说到显卡,算力固然重要,懂行的AI专家也都知道显存的重要性,尤其是HBM在处理复杂AI模型和大数据集时的关键作用。
然而,现代显卡内置的显存容量有限,常常限制了它们在AI训练和高性能计算中的表现。
为了解决这个问题,有一家公司想通过PCIe总线连接更多的内存扩展设备,甚至可以使用SSD来扩展显存容量。
这家公司叫Panmnesia,是一家由韩国著名的KAIST研究所支持的公司,它开发了一种低延迟的CXL IP,可以用来通过CXL内存扩展器扩展GPU内存。
CXL是一个运行在PCIe链路上的协议,用户能够通过PCIe总线将更多内存连接到系统。但该技术还必须被ASIC及其子系统识别才行,因此,单单添加一个CXL控制器是不行的。
由于缺乏CXL逻辑结构和支持DRAM和/或SSD端点的子系统,Panmnesia在用CXL给GPU扩展显存时面临很多挑战。
GPU缓存和内存子系统除了能识别统一虚拟内存(UVM)以外,不识别任何内存扩展,但统一虚拟内存(UVM)的性能太差了。

为了解决这个问题,Panmnesia开发了一个符合CXL 3.1标准的根复合体(RC),配备了多个支持通过PCIe扩展外部内存的根端口(RP),以及一个带有主机管理设备内存(HDM)解码器的主桥,该解码器连接到GPU的系统总线。
HDM解码器负责管理系统内存的地址范围,使GPU的内存子系统“认为”它在处理系统内存。但实际上,子系统使用的是连接到PCIe的DRAM或NAND。这意味着可以使用DDR5或SSD来扩展GPU显存池。

据Panmnesia称,该解决方案(基于一些定制的GPU,针对CXL做了优化的,标记为CXL-Opt)经过广泛测试,显示出两位数纳秒的往返延迟(相比之下,三星和Meta开发的原型的往返延迟为250ns),包括标准内存操作和CXL数据传输之间的协议转换所需的时间。
而且,它已经成功集成到内存扩展器和GPU/CPU原型的硬件RTL中,展示了其与各种计算硬件的兼容性。
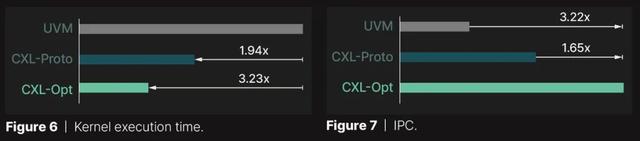
根据Panmnesia的测试,由于主机运行时在页面错误期间的干预开销和页面级别的数据传输,UVM在所有测试的GPU内核中表现最差,这通常无法满足GPU的要求。相比之下,CXL允许通过加载/存储指令直接访问扩展存储,从而克服了这些问题。
因此,CXL-Proto的执行时间比UVM短1.94倍。Panmnesia的CXL-Opt进一步将执行时间减少了1.66倍,优化的控制器实现了两位数纳秒延迟,并最小化了读/写延迟。
这种模式在另一张图中也很明显,该图显示了在GPU内核执行期间记录的IPC值。它表明,Panmnesia的CXL-Opt性能速度分别比UVM和CXL-Proto快3.22倍和1.65倍。
总体而言,CXL支持可以为AI/HPC GPU做很多事情,但性能问题仍是一个大问题。
此外,英伟达官方是否会让GPU增加对这种CXL方案的支持也是一个问题。
如果使用PCIe连接的内存来扩展GPU的方法确实能落地的话,互联网巨头们会采用Panmnesia的方案吗?毕竟这些巨头都喜欢自己搞类似的技术。
原文作者:Anton Shilov,原文地址:
https://www.tomshardware.com/pc-components/gpus/gpus-get-a-boost-from-pcie-attached-memory-that-boosts-capacity-and-delivers-double-digit-nanosecond-latency-ssds-can-also-be-used-to-expand-gpu-memory-capacity-via-panmnesias-cxl-ip
