这里所有文章均来自
微信公众号“火星AIGC”
想要看到更多更新的AI前沿信息、AI资讯和AI工具实操,请关注微信公众号“火星AIGC”。
昨晚Meta开源发布了多个模型、工具和数据集,包括 Chameleon 多模态大模型、文生音频模型 AudioCraft 、音频加水印工具 AudioSeal等。
Chameleon 大模型
之前 Meta已经发布过该大语言模型的,我之前的文章也有介绍。
Chameleon 这款多模态大模型的主要特点就是可以文本和图像同时输入和混合输出。这次正式开源的 Chameleon 7B 和 34B两款模型,并不是之前发布介绍完整版,发布的这两款模型只支持文本图像混合模式输入和纯文本输出,且仅能研究性使用。Meta宣称不会发布 Chameleon 图像生成模型。
论文地址:
arxiv.org/abs/2405.09818
模型获取地址:
ai.meta.com/resources/models-and-libraries/chameleon-downloads/?gk_enable=chameleon_web_flow_is_live
Multi-token Prediction 多词预测
这是新的关于大语言模型的训练方法。目前大语言模型训练都有一个简单的训练目标:预测下一个单词。虽然这种方法简单且可扩展,但效率也很低。它需要的文本比儿童学习相同程度的语言流利程度所需的文本多几个数量级。
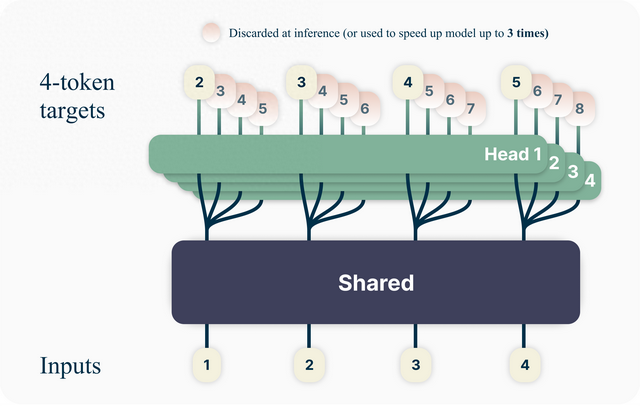
Meta提出多词预测来构建更好、更快的 LLM 。使用这种方法,可以训练语言模型来同时预测多个未来单词,而不是以前每次预测一个单词的方法。这提高了模型能力和训练效率,同时提高了速度。Meta根据非商业/研究专用许可证发布预训练模型以供代码完成。
论文地址:
arxiv.org/abs/2404.19737
模型地址:
huggingface.co/facebook/multi-token-prediction
AudioCraft 文本生成音频
AudioCraft 是一个系列工具,也是一个用于音频生成深度学习研究的 PyTorch 库,包含四个模型和两个编解码器:MusicGen、AudioGen、MAGNeT、AudioSeal以及EnCodec和Multi Band Diffusion。AudioSeal以商用许可开源,其余模型和代码,Meta根据 CC-BY-NC (署名和非商用)协议开源。
MusicGen 是一种最先进的可控文本生成音乐模型。
AudioGen 是最先进的文本生成声音模型。
MAGNeT 是一种用于文本到音乐和文本到声音的最先进的非自回归模型。
AudioSeal 是最先进的给音频添加水印的模型。

EnCodec是用于训练音频的最先进的高保真神经音频编解码器。
Multi Band Diffusion是使用diffusion架构的 EnCodec 兼容解码器。
Meta这次开源了一整套文本生成音频的模型,确实如其所说是最先进的文本生成音频模型,只是应该在其加开源两字。这个系列后面有机会再详细介绍。
论文地址:
arxiv.org/pdf/2406.10970
项目地址:
github.com/facebookresearch/audiocraft
PRISM 数据集
关于人工反馈在大型语言模型 (LLM) 的校准中起着核心作用,人工反馈收集的方法 (如何)、领域 (在哪里)、人员 (谁) 和目标 (目的) 仍然存在悬而未决的问题。Meta发布的PRISM数据集就是为了解答这些问题,该数据集映射了来自 75 个国家/地区的 1,500 名多元化参与者的社会人口统计数据和偏好。
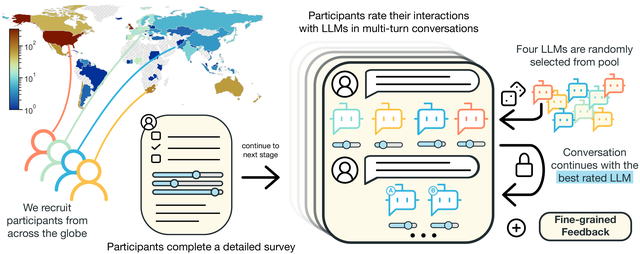
论文地址:
arxiv.org/abs/2404.16019
项目地址:
huggingface.co/datasets/HannahRoseKirk/prism-alignment
DIG In 地理差异指标
DIG In 是用来评估文本转图像模型中的潜在地理差异的自动指标。用来评估当提示生成来自世界各地的对象时,文本到图像生成系统的真实性、多样性和提示生成一致性。方便改进文本转图像模型,以反映出世界的地理和文化多样性。
论文地址:
arxiv.org/pdf/2308.06198
项目地址:
github.com/facebookresearch/DIG-In
虽然Meta 在AI领域一直超不过美国的另外两家,但它一直持续的在做开源AI生态建设,这是非常值得肯定和赞赏的,特别这次开源的AudioCraft 文本到音频的一系列模型,应该是在该领域的顶流,有必要后面另开一篇详细的介绍。
