来源:PaperWeekly本文约3300字,建议阅读9分钟选择性检索会是 RALM 重要的基础技术之一,还有很多重要的
来源:DeepHub IMBA本文约1500字,建议阅读5分钟本文将以高斯朴素贝叶斯分类器为例创建一个联邦学习系统。联邦
来源:DeepHub IMBA本文约2700字,建议阅读5分钟本文主要介绍了从提示工程到代理工程的转变。自ChatGPT
来源:DeepHub IMBA本文约3100字,建议阅读6分钟本文中介绍了使用PyTorch Profiler来查找运行
本文约4200字,建议阅读5分钟本文介绍了武汉理工大学团队重塑锂电池性能边界。武汉理工大学康健强团队提出了一种集成学习
本文约4100字,建议阅读8分钟本文将分享数据湖的发展近况。主要内容包括:1. 数据湖发展趋势分析2. 数据湖整体架构3
本文约2800字,建议阅读5分钟本文介绍了智谱AI开放平台的全模型矩阵。去年的这个时候,笔者特别喜欢钻研OpenAI开发
作者:黄娘球本文约1800字,建议阅读6分钟本文简述了蒙特卡罗控制方法用于优化策略。我们在《原创 | 一文读懂强化学习在
本文约2500字,建议阅读5分钟本文将介绍一种简单但有效的用于改善长度外推的定位编码方案:BiPE。在这项工作中,我们利
本文约3800字,建议阅读6分钟本文通过深度学习方法,在斯隆巡天三期释放的数据中搜寻中性碳吸收线(C Ⅰ 吸收线),揭开
来源:ScienceAI本文约3000字,建议阅读6分钟本文介绍用基础模型改变环境预测。2023 年 11 月,风暴「夏
本文约3800字,建议阅读7分钟本文将介绍最新推出的基准——MileBench。GPT-4o 的超强多模态长上下文能力备
来源:DeepHub IMBA本文约2400字,建议阅读5分钟本文综合介绍了几种高级的注意力机制,通过结合这些方法Tra
来源:统计小白浅绿色蜗牛本文约1800字,建议阅读8分钟本文主要辨析z值和假设验证中z值的解析。好书推荐:《统计学》(第
本文约2600字,建议阅读9分钟SUPRA方法通过替换softmax归一化为GroupNorm,显著提升了模型的稳定性和
来源:机器学习算法那些事本文约2400字,建议阅读5分钟本文为你图解自注意力机制(Self-Attention)。一、注
来源:ScienceAI本文约600字,建议阅读5分钟本文介绍了AI药物新发现。5 月 21 日,法国制药公司赛诺菲(S
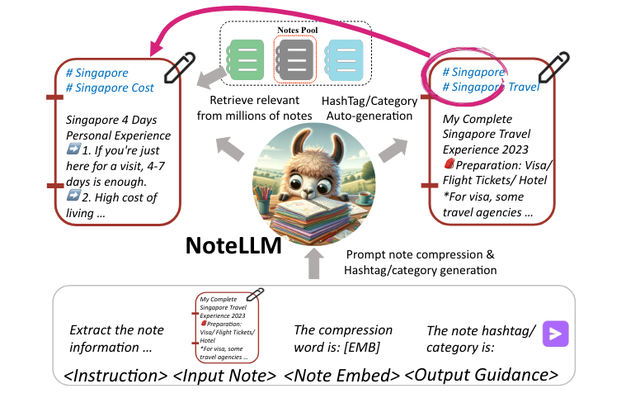
来源: NewBeeNLP本文约3000字,建议阅读6分钟本文介绍了大语言模型在小红书笔记推荐场景下的落地应用,主要是围
本文约3900字,建议阅读10分钟如何破解无监测数据和缺监测数据地区的径流和洪水预测,一直是水文领域长期面临的难题。中国
本文约2500字,建议阅读6分钟本文将详细解析这两种数据库的定义、区别与发展趋势。针对工业场景数据管理,时序数据库与实时
签名:感谢大家的关注