 本文约3500字,建议阅读7分钟本文介绍本组ICLR2024时间序列预测方向的最新工作:iTransformer: Inverted Transformers Are Effective for Time Series Forecasting。
本文约3500字,建议阅读7分钟本文介绍本组ICLR2024时间序列预测方向的最新工作:iTransformer: Inverted Transformers Are Effective for Time Series Forecasting。
作者:刘雍*,胡腾戈*,张淏然*,吴海旭,王世宇,马琳涛,龙明盛
链接:
https://arxiv.org/abs/2310.06625
代码:
https://github.com/thuml/iTransformer
1.引言近年来,Transformer在自然语言以及计算机视觉领域取得了长足的发展,逐渐成为深度学习的基础模型。在时序分析领域,受益于其强大的序列建模能力与可扩展性,Transformer广泛应用于时序预测,派生出了许多模型改进。
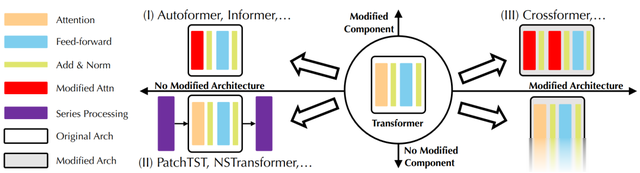
Transformer用于时序分析的结构分类
然而,受传统机器学习方法启发,近期涌现的线性预测模型,比起相对更复杂的Transformer及其变体,能够取得相当甚至更好的效果。由此,针对Transformer是否适合时序预测,引发了热烈讨论。
通过分析大量预测场景,我们认为在多变量时间序列上,Transformer的建模能力没有得到充分发挥。多变量时序数据非常广泛,每个变量代表一条独立记录的序列,可以是不同的物理量,例如气象预报中的风速,温度,气压等指标;也可以是不同的主体,例如工厂的不同设备,各个国家的汇率等。因此,变量之间一般具有不同的含义,即使相同,其测量单位以及数据分布也可能存在差异。
然而,现有模型没有充分考虑上述变量差异。基于Transformer的建模单位——词(Token),为了构建时序数据的词,以往方法将所有变量在同一时刻的时间点表示为一个词(Temporal Token),但由于其过小的感受野和变量间内生滞后期,这类词较难揭示足够丰富的语义甚至包含噪声干扰,限制了注意力机制建模词之间关系。另外,来自不同变量的时间点被映射到词表示后,原本独立的变量被杂糅为多维特征,使模型无法显式区分并捕捉变量间关联。

上:Transformer;下:iTransformer
我们提出Inverted Transformer,无需修改任何模块,倒置建模多变量时间序列。我们将变量的整条序列独立地映射为词(Variate Token)。以变量为主体,通过注意力机制自然地挖掘以词为单位的多变量关联。此外,Transformer的前馈网络和层归一化互相配合,消弭变量测量单位之间的范围差异,学习适合于时序预测的序列特征。
效果方面,iTransformer在基准数据集上实现了全面突破,并且高效部署在蚂蚁集团的服务器负载预报场景中。此外,我们对倒置框架进行了广泛的分析和泛化,为构建多变量时序基础模型提供了新思路。

六大基准数据集的预测效果
2. 相关工作2.1 Transformer系预测模型我们回顾以往Transformer预测模型,归纳为如下几种结构设计策略:
模块修改:主要为针对长序列的高效注意力模块,例如Informer,Autoformer。模块与结构修改:明确了时序依赖和变量相关建模的重要性,例如Crossformer使用两个注意力模块分别进行建模。无修改:注重时序数据的固有处理,例如Non-stationary Transformer的平稳化、PatchTST的分块(Patching),一般能带来通用的性能提升。相比之下,我们未修改任何原生模块,而是将各模块作用于相反维度,同时建模时序和变量关联,更关注对多变量时序数据的结构适配。
2.2 多变量时序数据的词构建不同于自然语言拥有天然的分词方式,基于Transformer进行时序分析,我们重新考虑词的构建方式:
Temporal Token: 以往模型的主流做法,将所有变量同一时刻的时间点表示为词,获得以时间点为单位的词序列。Patch Token:在时间维度上对序列进行分块,扩大的感受野包含局部序列变化,从而获得语义性更强的词。相比之下,我们着眼于变量的整体性,提出Variate Token,关注以变量为主体的关联建模,适合变量数较多且互相关联的多维时序数据。

时序数据的词构建方式对比
3. iTransformer3.1 模型结构iTransformer基于仅编码器(Encoder-only)结构,包括嵌入层(Embedding),映射层(Projector)和若干Transformer模块(TrmBlock),可堆叠深度来建模多变量时序数据。

iTransformer整体结构
3.2 以变量为主体的特征表示给定时间长度为 ,变量数为 的多维时间序列 ,我们使用 表示同一时刻的所有变量, 表示同一变量的整条序列。
如前所述, 相比 具有一致的语义与测量单位,不同于以往模型将 视作独立的词,我们使用嵌入层学习变量 的序列特征表示(Series Representation),独立聚合每个变量的全局特征:
其中 蕴含了对应变量在过去时间内的全部时序变化,称为Variate Token。在后续各层中,每个Variate Token之间通过自注意力机制进行信息交互;在每个Variate Token内部,层归一化统一不同变量的测量单位与特征分布,前馈网络进行全连接式特征编码。最终通过映射层将每个词Variate Token分别映射为预测结果。整个计算过程表示如下:

嵌入层和映射层均由多层感知机(MLP)实现。由于时间点之间的顺序已经隐含在神经元的排列顺序中,模型能够感知时间点的顺序关系,因此不需要额外引入位置编码(Position Embedding)。
3.3 模块分析我们重新审视了各模块在倒置维度上的职责。
(1) 层归一化:在此前Transformer中,层归一化将同一时刻的的多个变量进行归一化,使每个变量杂糅无法区分,提高了注意力建模词关联的难度。一旦收集到的数据没有按时间对齐,该操作还将引入延迟过程之间的噪声干扰。

在倒置版本中,层归一化作用于Variate Token内部,让所有变量的特征都处于相对统一的分布下,减弱测量单位的差异。这种方式还可以有效处理时间序列的非平稳问题问题。
(2) 前馈网络:基于多层感知机的万能表示定理,前馈网络作用在整条序列上,能够提取序列的内在属性,例如幅值,周期性,频率谱(傅立叶变换可视作在序列上的全连接映射),从而提高在其他的序列上的泛化性。
(3) 注意力:注意力机制建模了不同词之间的关联,通过分析注意力图的每个位置的计算公式:

其中 对应任意两个以变量为主体的的Query和Key向量,我们发现注意力图可以在一定程度上揭示变量的相关性:

在后续的Softmax加权操作中,高度相关的变量将在与其Value向量的交互中获得更大的权重,因此这种设计更自然地建模了多变量时序数据的关联,在有物理知识驱动的复杂预测场景中格外重要。
4. 实验分析iTransformer在多维时序预测基准上进行了实验,并部署在蚂蚁集团的线上服务负载预测场景,涵盖19个数据集,76种不同的预测设置。
我们对比了10种深度预测模型,包含领域代表性Transformer模型:PatchTST(2023)、Crossformer(2023)、FEDformer(2022)、Stationary(2022)、Autoformer(2021);线性预测模型:TiDE(2023)、DLinear(2023)、RLinear(2023);TCN系模型:TimesNet(2023)、SCINet(2022)。
4.1 时序预测相较以往测试基准汇报模型在不同输入长度下调优后的效果,我们使用统一的输入长度,一方面避免过度调参,另一方面契合真实预测场景。如下表所示,iTransformer在基准比较中显著超过此前领域最优效果。此前受到质疑的Transformer,只需简单倒置,就能在多变量时序预测中超越目前主流预测模型。

在蚂蚁集团提供的服务负载数据集上,由于较多变量数(>300)以及复杂变量关联,我们相较其他模型取得了大幅领先,验证了模型针对多变量时序数据建模的有效性,为模型的落地提供了基础。
 4.2 框架能力
4.2 框架能力我们将其他Transformer变体模型进行同样的倒置,证明倒置是符合建模多变量时序数据的通用框架。
(1)提升预测效果
在预测效果上,每个模型相较倒置前均取得了大幅度的提升,也证明iTransformer可以受益于高效注意力组件的相关研究。

(2)受益于变长观测
以往Transformer模型的效果不一定随着输入的历史观测的变长而提升,在使用倒置框架后,模型随着历史观测长度的增加,呈现明显的预测误差降低趋势。

(3)泛化到未知变量
通过倒置,模型在推理时可以输入不同于训练时的变量数,结果表明该框架在仅使用部分变量训练时能够取得较低的误差,证明证明倒置结构在变量特征学习上的泛化性。
 4.3 深入分析
4.3 深入分析(1)数据分析
通过可视化Traffic数据集的片段,每个变量表示一个街区的道路堵塞情况,我们发现变量间存在着显著的内生滞后关系(Sensor 1-2),一定程度解释了此前Transformer的失效原因(聚合同一时刻但在事件描述上并未对齐的变量)。

我们可视化了服务器负载预测的片段,发现模型学到的注意力图能够反映不同变量之间的相关性,增强了模型的可解释性。

(2)消融实验
使用注意力建模变量间关系,使用线性层提取变量内表征,在大部分数据集取得了最优效果,验证了倒置结构设计的合理性。

(3)特征表示分析
我们分析了CKA度量(CKA越低,代表模型浅层-深层的特征差异越大)。此前研究表明,时序预测往往偏好更高的CKA相似度。通过对倒置前后的模型分别计算CKA,得到了左图的结果,印证了倒置模型学到了更高的CKA,从而取得更好的预测效果。

右图可视化了变量相关性和注意力图,我们观察到:
在浅层注意模块,学习到的注意力图与历史序列的变量相关性更加相似。当深层注意模块,学习到的注意力图与待预测序列的变量相关性更加相似。说明注意力图体现了变量相关性,并且在浅层网络中进行了对历史观测的特征编码,深层网络逐渐解码为待预测序列。
5. 总结考虑多变量时间序列的特性,我们反思了以往Transformer模型的失效原因,提出倒置建模的视角,模块各司其职,配合完成多维时序数据两个维度的建模难题,展现出优良的性能和通用性。
回顾Transformer在其他领域的蓬勃发展,我们希望充分发挥其在时间序列领域的序列建模能力与可扩展性,使其重新回到时序分析的主流位置,为时序领域的基础模型的构建提供新思路。
欢迎感兴趣的朋友阅读论文(https://arxiv.org/pdf/2310.06625.pdf)或者访问项目页面(https://github.com/thuml/iTransformer)了解更多内容。
