
playwright介绍
playwright是一款由微软开源的强大的自动化库,它为现代web应用的自动化测试提供了一整套解决方案。相对于selenium,playwright拥有更高的性能,并且用户不需要频繁下载webdriver以适配浏览器版本。playwright支持chrome、firefox、webkit等浏览器且拥有跨平台支持,提供了TypeScript、JavaScript、Python、.NET、Java多语言API接口,已经有越来越多的用户使用playwright开展自动化测试工作。同时playwright在爬虫方面也表现出色,本文就以爬取百度搜索结果为例讲解playwright的基本使用。详细学习参见Playwright官方文档
安装playwright
首先pip执行下面的命令安装最新的playwright库
pip install playwright安装完成后执行如下命令,此命令会安装Chromium, Firefox and WebKit浏览器,playwright就是控制这些浏览器操作web应用
playwright installplaywright初始化这里以python为例,playwright提供了同步和异步两套api,因为浏览器页面操作明显是IO密集型操作,因此非常适合异步模式,因为异步编程模式可以做到在IO等待期间继续运行其他的任务而不会阻塞当前任务,因此下面的示例使用异步api进行介绍。
playwright初始化部分包括创建playwright的上下文环境、创建浏览器、创建page,下面是官方文档给出的一个入门示例,初始化部分我添加了注释进行说明
import asynciofrom playwright.async_api import async_playwrightasync def main(): # 创建playwright上下文环境 async with async_playwright() as p: # 创建浏览器 browser = await p.chromium.launch() # 创建page page = await browser.new_page() await page.goto("http://playwright.dev") print(await page.title()) await browser.close()asyncio.run(main())上面代码async with async_playwright()的作用是自动管理playwright的上下文环境,比如浏览器关闭后自动清理上下文环境,用户无需关心。不过这个方式可能并不适用有些场景,比如需要主动控制环境的清理时,下面是不使用async with管理上下文的代码示例,这样就不必在同一个方法中创建并清理上下文了,可以自由地控制何时关闭上下文。
import asynciofrom playwright.async_api import async_playwrightasync def main(): # 创建playwright上下文环境 p = await async_playwright().start() # 创建浏览器 browser = await p.chromium.launch() # 创建page page = await browser.new_page() await page.goto("http://playwright.dev") print(await page.title()) await browser.close() # 清理playwright上下文环境 await p.stop()asyncio.run(main())访问页面
在playwright中,Page类用于打开并访问web页面,可以通过Browser直接创建page实例,也可以通过BrowserContext创建page实例,使用同一个BrowserContext的page会共享cookies、本地存储等,可以减少资源的消耗。上面的示例已经给出了使用Browser创建page并访问页面的示例,下面给出使用BrowserContext创建page并访问百度的代码。
import asynciofrom playwright.async_api import async_playwrightasync def main(): # 创建playwright上下文环境 p = await async_playwright().start() # 创建浏览器 browser = await p.chromium.launch() # 创建BrowserContext context = await browser.new_context() # 通过BrowserContext创建page page = await context.new_page() # 打开百度首页 await page.goto("https://baidu.com") # 提取页面标题 print(await page.title()) await browser.close() # 清理playwright上下文环境 await p.stop()asyncio.run(main())操作页面元素到了这里才是真正的重点,必须能够操控页面中的元素才能达到我们想要的目的,比如模拟点击按钮、向表单填写信息、提取页面内容等,这其中首先需要做的是定位页面上的元素。playwright提供了丰富的方法用于定位页面中的元素,建议在使用过程中参考api文档进行使用,这里仅介绍通用的locator方法,page.locator方法根据传入的selector选择器定位相应的元素并返回,selector支持css选择器和xpath形式,关于css选择和xpath不是本文的重点,建议查阅相关的资料。

接下来展示使用css选择器和xpath两种方式达到在百度首页中输入搜索关键词并点击搜索的功能使用css选择器
await self.page.goto("https://www.baidu.com")# 定位id=kw的input元素并输入搜索内容await self.page.locator('#kw').fill("python")# 定位id=su的搜索按钮并点击await self.page.locator('#su').click()使用xpath
await self.page.goto("https://www.baidu.com")# 定位id=kw的input元素并输入搜索内容await self.page.locator('xpath=//input[@id="kw"]').fill("python")# 定位id=su的搜索按钮并点击await self.page.locator('xpath=//input[@id="su"]').click()关于提取页面信息,locator.get_attribute(name)提取name对应属性的值,locator.input_value()获取input元素的value值,locator.inner_text()获取元素中的文本,locator.inner_html()获取元素内的html内容,locator.text_content()获取元素内的所有文本节点的文本信息,它与inner_text()不同之处在于inner_text只会取元素本身的文本,而不会取子元素的文本。
前面示例代码中提到的await page.title()用于获取整个页面的标题,而如果要获取整个页面的响应源码则直接获取await page.goto()方法的返回值即可。
完整的例子
最后,给出一个完整的示例来结束本章的内容,它实现的功能是通过关键词进行百度搜索,提取搜索结果中的标题和真实URL链接,并可以通过参数来控制爬取多少页,这是一个很有实用价值的案例,我重点说明下如何获取搜索结果中的真实链接,至于其他部分并无特别之处,直接参见代码即可。
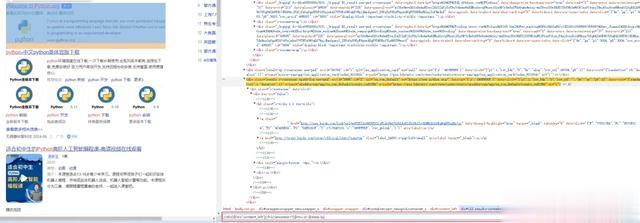
直接查看搜索链接中的href发现它并不是真实的跳转链接,还是百度内部链接,只有点击这个链接再次请求百度才会返回真实的地址并打开真实的网站页面

当然实际去请求一次这个链接确实可以获取到真实的URL,这无疑会消耗更多的时间,我想说的是还有更好的办法取到真实的URL,沿着那个a元素往上找一找会发现真实的url竟然就隐藏在其中的mu属性中,是不是很意外!

别急,仔细梳理每一个搜索结果还会发现有的搜索结果在data-lp属性中,这个url稍有不同,是已经编码过的,只需要简单的解码就可以啦。

分析清楚了,写一个xpath就能轻松定位到它们了。
完整的示例代码
import randomimport asynciofrom urllib.parse import unquotefrom playwright.async_api import async_playwrightclass BaiduCrawler: def __init__(self) -> None: self.playwright = None async def open_browser(self): if self.playwright is None: self.playwright = await async_playwright().start() # --start-maximized:最大化浏览器窗口 self.browser = await self.playwright.chromium.launch(headless=False, args=['--start-maximized']) # no_viewport=True:表示不限定视口的尺寸,这样视口也会最大化显示 self.page = await self.browser.new_page(no_viewport=True) async def search(self, query_content): await self.page.goto("https://www.baidu.com") # 使用xpath # 定位id=kw的input元素并输入搜索内容 await self.page.locator('xpath=//input[@id="kw"]').fill(query_content) # 定位id=su的搜索按钮并点击 await self.page.locator('xpath=//input[@id="su"]').click() async def parse(self): # 等待搜索结果加载完成,避免爬取不到结果 await self.page.wait_for_selector('#content_left') xpath_result = 'xpath=//div[@id="content_left"]//h3//ancestor::*[@mu or @data-lp]' # 查找所有搜索结果 search_results = await self.page.locator(xpath_result).all() for div in search_results: # 提取搜索结果标题 title = await div.locator('xpath=.//h3//a[1]').text_content() # 百度搜索的真实链接在mu或data-lp属性中 link = unquote(await div.get_attribute("mu") or await div.get_attribute("data-lp")) item = { "title": title, "url": link } print(item) async def next_page(self): xpath_next_page = 'xpath=//div[@id="page"]//a[contains(text(),"下一页")]' try: # 如果能够找到下一页这个元素则表示还可以继续爬取,点击下一页并返回True await self.page.wait_for_selector(xpath_next_page) await self.page.locator(xpath_next_page).click() return True except: # 找不到下一页会抛出异常,直接返回False return False async def quit(self): if self.playwright is not None: await self.page.close() await self.browser.close() await self.playwright.stop()async def main(): baidu = BaiduCrawler() await baidu.open_browser() max_page = 6 page_num = 0 await baidu.search("python") await baidu.parse() while await baidu.next_page() and page_num < max_page: await baidu.parse() # 随机等待一段时间,避免爬取过快触发百度反爬 await asyncio.sleep(random.randint(3, 8)) page_num += 1 await baidu.quit()if __name__ == "__main__": asyncio.run(main())运行结果

