Diffusion schrödinger bridge with applications to score-based generative modeling.'Advances in Neural Information Processing Systems 34 (2021): 17695-17709.
[4] Chen, Mark, et al. 'Generative pretraining from pixels.'International conference on machine learning. PMLR, 2020.
[5] Ramesh, Aditya, et al. 'Zero-shot text-to-image generation.'International conference on machine learning. Pmlr, 2021.
[6] Razavi, Ali, Aaron Van den Oord, and Oriol Vinyals. 'Generating diverse high-fidelity images with vq-vae-2.'Advances in neural information processing systems 32 (2019).
[7] Lee, Doyup, et al. 'Autoregressive image generation using residual quantization.'Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[8] Kingma, Diederik, et al. 'Variational diffusion models.'Advances in neural information processing systems 34 (2021): 21696-21707.
[9] Kingma, Diederik, and Ruiqi Gao. 'Understanding diffusion objectives as the elbo with simple data augmentation.'Advances in Neural Information Processing Systems 36 (2024).
