本文分为三个章节,深入浅出地解读大模型的技术,具体如下三个部分:
1、GPT、LLaMA、ChatGLM、Falcon等大语言模型的技术细节比较
在深入研究LLaMA、ChatGLM和Falcon等大语言模型时,我们不难发现它们在技术实现上有着诸多共通之处与独特差异。例如,这些模型在tokenizer(分词器)的选择上,可能会根据模型的特性和应用场景来定制;位置编码(Positional Encoding)的实现方式也各具特色,对模型性能的影响不容忽视。此外,Layer Normalization(层归一化)和激活函数(Activation Function)的选择与运用,都直接影响到模型的训练速度和准确性。
2、大语言模型的分布式训练技术概览
在训练大语言模型时,分布式技术发挥着至关重要的作用。数据并行(Data Parallelism)确保多个处理单元同时处理不同的数据子集,显著提高训练速度。张量模型并行(Tensor Model Parallelism)和流水线并行(Pipeline Parallelism)则针对模型的不同部分进行分布式处理,进一步优化了计算资源的利用率。3D并行则进一步拓展了分布式计算的维度。
同时,零冗余优化器ZeRO(Zero Redundancy Optimizer)和CPU卸载技术ZeRo-offload,通过减少内存占用和提高计算效率,进一步加速了训练过程。混合精度训练(Mixed Precision Training)则通过结合不同精度的计算,平衡了计算速度与内存占用。激活重计算技术(Activation Recomputation)和Flash Attention、Paged Attention等优化策略,则进一步提升了模型的训练效率和准确性。

3、大语言模型的参数高效微调技术探索
在微调大语言模型时,参数的高效利用成为关键。Prompt Tuning、Prefix Tuning和Adapter等方法,通过调整模型的部分参数而非全部,实现了高效的模型定制。LLaMA-Adapter和LoRA等技术则进一步优化了这一过程,使模型能够更快地适应新的任务和领域,同时保持较高的性能。
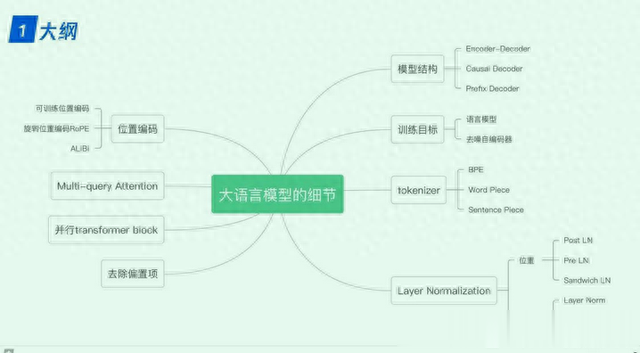
 1. 大语言模型的细节1.0 transformer 与 LLM
1. 大语言模型的细节1.0 transformer 与 LLM 1.1 模型结构
1.1 模型结构 1.2 训练目标
1.2 训练目标 1.3 tokenizer
1.3 tokenizer 1.4 位置编码
1.4 位置编码 1.5 层归一化
1.5 层归一化 1.6 激活函数
1.6 激活函数 1.7 Multi-query Attention 与 Grouped-query Attention
1.7 Multi-query Attention 与 Grouped-query Attention 1.8 并行 transformer block
1.8 并行 transformer block 1.9 总结-训练稳定性
1.9 总结-训练稳定性 2. LLM 的分布式预训练
2. LLM 的分布式预训练 2.0 点对点通信与集体通信
2.0 点对点通信与集体通信 2.1 数据并行
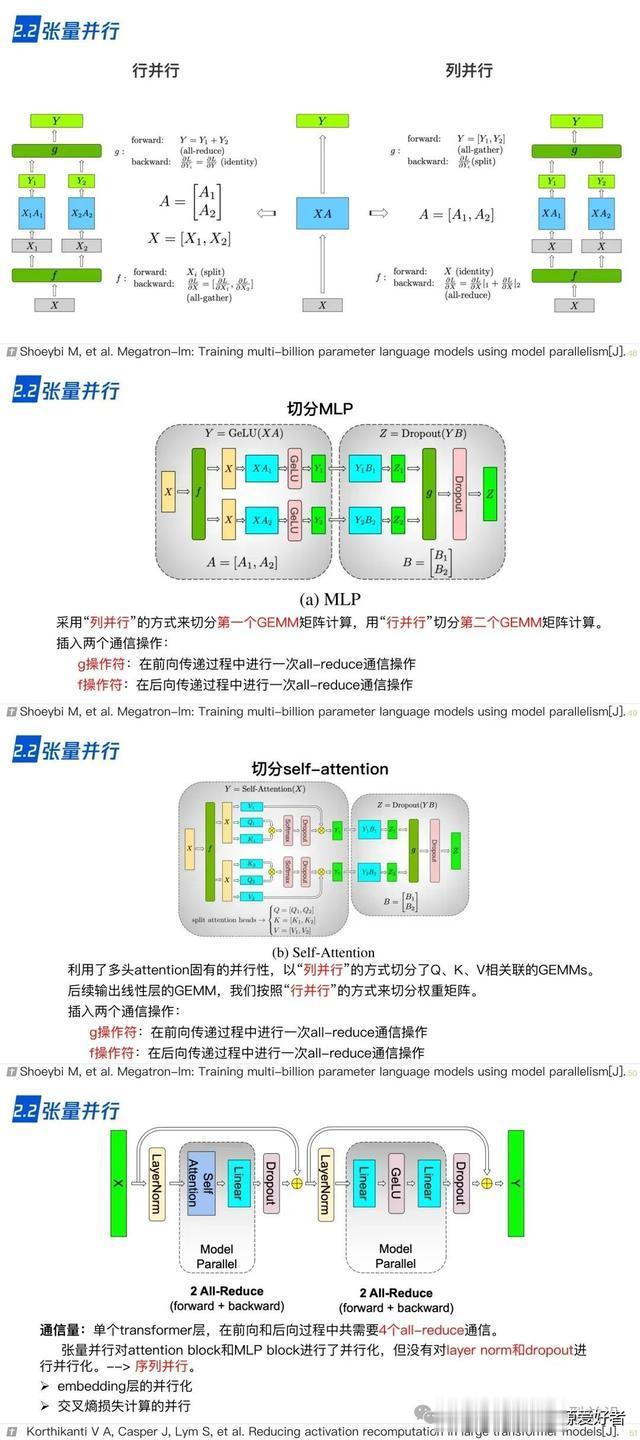
2.1 数据并行 2.2 张量并行
2.2 张量并行
 2.3 流水线并行
2.3 流水线并行 2.4 3D 并行
2.4 3D 并行 2.5 混合精度训练
2.5 混合精度训练 2.6 激活重计算
2.6 激活重计算 2.7 ZeRO,零冗余优化器
2.7 ZeRO,零冗余优化器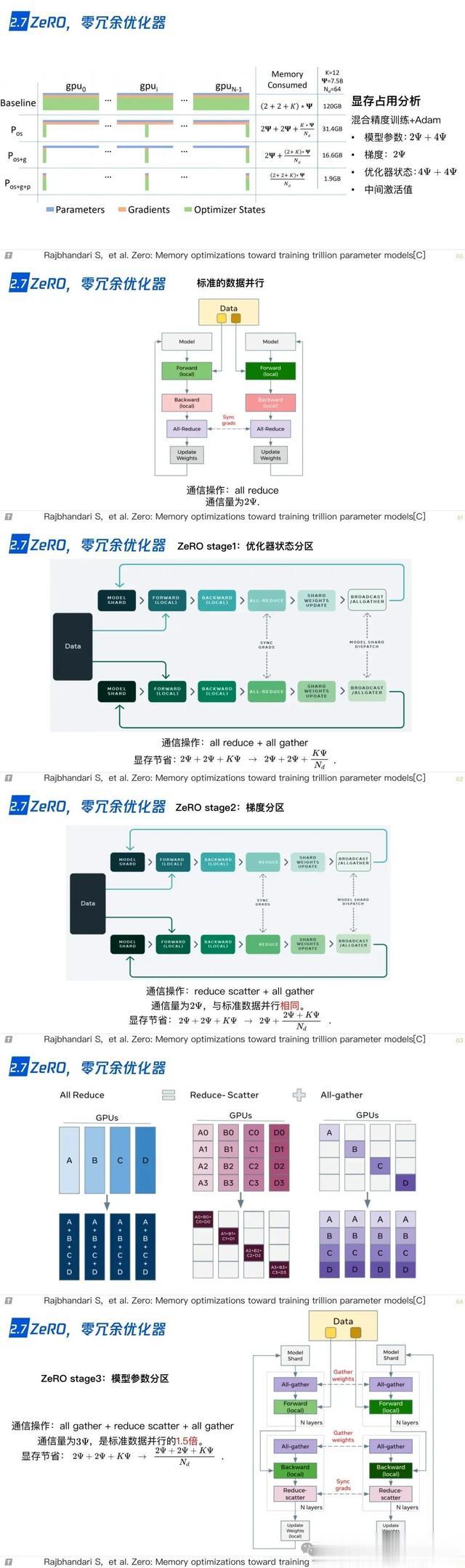 2.8 CPU-offload,ZeRO-offload
2.8 CPU-offload,ZeRO-offload 2.9 Flash Attention
2.9 Flash Attention 2.10 vLLM: Paged Attention
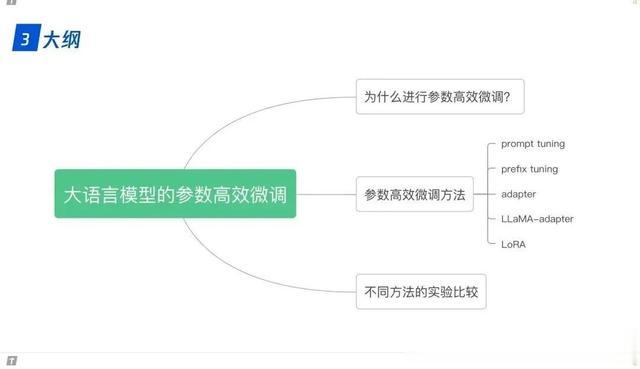
2.10 vLLM: Paged Attention 3. LLM 的参数高效微调3.0 为什么进行参数高效微调?
3. LLM 的参数高效微调3.0 为什么进行参数高效微调? 3.1 prompt tuning
3.1 prompt tuning 3.2 prefix tuning
3.2 prefix tuning 3.3 adapter
3.3 adapter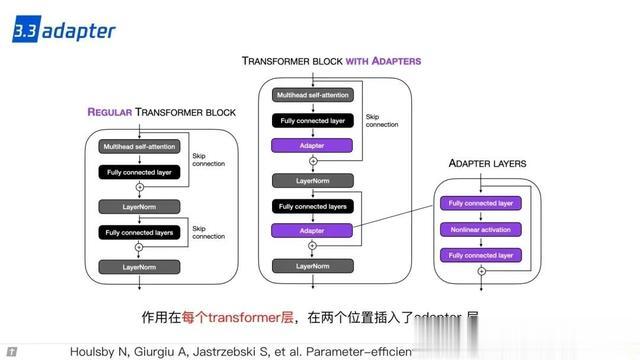 3.4 LLaMA adapter
3.4 LLaMA adapter 3.5 LoRA
3.5 LoRA 3.6 实验比较
3.6 实验比较
4. 参考文献


引用地址:https://mp.weixin.qq.com/s/vNVjrCZ1bfBRi5YGiHxJpw
