sql 中的 过滤、分组、聚合、排序、表连接,在 pandas 中全都有对应方法。
sql 高高手会说,case when 你没有了吧。


没有比 sql 更简洁的了,在干净数据面前,sql 是无人能敌。
以前pandas确实没有直接的 case when 方法,不过现在还真有!没错,这是 pandas 2.2 版本新增的功能。而且名字也是一绝,就叫 ”case_when“
其实 pandas 的一众大佬们也开了会,讨论了一段时间

大致的意思是,许多人都在问,pandas 中如何根据条件创建列。在我的 pandas 专栏里面也详细讲解两种最常用的方式。
比如 numpy 的 select 就可以做到:
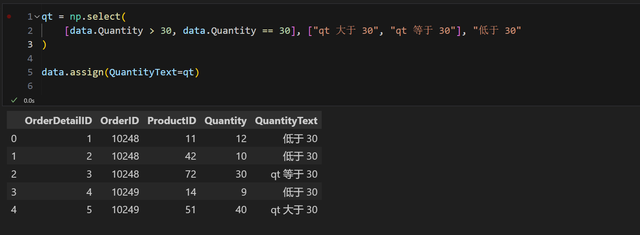
不过写法上是错开来的

不过,我们可以自定义函数,打造自己喜欢的调用方式。我们放在最后再看能否与新版本官方的 case_when pk一下。
看看官方提供的玩法。
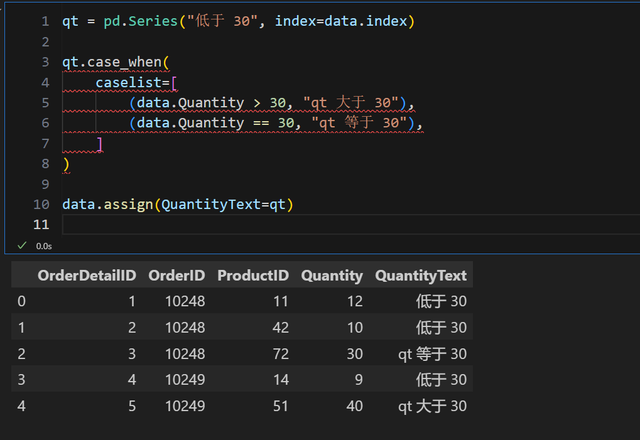 不明原因,没有智能提示
不明原因,没有智能提示很类似前面的 np.select ,只不过把结构弄成一个元组列表,每个元组对应 (条件,值)。而默认值就要在一开始定义到列里面。
值得注意的是,索引要对齐,所以行1代码要与 data 的 index 对上。
这真的好用吗?现在我们通过自定义函数,改造 np.select 吧。
第一种是直接一个函数搞定:
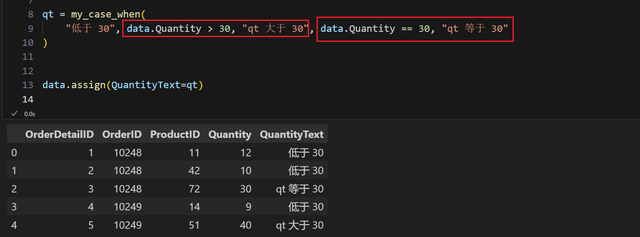
函数第一个参数是默认值,之后的是一对对出现的条件和对应值。
实现代码很简单

不过,有人喜欢”带对象“,开口闭口都是"面向对象",也来一个对象版本吧:
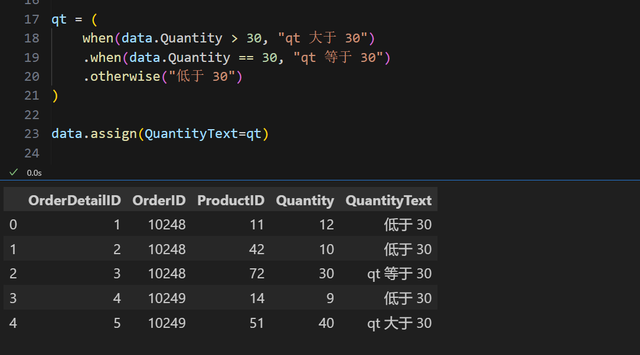
看起来比官方的舒服啊,全程智能提示。实现代码也非常简单:
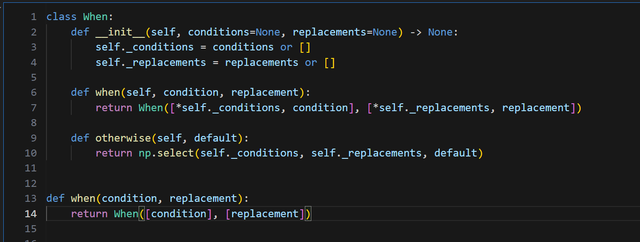
你觉得官方的实现好用吗,评论区告诉我。
不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。
转发、关注我,私信"pandas",获得本期源码和数据。
