同事有一段 python 脚本,里面用 pandas 读取一个几十万行的 excel 文件,但是速度实在太慢了。问我有没有什么好办法提升运行速度。如果在几个月以前,就实在没有什么好办法了。毕竟在 python 生态中,读写 excel 最后的倔强就是 openpyxl 了。你就别指望它能提速了。
现在可不一样了。马上升级你的 pandas 版本,因为在 pandas 2.2 版本,开始引入一个全新的 excel 解析引擎库,它不仅仅性能吊打 openpyxl ,并且同时支持一众 excel 格式( xls , xlsx , xlsm , xlsb , xla , xlam )
这就是 calamine 库,如果你到 github 上查看,会看到其实它是一个 rust 的库:
看看 calamine 官方的性能对比:
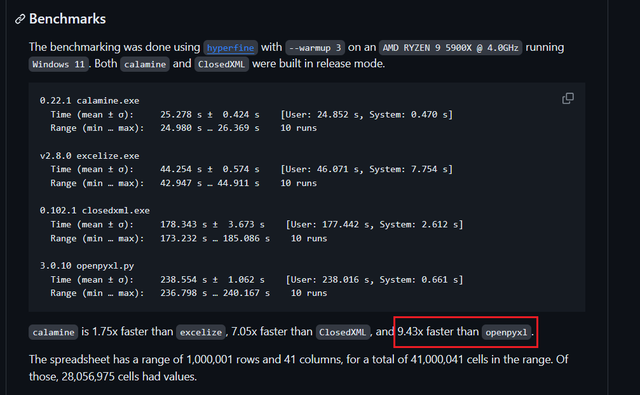
calamine 是 openpyxl 的 10 倍。
好消息是,python 也有对应的接口库:
更好的消息是,pandas 在 2.2 版本开始,悄悄支持了 calamine 。为什么说"悄悄"?因为智能提示都没有提示出来:
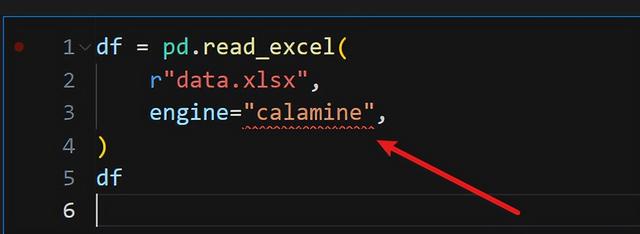
并且 to excel 还不能使用它。不过,pandas 在即将到来的 3.0 版本,正式支持 calamine。
今天,我们先亲自下场尝试一下。
加载一份 800 多万行的 feather 文件:
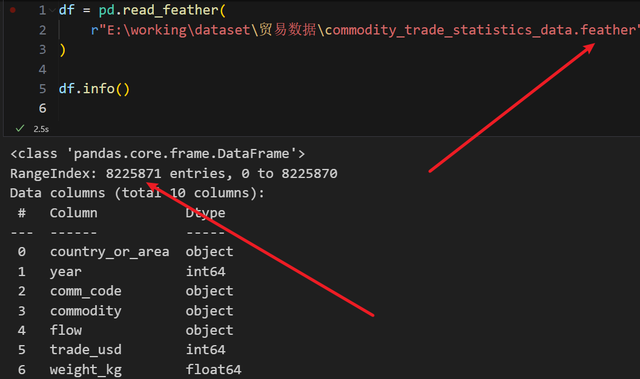
自然不可能全部塞到 excel 里面,就取前 50 万行吧:

由于 to excel 仍然使用 openpyxl ,速度可想而知,用了差不多2分钟。
现在看看使用 calamine 引擎,加载到 dataframe 要多久:
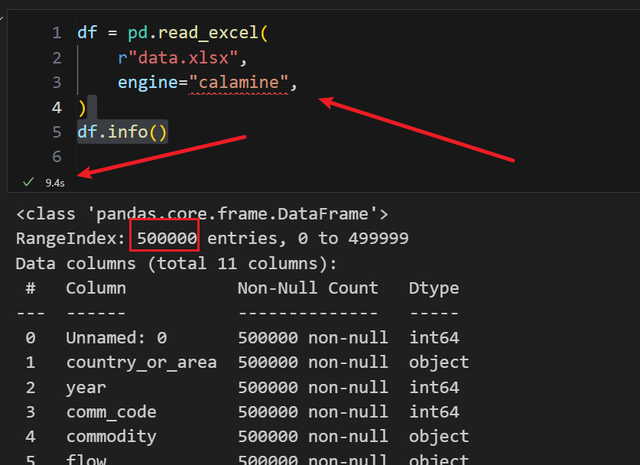
9.4 秒,还是比 feather 文件的 2.5 秒慢多了。不过有相关经验的小伙伴应该知道,加载一个50 万行的 excel,只要差不多10秒,已经是谢天谢地了。
看看 openpyxl 的速度,你能感受到什么是绝望:
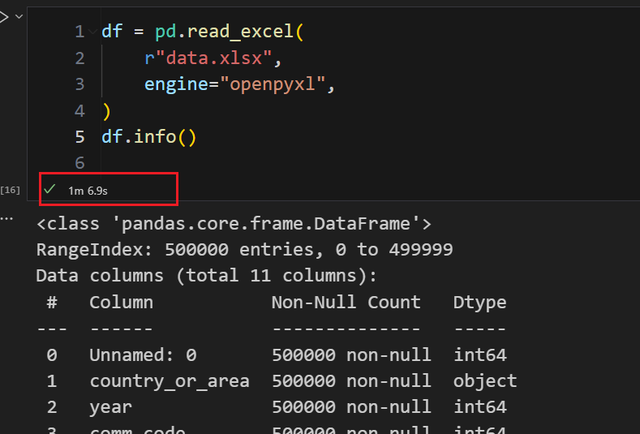
白白多出1分钟
不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。
