大模型时代,Scaling Law(尺度定律)就是新的牛顿定律。大模型公司拼命追求更大参数、海量算力,因为它确实能奏效,演变成一种近乎不讲道理的“暴力美学”。从2024年起,主流大模型就没有千亿参数以下的(多模态的SORA除外),Llama3有4000亿参数、GPT4有1.8万亿参数。万亿参数大模型,对应着万卡以上规模的超大算力集群。
META、微软、Google、亚马逊是英伟达的核心大客户,2023年采购了5万-15万张H100。对应的,META自建了24576块H100组成的超万卡集群,Google则有26000块H100构成的A3超级计算机。巨头公司正在上演一场算力军备竞赛。
很显然,在AI的核心主战场,万卡集群已是标配。然而,万卡集群因其复杂的工程要求,国产化的进程比较缓慢。有能力做到万卡规模、还具备超强通用性的GPU公司,更是屈指可数,甚至可以说是空白。
但就像中国工程院院士郑纬民所说:“打造国产化的万卡集群很难,但很必要。”日前,摩尔线程就发布了一款兼具“超大规模+高通用性+生态兼容”的国产GPU万卡集群解决方案——“夸娥万卡智算集群”,标志着国产GPU正式迈入万卡时代。

摩尔线程创始人张建中
从千卡到万卡,是几十倍难度的跨越,涉及计算、存储、网络、软件,以及大模型调度等复杂的系统工程。面对万卡集群的三大技术挑战,摩尔线程是如何解决的呢?
万卡挑战1:如何组成万卡万P算力从千卡集群跨越到万卡集群,“技术挑战提高了几十倍”。在超万卡集群中,需要运用系统工程方法,通过精细化设计、软硬件全栈整合优化,克服超大规模组网互联等难题,才能实现“万卡万P”规模的极致算力。
摩尔线程夸娥万卡集群,就实现了高密度的算存硬件、高性能无阻塞的网络连接以及更高并行度的通信和计算范式。夸娥万卡集群单一集群可达万卡以上规模,浮点运算能力达到10Exa-Flops以上。
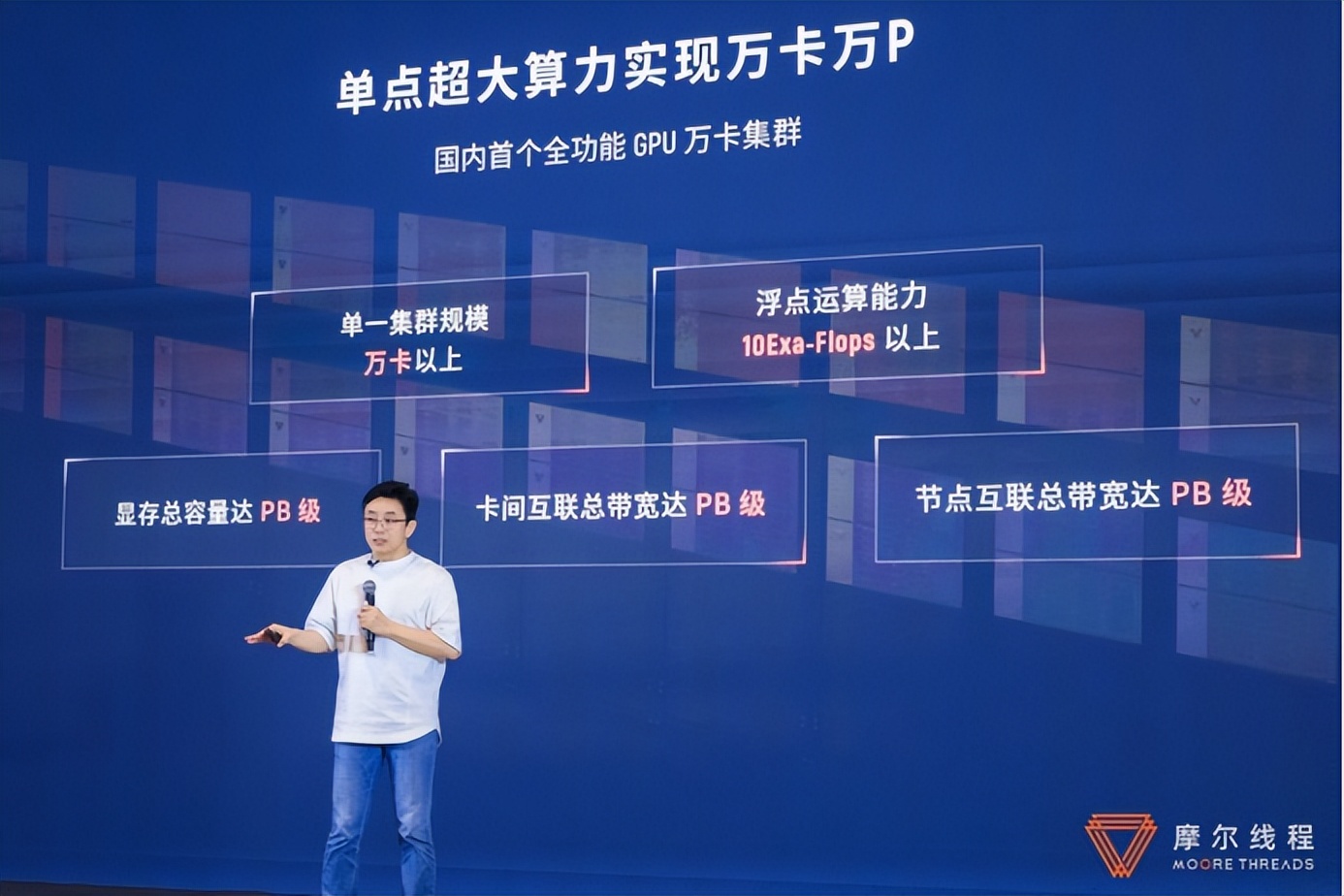
基于高带宽、大容量的显存设计,以及全新一代卡间互联能力,夸娥万卡集群可实现倍数级传输速度的提升。此外,夸娥还具备每秒PB级的超高速节点互联总带宽,可满足高性能节点通信需求、支持双环拓扑结构,实现算力、显存和带宽的系统性协同优化,全面提升集群计算性能。
万卡挑战2:有效计算效率MFU如何超过60%算力的提升与GPU数量的提升并不是成正比的,当GPU达到万卡级别,卡间和节点间的互联网络、软件和硬件的适配问题,会大大阻碍算力的提升。要提升MFU(集群有效计算效率),需要应对芯片计算性能(芯片及算子使用效率)、GPU显存的访问性能(内存和I/O访问瓶颈)、卡间互联带宽、有效的分布式并行策略等多个挑战。
摩尔线程的解决方案,是在夸娥上大幅优化了分布式并行计算。我们都知道,数据并行、张量并行、流水线并行在计算中要结合使用,其计算策略的优化就产生了至关重要的作用。摩尔线程采用了极致性能的算子库以及高性能编译器,对算子进行深度融合,实现了高效通信计算机并行。并行策略和集合通讯库也得到了极致的优化,使夸娥万卡集群支持自适应混合并行。
在显存方面,夸娥具备高效显存和显存池管理的能力,使显存能快速响应整个模型的权重、激活函数和优化器状态。此外,夸娥万卡集群还支持超长序列的训练,并对优化器和前向计算进行了量化加速。
摩尔线程从应用、分布式系统、训练框架、通讯库、固件、算子、硬件全方位提升了夸娥的能力,迈向了万卡时代。最终,夸娥在万卡集群下实现了MFU(集群有效计算效率)目标最高达60%的国际水平。
万卡挑战3:稳定性如何突破99%分析了总算力和有效计算效率,我们再来看看摩尔线程如何实现万卡集群的超高稳定性。由于大模型训练都是同步进行,分布式训练中任何一张卡的故障都会导致任务失败,因此,集群的故障率是单卡故障率的几何级数,一旦发生问题,故障定位非常复杂。业界典型硬件故障定位需1~2天,复杂应用类故障定位可能长达数十天。其次,万卡集群是个超级复杂的软硬件系统,从大类上看,故障会发生在GPU HBM ECC、驱动、网络等几个方面。详细来看,无论是服务器、集合通信组件、RDMA网络、异构架构,还是分布式训练任务,任何一环出错都会卡死整体训练进度,造成重大损失。
从万卡的复杂系统中要快速故障定位,并可诊断实现断点续训,难度不亚于万军中取上将首级。夸娥万卡集群内置软硬件全栈运行时打点,能高效采集上述的系统数据,实现万卡集群监控,并且结合软硬件分钟级故障定位、数据秒级存储和训练任务分钟级恢复,将发现和解决问题缩短到分钟级,实现了高效的断点续训。
总体来看,夸娥万卡集群的稳定性已经达到超长稳定的“月级”,平均无故障运行时间可达15天以上,最长稳定训练30天以上,周均训练有效率目标最高可达99%以上。
通用性与生态兼容:AI世界,不止于大AI趋势,不止于大。除了要做万卡,超大规模参数、多模态这些已经在发生的变化,都指向着一个趋势:AI算力还要具备通用性,才能跟上大模型快速演进的变化。摩尔线程创始人张建中给出了一个“好用”公式:“规模够大+计算通用+生态兼容=好用”。

大模型在如何变化?Transformer虽是主流但不是唯一答案,基础架构在不断的融合演进,更有Mamba、KWKV等架构作为补充。至于Transformer本身,从稠密到稀疏、从单模态到多模态、从扩散到回归,应对这些变化都需要算力的通用性。
摩尔线程的夸娥万卡集群,就具备业界鲜有的通用性,实现AI+物理仿真、AI+3D、AI+HPC等多种通用性算力,变成一个通用加速计算平台。基于全功能GPU的技术优势,摩尔线程在图形渲染、科学计算、超算上多年的积累,能支持对数字孪生、数字办公、影视制作、智能视频分析、语音处理、数字人、物理仿真、科学计算、元宇宙的全方位加速。
最后,生态兼容对国产大模型也是至关重要。因为有CUDA珠玉在前,国产GPU和大模型要在软硬件上,实现“先兼容、再独立超越”。基于高效易用的MUSA编程语言、完整兼容CUDA能力和自动化迁移工具Musify,摩尔线程可以加速新模型“Day0”级迁移,实现生态适配“Instant On”,助力客户业务快速上线。
在“AI主战场,万卡是标配”的趋势下,摩尔线程发布了夸娥万卡集群,与中国移动、中国联通等巨头公司签订了战略合作协议。进入万卡时代是一个标志,说明国产算力刚走过从“有没有”到“好不好”的阶段,国产算力不只是“可用”更可以“好用”。

靠海量的数据来取胜并不是Ai科技发展的方向,我们人脑的聪明,就不是靠数据来取胜的