在大数据、云计算、人工智能和物联网普及的5G时代,数据在每时每刻的生成、传输、分析。尤其是在各种智慧物联网平台中,实时指标监控是平台的一项基本功能,通过对传感器收集到的数据进行汇总统计,形成实时监控仪表盘。但在实际运行中,除了对实时指标数据的监控,我们更关心未来指标的变化趋势,从而“预知未来,提前规划”这就会涉及到时序类数据的预测问题。时序类数据的预测在很多重要领域均有应用,比如:预测销售额、预测呼叫中心的来电数量、预测太阳活动和海洋潮汐、预测股市行为等。
目前,时序类数据预测算法经过多年来的研究和实践,常用算法主要有以下几类:简单平均数、移动平均数、指数平滑法、霍尔特线性趋势预测、Holt-Winters季节性预测模型、自回归差分移动平均模型(ARIMA模型)、转化为监督学习数据集,使用xgboot/LSTM模型/时间卷积网络/seq2seq(attention_based_model)、Facebook-prophet【类似于STL分解思路】、深度学习网络(LSTM)等。
作者以某污水厂智慧水务平台的指标数据作为案例分析数据,经过大量实证交叉验证发现LSTM在时序类数据的预测中明显优于其他算法。
LSTM算法介绍预测算法功能:实现通过一段时间内【如前300min】的辅助变量数据预测未来一段时间【如未来120min】的主导数据预测,例如:利用溶解氧含量、氨氮含量、硝氮含量等辅助变量的历史数据实现对氨氮含量这一主导变量未来一段时间【120min】的数值趋势,具体可分为单变量预测和多变量预测。
算法原理:
LSTM算法是深度学习中解决序列类问题的一个常用算法,在传统RNN中引入“输入门、记忆门、输出门”,解决了传统RNN梯度爆炸和梯度消失的问题,是目前解决序列类分类和回归预算问题的一个常用算法。算法原理图如下:
 算法核心代码class AiPredictTrainor(object): """ AI软测量技术,实现根据辅助变量预测主导变量,多步预测 """ def __init__(self, model_name="soft_measure_pca.h5"): self.model_name = model_name def deal_abnormal_sigma(self, data, thld=3): """异常值处理函数,3sigma原理""" base_mean = np.mean(data) base_std = np.std(data) upper = base_mean + thld * base_std lower = base_mean - thld * base_std data = np.where(data > upper, np.NaN, data) data = np.where(data < lower, np.NaN, data) return data def deal_abnormal_iqr(self, data, thld=3): iqr = np.percentile(data, 75)-np.percentile(data, 25) upper = np.percentile(data, 75)+thld*iqr lower = np.percentile(data, 25)-thld*iqr data = np.where(data > upper, np.NaN, data) data = np.where(data < lower, np.NaN, data) return data def fill_nan(self, data): """值法填充缺失值""" for f in data: data[f] = data[f].interpolate() data = data.fillna(method="bfill").fillna(method="ffill") return data def pca_data(self, data, n_component=0.98): "主成分分析" pca = PCA(n_components=n_component) pca.fit(data) data_pca = pca.transform(data) self.pca = pca joblib.dump(pca, self.model_name.split(".")[0]+".pkl") return data_pca def get_dataset(self, data, target, history_size, target_size, pca=False): n = data.shape[0] range_size = history_size + target_size if pca: data_x = self.pca_data(data) x = [data_x[i:i + history_size] for i in range(n - range_size + 1)] else: x = [data[i:i + history_size] for i in range(n - range_size + 1)] y = [data[i:i + target_size, target] for i in range(history_size, n - target_size + 1)] x = np.array(x, dtype=np.float32) y = np.array(y, dtype=np.float32) x_train, x_test, y_train, y_test = train_test_split( x, y, test_size=TEST_SCALE) return x_train, x_test, y_train, y_test def train(self, data, target=20, history_size=300, target_size=120, pca=False, deal_abnorm=None, lstm_num=[128, 64, 32, 16, 8], full_num=[2000, 1000, 500], drop_out=False, epochs=100): """构建模型""" if deal_abnorm == "sigma": data = data.apply(self.deal_abnormal_sigma) elif deal_abnorm == "iqr": data = data.apply(self.deal_abnormal_iqr) data = self.fill_nan(data) dataset = data.values train_mean, train_std = dataset.mean(axis=0), dataset.std(axis=0) scaler = StandardScaler() scaler = scaler.fit(dataset) dataset = scaler.transform(dataset) joblib.dump(scaler, self.model_name.split(".")[0]+"_scaler.pkl") with open(self.model_name.split(".")[0]+"_scaler_y.pkl", "wb") as f: thld_dict = {"mean": train_mean[target], "std": train_std[target]} pickle.dump(thld_dict, f, True) x_train, x_test, y_train, y_test = self.get_dataset( dataset, target, history_size, target_size, pca=pca) train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train)) train_dataset = train_data.cache().shuffle( BUFFER_SIZE).batch(BATCH_SIZE).repeat() val_data = tf.data.Dataset.from_tensor_slices((x_test, y_test)) valid_dataset = val_data.batch(BATCH_SIZE).repeat() STEP_PER_EPOCH = (len(data)*(1-TEST_SCALE))//BATCH_SIZE VALIDATION_STEPS = (len(data)*TEST_SCALE)//BATCH_SIZE checkpoint_cb = tf.keras.callbacks.ModelCheckpoint( filepath=self.model_name, monitor='val_loss', verbose=1, save_best_only=True, mode='min', period=1) lr_scheduler = tf.keras.callbacks.ReduceLROnPlateau( monitor='val_loss', factor=0.1, patience=5, min_lr=0.0001) early_stopping_cb = tf.keras.callbacks.EarlyStopping( patience=30, restore_best_weights=True ) regressor = tf.keras.Sequential() for cell in lstm_num: regressor.add(tf.keras.layers.LSTM( units=cell, return_sequences=True)) if drop_out: regressor.add(tf.keras.layers.Dropout(0.2)) regressor.add(tf.keras.layers.Flatten()) for full_cell in full_num: regressor.add(tf.keras.layers.Dense(full_cell, activation="relu")) if drop_out: regressor.add(tf.keras.layers.Dropout(0.2)) regressor.add(tf.keras.layers.Dense(units=target_size)) # 模型编译 regressor.compile(optimizer=keras.optimizers.Adam( learning_rate=0.001, clipnorm=1.0), loss='mse') # 模型训练 regressor.fit(train_dataset, epochs=epochs, steps_per_epoch=STEP_PER_EPOCH, validation_data=valid_dataset, validation_steps=VALIDATION_STEPS, callbacks=[checkpoint_cb, early_stopping_cb, lr_scheduler])算法预测结果
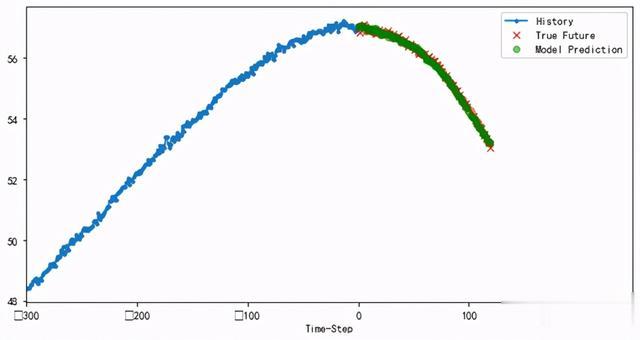
算法核心代码class AiPredictTrainor(object): """ AI软测量技术,实现根据辅助变量预测主导变量,多步预测 """ def __init__(self, model_name="soft_measure_pca.h5"): self.model_name = model_name def deal_abnormal_sigma(self, data, thld=3): """异常值处理函数,3sigma原理""" base_mean = np.mean(data) base_std = np.std(data) upper = base_mean + thld * base_std lower = base_mean - thld * base_std data = np.where(data > upper, np.NaN, data) data = np.where(data < lower, np.NaN, data) return data def deal_abnormal_iqr(self, data, thld=3): iqr = np.percentile(data, 75)-np.percentile(data, 25) upper = np.percentile(data, 75)+thld*iqr lower = np.percentile(data, 25)-thld*iqr data = np.where(data > upper, np.NaN, data) data = np.where(data < lower, np.NaN, data) return data def fill_nan(self, data): """值法填充缺失值""" for f in data: data[f] = data[f].interpolate() data = data.fillna(method="bfill").fillna(method="ffill") return data def pca_data(self, data, n_component=0.98): "主成分分析" pca = PCA(n_components=n_component) pca.fit(data) data_pca = pca.transform(data) self.pca = pca joblib.dump(pca, self.model_name.split(".")[0]+".pkl") return data_pca def get_dataset(self, data, target, history_size, target_size, pca=False): n = data.shape[0] range_size = history_size + target_size if pca: data_x = self.pca_data(data) x = [data_x[i:i + history_size] for i in range(n - range_size + 1)] else: x = [data[i:i + history_size] for i in range(n - range_size + 1)] y = [data[i:i + target_size, target] for i in range(history_size, n - target_size + 1)] x = np.array(x, dtype=np.float32) y = np.array(y, dtype=np.float32) x_train, x_test, y_train, y_test = train_test_split( x, y, test_size=TEST_SCALE) return x_train, x_test, y_train, y_test def train(self, data, target=20, history_size=300, target_size=120, pca=False, deal_abnorm=None, lstm_num=[128, 64, 32, 16, 8], full_num=[2000, 1000, 500], drop_out=False, epochs=100): """构建模型""" if deal_abnorm == "sigma": data = data.apply(self.deal_abnormal_sigma) elif deal_abnorm == "iqr": data = data.apply(self.deal_abnormal_iqr) data = self.fill_nan(data) dataset = data.values train_mean, train_std = dataset.mean(axis=0), dataset.std(axis=0) scaler = StandardScaler() scaler = scaler.fit(dataset) dataset = scaler.transform(dataset) joblib.dump(scaler, self.model_name.split(".")[0]+"_scaler.pkl") with open(self.model_name.split(".")[0]+"_scaler_y.pkl", "wb") as f: thld_dict = {"mean": train_mean[target], "std": train_std[target]} pickle.dump(thld_dict, f, True) x_train, x_test, y_train, y_test = self.get_dataset( dataset, target, history_size, target_size, pca=pca) train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train)) train_dataset = train_data.cache().shuffle( BUFFER_SIZE).batch(BATCH_SIZE).repeat() val_data = tf.data.Dataset.from_tensor_slices((x_test, y_test)) valid_dataset = val_data.batch(BATCH_SIZE).repeat() STEP_PER_EPOCH = (len(data)*(1-TEST_SCALE))//BATCH_SIZE VALIDATION_STEPS = (len(data)*TEST_SCALE)//BATCH_SIZE checkpoint_cb = tf.keras.callbacks.ModelCheckpoint( filepath=self.model_name, monitor='val_loss', verbose=1, save_best_only=True, mode='min', period=1) lr_scheduler = tf.keras.callbacks.ReduceLROnPlateau( monitor='val_loss', factor=0.1, patience=5, min_lr=0.0001) early_stopping_cb = tf.keras.callbacks.EarlyStopping( patience=30, restore_best_weights=True ) regressor = tf.keras.Sequential() for cell in lstm_num: regressor.add(tf.keras.layers.LSTM( units=cell, return_sequences=True)) if drop_out: regressor.add(tf.keras.layers.Dropout(0.2)) regressor.add(tf.keras.layers.Flatten()) for full_cell in full_num: regressor.add(tf.keras.layers.Dense(full_cell, activation="relu")) if drop_out: regressor.add(tf.keras.layers.Dropout(0.2)) regressor.add(tf.keras.layers.Dense(units=target_size)) # 模型编译 regressor.compile(optimizer=keras.optimizers.Adam( learning_rate=0.001, clipnorm=1.0), loss='mse') # 模型训练 regressor.fit(train_dataset, epochs=epochs, steps_per_epoch=STEP_PER_EPOCH, validation_data=valid_dataset, validation_steps=VALIDATION_STEPS, callbacks=[checkpoint_cb, early_stopping_cb, lr_scheduler])算法预测结果单变量预测结果【用自己的历史数据预测自己】:





多变量预测结果【用别人的历史数据预测自己】: