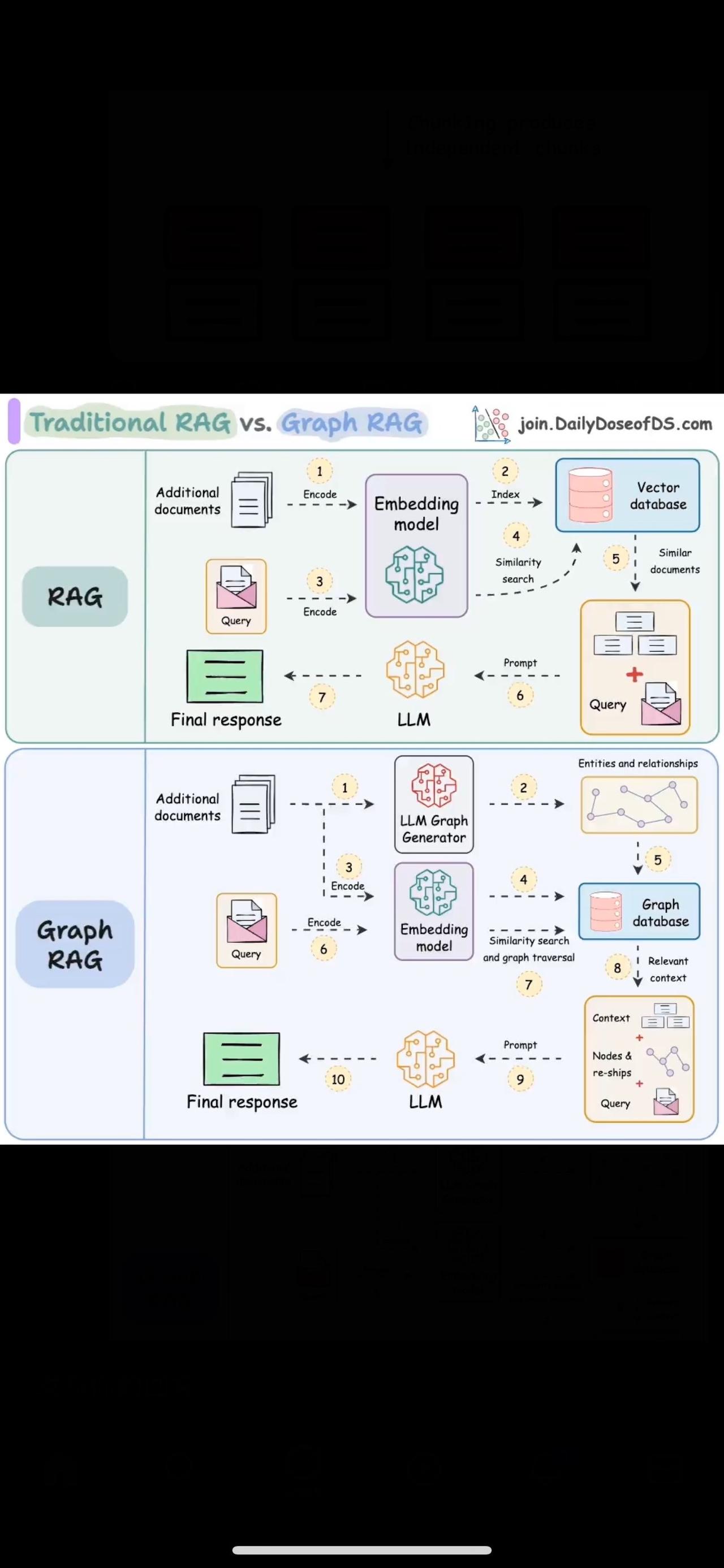
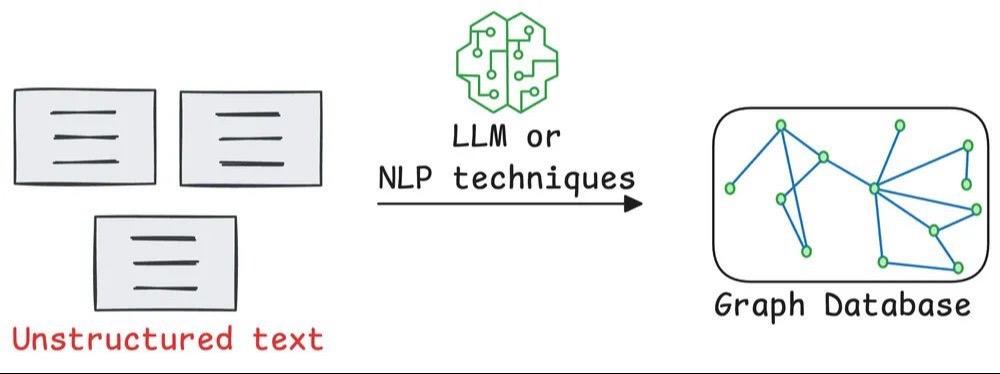
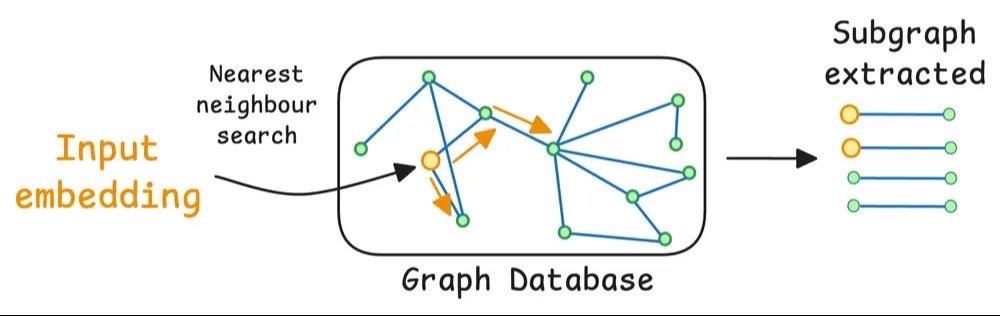
传统 RAG 与 Graph RAG 的清晰解释(带有视觉效果): RAG 中的 top-k 检索很少起作用。 假设您想要总结一本传记,其中每一章都详细介绍了个人的具体成就。 传统的 RAG 很难检索,因为它只检索前 k 个块,而它需要整个上下文。 Graph RAG 通过以下方式解决这个问题: - 使用文档中的实体和关系构建图表。 - 遍历图表以检索上下文。 - 将整个上下文发送给 LLM 以获得回复。 视觉效果显示了它与简单的 RAG 有何不同:我们来看看Graph RAG是如何解决上述问题的。 首先,系统(通常是 LLM)将根据文档创建图表。 该图将包含一个人(P)的子图,其中每个成就都距离 P 的实体节点一跳。 在总结过程中,系统可以进行图形遍历以获取与 P 的成就相关的所有相关上下文。 整个背景将帮助 LLM 得出完整的答案,而天真的 RAG 则不会。 图形 RAG 系统也比朴素 RAG 系统更好,因为 LLM 本质上擅长使用结构化数据进行推理。我希望这能阐明 Graph RAG 是什么以及它可以解决的问题! 我将向您直观地展示它与传统 RAG 相比的工作原理。 程序员 人工智能 软件开发 计算机