两年前,朋友想知道 Boss 直聘上关于自动驾驶的岗位有哪些 ,于是,笔者写了一个简单的爬虫 crawler-boss ,将大城市相关岗位的信息收集起来。
这篇文章,笔者想分享爬虫 crawler-boss 的设计思路。
 1 基本原理 Selenium + chromedriver
1 基本原理 Selenium + chromedriver对于很多动态渲染的网页而言,想要抓取它的数据,就需要对网页的 JS 代码以及 Ajax 接口等进行分析。
而当 JS 代码混乱,难以分析,Ajax 的接口又含有很多加密参数的时候,就非常难以直接找出规律,那么上述过程会花费大量的时间和精力。

上图中, Boss 直聘接口参数比较多,笔者并不想花太多时间研究这些参数,于是笔者选择了另一种方案: Selenium + chromedriver 。
Selenium 是 web 浏览器自动化测试的工具,它可以模拟用户与所有主流浏览器之间的交互,比如点击,输入,抓取,拖拽等等。
但是 Selenium 与网络爬虫又有千丝万缕的关系,由于现在的网页大多采用是JavaScript动态渲染,使得爬虫返回的结果可能与用户实际看到的网页并不一致。我们看到的网页可能是经过Ajax加载,或者是JavaScript以及其他算法计算后生成的。
因此,我们可以使用 Selenium 直接模拟浏览器运行,我们肉眼看到的是什么样,能够抓取的数据就是什么样。
2 安装 chromedriverWebDriver 是 Selenium 的核心组件 , 负责控制浏览器进行各种操作。WebDriver 可以通过不同的驱动程序与不同的浏览器进行通信,比如 ChromeDriver、FirefoxDriver 等。
1、查看当前Google浏览器版本
打开Google浏览器,网址栏输入:chrome://settings/help

2、下载对应版本的chromedriver
对照你的版本下载,当你使用的是 Chrome 版本 115 或更高版本,就点最上面的链接:
https://chromedriver.chromium.org/downloads/

找到你对应的版本,我这里是122.0.6261.129

下载完成之后,将文件解压后,拷贝到 /usr/local/bin/ 目录 。

安装完 chromedriver 后,Java 应用中添加如下依赖:
<dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-server</artifactId> <version>3.141.59</version></dependency>然后通过如下代码,测试环境是否 OK 。
public static void main(String[] args) { WebDriver webDriver = new ChromeDriver(); webDriver.get("https://juejin.cn");}点击运行,如果打开了掘金网页说明环境配置成功。
3 流程分析1、进入搜索页面 , 搜索框中输入‘自动驾驶’


2、搜索结果若出现登录浮窗,则关闭,将页面中职位列表通过 截取出来,保存到数据库
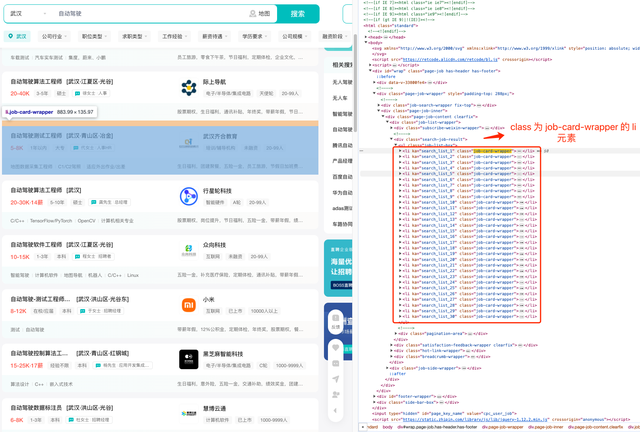

3、点击下一页


 4 写到最后
4 写到最后当我们将 Selenium 作为爬虫工具时,尽管它有很多优点,但也存在明显的缺点。
Selenium 模拟浏览器动作,除了加载需要的数据外,还会加载图片、JS、CSS等不必要的内容,导致网络资源和计算资源消耗增加,爬取速度变慢,爬取规模受限。
因此,长期大规模使用 Selenium 作为生产工具不是一个明智的选择。
然而,如果只是想在个人电脑上快速抓取少量数据,Selenium 确实是一个非常方便的工具。
最后, crawler-boss 的源码实现非常简单,假如同学们感兴趣,可以关注公众号:勇哥Java实战,回复 「爬虫」即可获取。
参考文档:
https://zhuanlan.zhihu.com/p/137710454
https://juejin.cn/post/7284318118993068051
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,你的支持会激励我输出更高质量的文章,非常感谢!
