高考,对于每一个中国家庭来说都是一场没有硝烟的战役。而在这场战役的背后,是无数家长和学生对于心仪大学的翘首以盼。朋友小李,在一家教育培训机构工作,每年高考前夕,都是他最为忙碌的时刻。这不,今年老板又交给他一个艰巨的任务——搜集高三网上近十年的中国大学排名数据,用于给学生和家长提供参考。

传统方法的痛点
面对这个任务,小李一开始想到了传统的方法:按照年份逐一打开网页,找到排名表格,然后复制粘贴到Excel表格中。但实际操作起来,他才发现这其中的不易。
高昂的复制费用:复制网络内容需要缴纳费用,每复制一次就是5.99元,10年的数据加起来就是一笔不小的开销。小李摸了摸自己本就不鼓的口袋,不禁皱起了眉头。费时费力:就算交了钱,复制粘贴、调整格式、数据分析、图像绘制……每一步都需要手动操作,不仅繁琐,而且效率低下。分析完一年的数据就要花费一个小时左右,10年的数据就是整整10个小时的连续劳作。Python自动化爬虫破局
正当小李为这个问题苦恼不已时,他想起了我会Python自动化爬虫技术。于是,他决定让我尝试用Python来解决这个问题。
通过编写一个简单的Python爬虫脚本,我实现了自动化爬取中国大学排名数据的功能。他只需运行这个脚本,几秒钟的时间,近十年的大学排名数据就被准确无误地抓取下来,并自动整理成Excel表格的格式。
import requestsfrom bs4 import BeautifulSoupimport pandas as pdulist = []# 爬取的网站的URLurl = "http://www.gaosan.com/gaokao/241219.html"response = requests.get(url)# 编码格式response.encoding = 'utf-8'# 编译数据soup = BeautifulSoup(response.text, 'html.parser')# 将数据存入定义好的ulistfor tr in soup.find('tbody').children: tds = tr('td') ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string, tds[4].string, tds[5].string])# 获取指定数量的大学并打印: # {:^10}表示将元素居中对齐,宽度为10个字符。 # \t表示制表符,用于分隔不同的列。 # chr(12288)通常用于中文文本的排版,以保持整齐的对齐。for i in range(200): u = ulist[i] print("{:^10}\t{:^20}\t{:^10}\t{:^10}\t{:^10}\t{:^10}".format( u[0], u[1], u[2], u[3], u[4], u[5], chr(12288)))# 创建一个pandas DataFrame对象df = pd.DataFrame(ulist[1:], columns=ulist[0])# 将数据保存到Excel文件中df.to_excel('学校排名.xlsx', index=False)简单几行代码,就免费爬取了21年的中国大学排名,将url改成其他年份的url就实现了其他年份的数据爬取
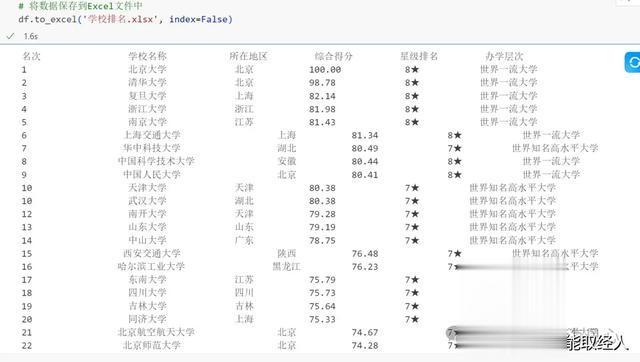
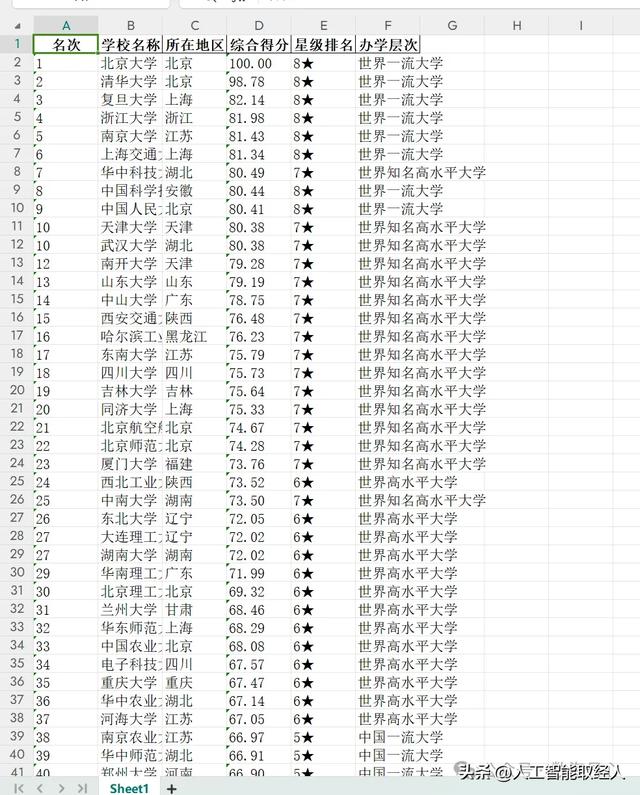
爬取的数据存储在学校排名.xlsx文件中。
Python自动化数据分析与图像绘制
有了这些数据后,再利用Python中的pandas库和pyechart库【相对于matplotlib作图更美观】进行简单的数据分析和图像绘制。他可以根据需要筛选出不同年份、不同地域、不同学科的大学排名数据,并以直观的图表形式呈现出来。这样一来,学生和家长就能更加清晰地了解各大学的实力和变化趋势。
import pandas as pdfrom pyecharts.charts import Barfrom pyecharts import options as opts# 读取Excel文件file_path = '学校排名.xlsx'df = pd.read_excel(file_path)# 统计'所在地区'列中各个地区的出现次数。department_count = df['所在地区'].value_counts()# 绘制柱状图bar = ( Bar() # 将'所在地区'列中各个地区的名称添加到图表的X轴上。 .add_xaxis(department_count.index.tolist()) # 将'所在地区'列中各个地区的出现次数添加到图表的Y轴上,并将这个数据系列命名为"数量"。 .add_yaxis("数量", department_count.values.tolist()) # 设置图表的全局选项。这里将图表的标题设置为"不同省份的大学数量"。 .set_global_opts(title_opts=opts.TitleOpts(title="不同省份的大学数量统计")))# 生成HTML文件bar.render('不同省份的大学数量.html')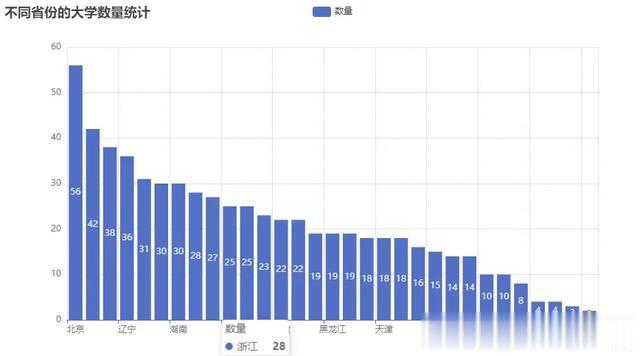 import pandas as pdfrom pyecharts.charts import Piefrom pyecharts import options as optsfile_path = '学校排名.xlsx'df = pd.read_excel(file_path)# 统计各学历人数education_count = df['办学层次'].value_counts()# 绘制饼图pie = ( Pie() # 将办学层次和对应的数量作为数据添加到饼图中。 # 其中,education_count是一个包含办学层次和对应数量的Series对象 # 通过zip函数将两个列表合并成一个元组列表,再使用list函数将其转换为列表形式。 # 最后,使用add方法将数据添加到饼图中,并设置系列名称为"数量"。 .add("数量", [list(z) for z in zip(education_count.index.tolist(), education_count.values.tolist())]) # 设置饼图的全局配置项。这里设置标题为"办学层次大学占比统计"。 .set_global_opts(title_opts=opts.TitleOpts(title="办学层次大学占比统计")) # 设置饼图的标签格式。label_opts参数用于设置标签选项,opts.LabelOpts方法用于创建一个标签选项对象,并设置标签格式为"{b}: {c}"。 # 其中{b}表示办学层次,{c}表示数量。这样设置后,饼图中每个扇区的标签将显示为"教育层次:数量"的形式。 # formatter作用: 格式化标签的参数。{b}、{c}代表占位符。 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")))# 生成HTML文件pie.render('办学层次大学占比统计.html')
import pandas as pdfrom pyecharts.charts import Piefrom pyecharts import options as optsfile_path = '学校排名.xlsx'df = pd.read_excel(file_path)# 统计各学历人数education_count = df['办学层次'].value_counts()# 绘制饼图pie = ( Pie() # 将办学层次和对应的数量作为数据添加到饼图中。 # 其中,education_count是一个包含办学层次和对应数量的Series对象 # 通过zip函数将两个列表合并成一个元组列表,再使用list函数将其转换为列表形式。 # 最后,使用add方法将数据添加到饼图中,并设置系列名称为"数量"。 .add("数量", [list(z) for z in zip(education_count.index.tolist(), education_count.values.tolist())]) # 设置饼图的全局配置项。这里设置标题为"办学层次大学占比统计"。 .set_global_opts(title_opts=opts.TitleOpts(title="办学层次大学占比统计")) # 设置饼图的标签格式。label_opts参数用于设置标签选项,opts.LabelOpts方法用于创建一个标签选项对象,并设置标签格式为"{b}: {c}"。 # 其中{b}表示办学层次,{c}表示数量。这样设置后,饼图中每个扇区的标签将显示为"教育层次:数量"的形式。 # formatter作用: 格式化标签的参数。{b}、{c}代表占位符。 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")))# 生成HTML文件pie.render('办学层次大学占比统计.html') import pandas as pdfrom pyecharts.charts import Scatterfrom pyecharts import options as opts# 读取Excel表格数据file_path = '学校排名.xlsx'df = pd.read_excel(file_path)# 提取’星级排名‘和’综合分数‘数据rank = df["星级排名"].tolist()score = df["综合得分"].tolist()# 创建散点图对象scatter = Scatter()# 添加X轴数据scatter.add_xaxis(rank)# 添加Y轴数据scatter.add_yaxis("综合得分", score)# 设置全局选项scatter.set_global_opts( # 设置标题名称 title_opts=opts.TitleOpts(title="综合得分与星级排名关系散点图"), # 设置X轴名称 xaxis_opts=opts.AxisOpts(name="星级排名"), # 设置Y轴名称以及纵坐标的大小 yaxis_opts=opts.AxisOpts(name="综合得分",min_=70, max_=100),)# 渲染图表scatter.render("综合得分与星级排名关系散点图.html")
import pandas as pdfrom pyecharts.charts import Scatterfrom pyecharts import options as opts# 读取Excel表格数据file_path = '学校排名.xlsx'df = pd.read_excel(file_path)# 提取’星级排名‘和’综合分数‘数据rank = df["星级排名"].tolist()score = df["综合得分"].tolist()# 创建散点图对象scatter = Scatter()# 添加X轴数据scatter.add_xaxis(rank)# 添加Y轴数据scatter.add_yaxis("综合得分", score)# 设置全局选项scatter.set_global_opts( # 设置标题名称 title_opts=opts.TitleOpts(title="综合得分与星级排名关系散点图"), # 设置X轴名称 xaxis_opts=opts.AxisOpts(name="星级排名"), # 设置Y轴名称以及纵坐标的大小 yaxis_opts=opts.AxisOpts(name="综合得分",min_=70, max_=100),)# 渲染图表scatter.render("综合得分与星级排名关系散点图.html")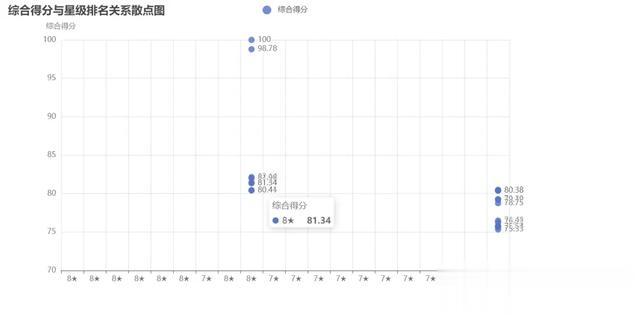
除此之外,有了数据之后可以进行任意想要探索的数据分析
结语
利用python自动化办公从数据爬取到整个分析完成只用几秒钟时间就完成了原来十几个小时的重复工作量,通过这次经历,小李深刻体会到了Python自动化爬虫技术的强大和便捷。它不仅帮助他解决了工作中的难题,还让他对Python技术有了更深入的了解和认识。同时,他也希望更多的朋友能够了解并学习这项技术,让它在更多领域发挥更大的作用。
高考在即,愿每一个考生都能找到属于自己的那片星空。而Python自动化爬虫技术,也将成为我们探索未知、实现梦想的得力助手!
关注公众号数海丹心后台留言“高考”获取完整代码
