最近,来自上海交通大学、剑桥大学和吉利汽车研究院的研究团队推出了一种全新的文本到语音系统,F5-TTS。
它不像传统的系统那样一步一步生成语音,而是能够同时处理多个步骤,这让它的速度更快。

并通过简化模型设计、提升推理效率和生成质量,解决了现有TTS系统在对齐复杂性、推理延迟和生成自然度等方面的不足。
这使得F5-TTS能够在多语言、多场景下提供自然、流畅、准确的语音生成服务。

F5-TTS支持长文本的连续语言合成,包括中文和英文。适用于长篇内容的朗读和播报。
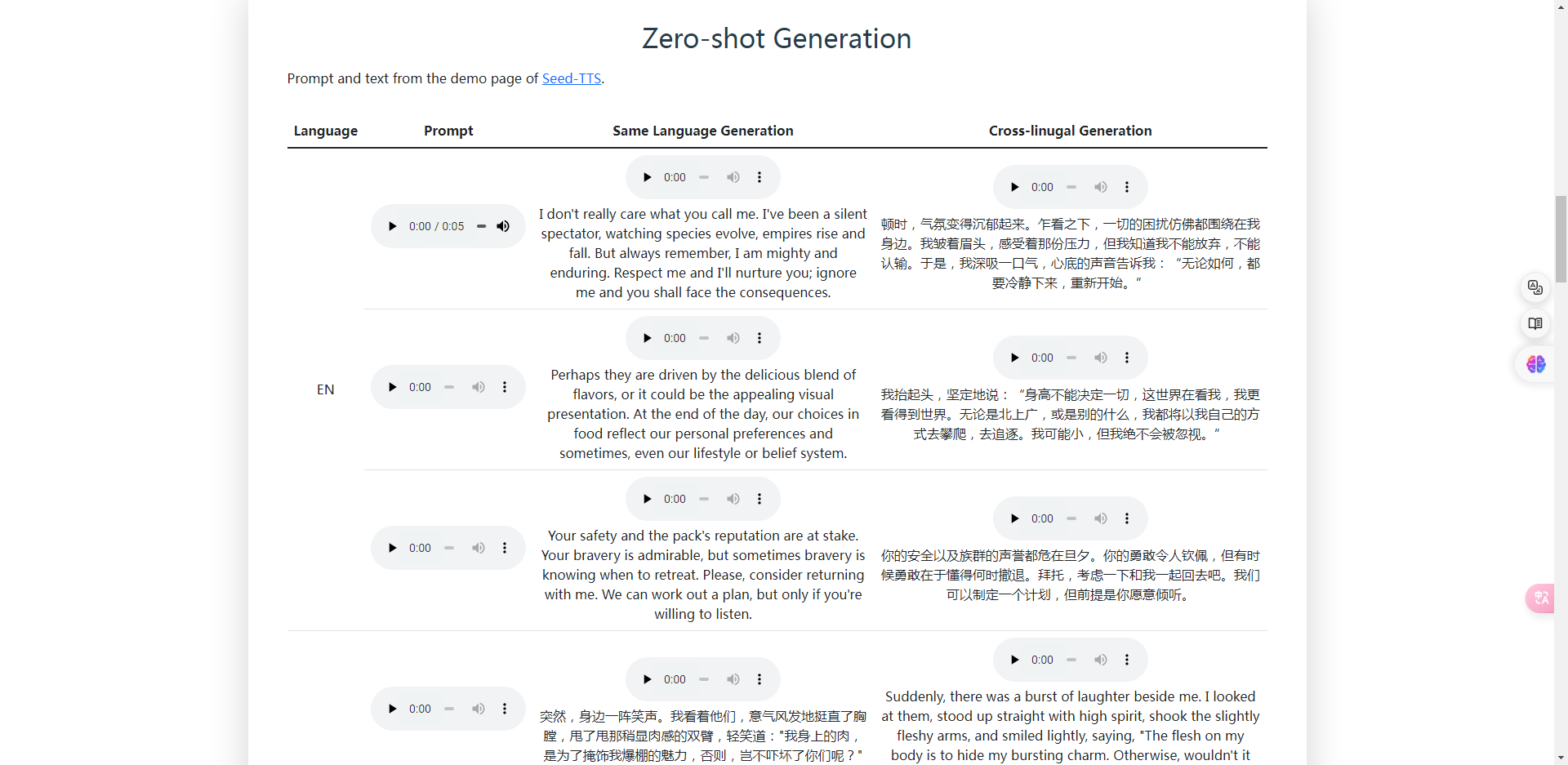
它还具备生成带有情感的语音的能力,能够根据输入文本的情感信息生成相应的语音情感表现。
如愤怒、快乐、悲伤等。这使得生成的语音更加生动、自然。
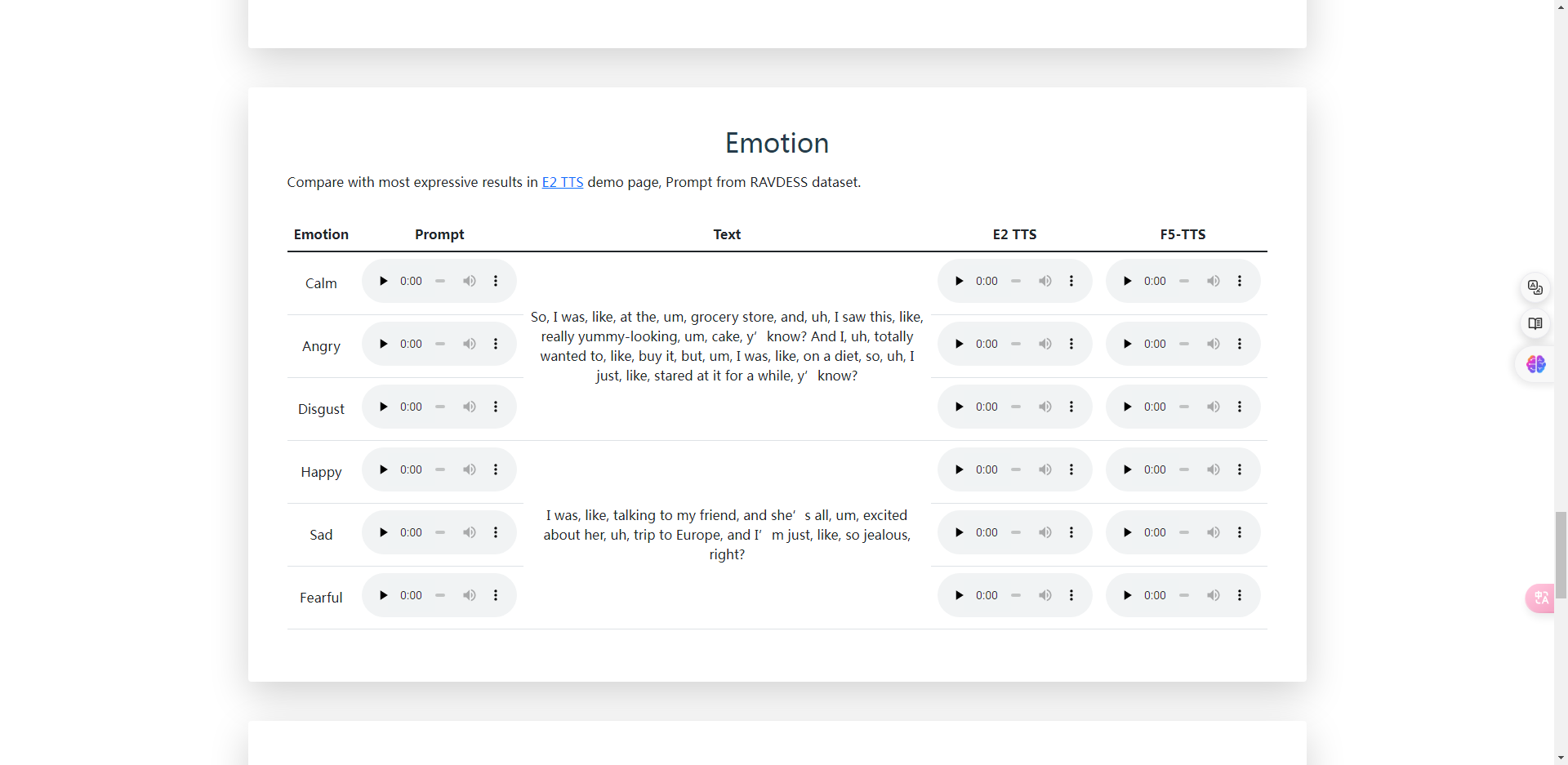
F5-TTS还支持处理和生成中英文切换的语音内容。
例如在一段语音中,它可以从英语切换到中文,然后再切换回英语,这种能力在多语言对话场景中尤为重要。

F5-TTS在处理复杂文本输入时表现出色的鲁棒性。无论输入的句子多么复杂或难以处理,F5-TTS 仍能生成高质量的语音。
这种能力使得它能够处理包括长句子、复杂语言结构甚至是口语化表达的文本输入,生成流畅的语音输出。

大家可根据自身情况,在GitHub项目界面查看并下载安装部署到本地使用,或者跟我一样,先用在线Demo体验一下。

我们登录到魔搭社区,并搜索F5-TTS点击进入到它的在线使用界面。
在此我们可以看到它提供了三种语音克隆模式供我们使用。下面我就为大家一一介绍。
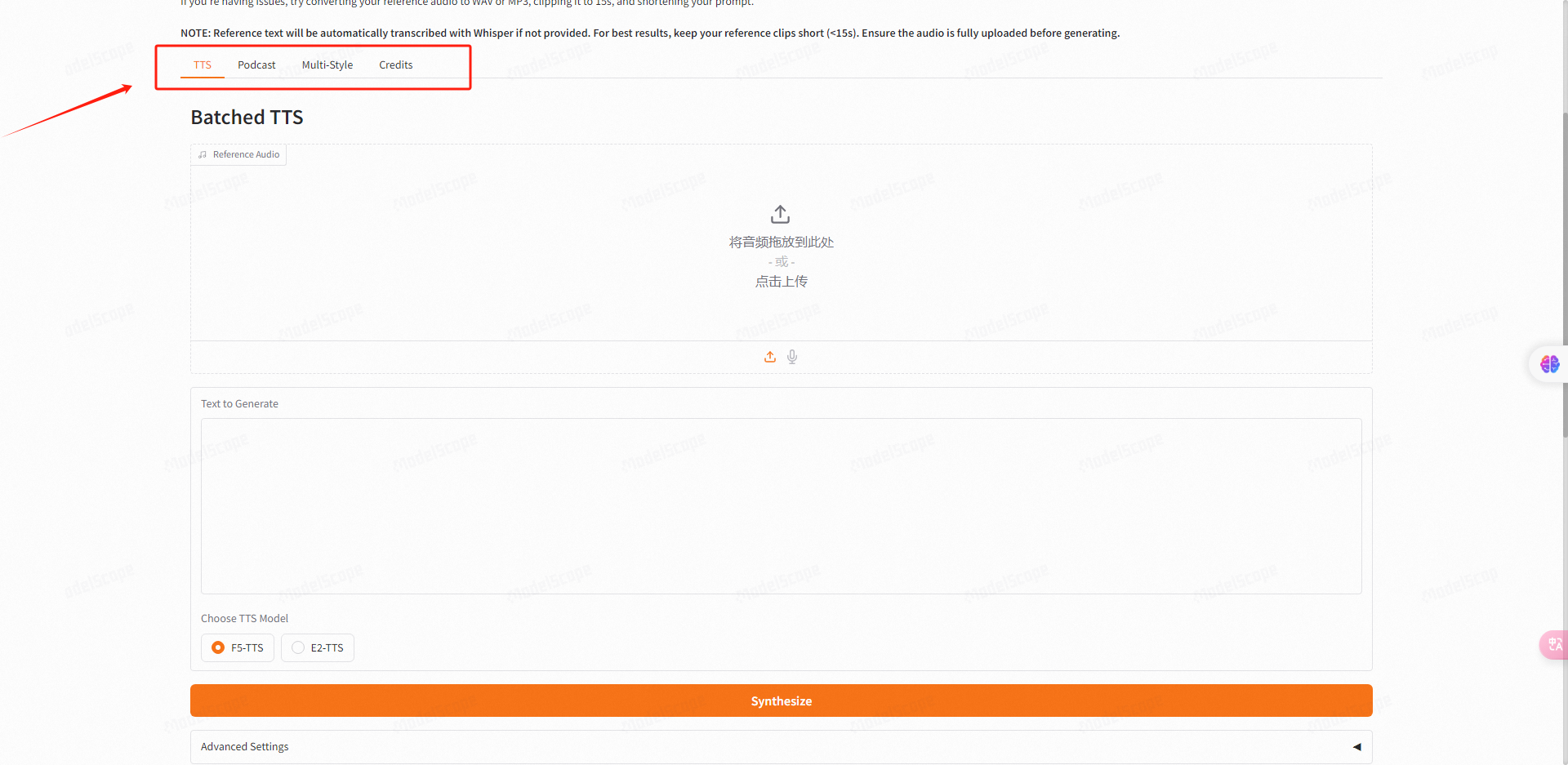
默认的TTS模式下,我们只需上传参考音频,然后在下方输入你想要生成的文本内容。
注意上传的参考音频要在15秒以内,声音要尽量清晰无杂音。

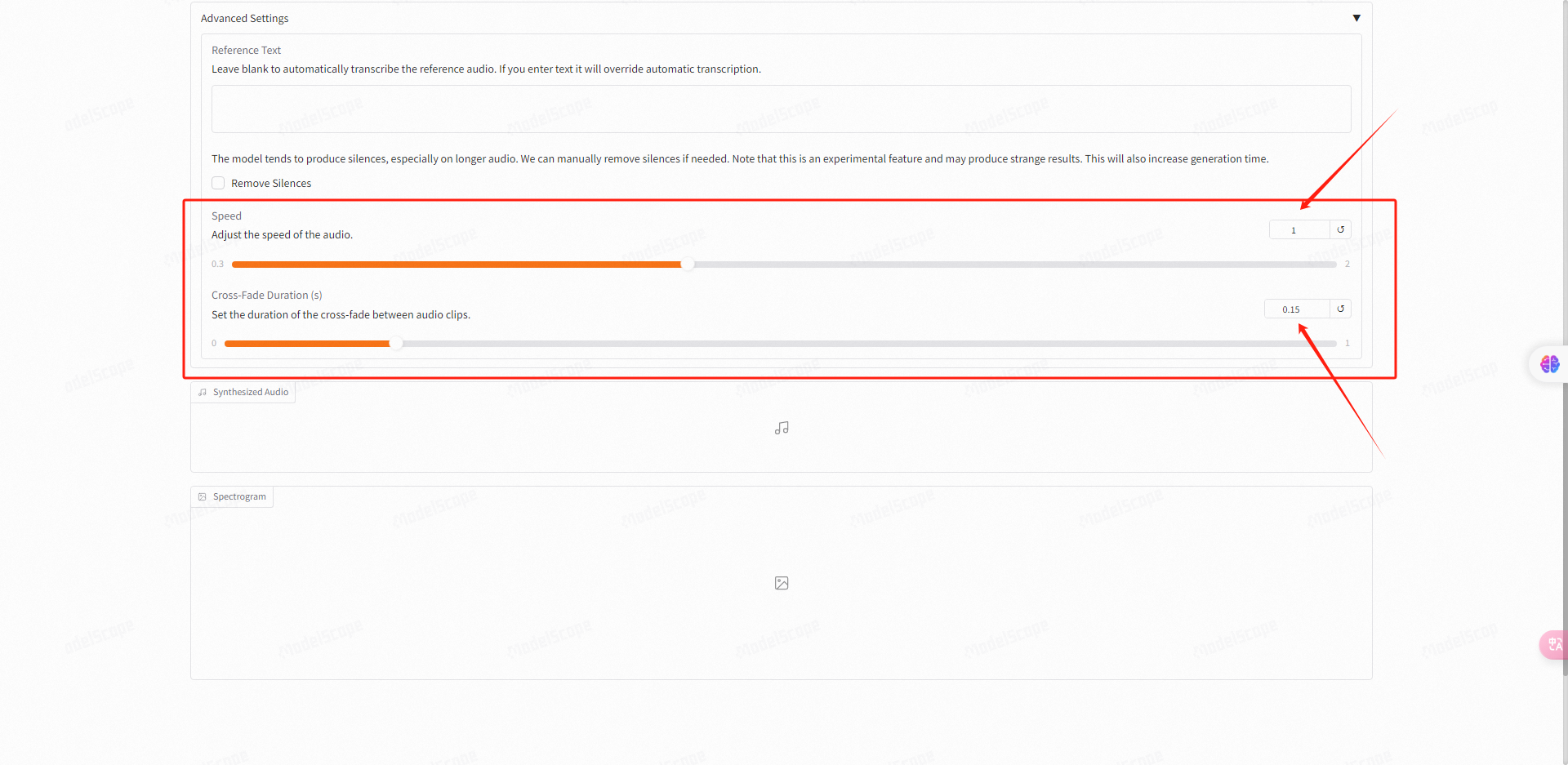
下方的高级参数设置内,此选项为如果不填写文本内容它会自动转录参考音频。
而下方的参数则是,由于转录长音频时会产生静音,我们可以勾选手动删除静音选项来移除。

最下方的两个参数分别是转录后的音频速度,以及生成后音频的交叉停顿持续时长。这两项默认就行。
而在播客模式下,我们则可以分别设置人物角色以及上传不同的参考音频,来使他们生成对话型的播客内容音频。

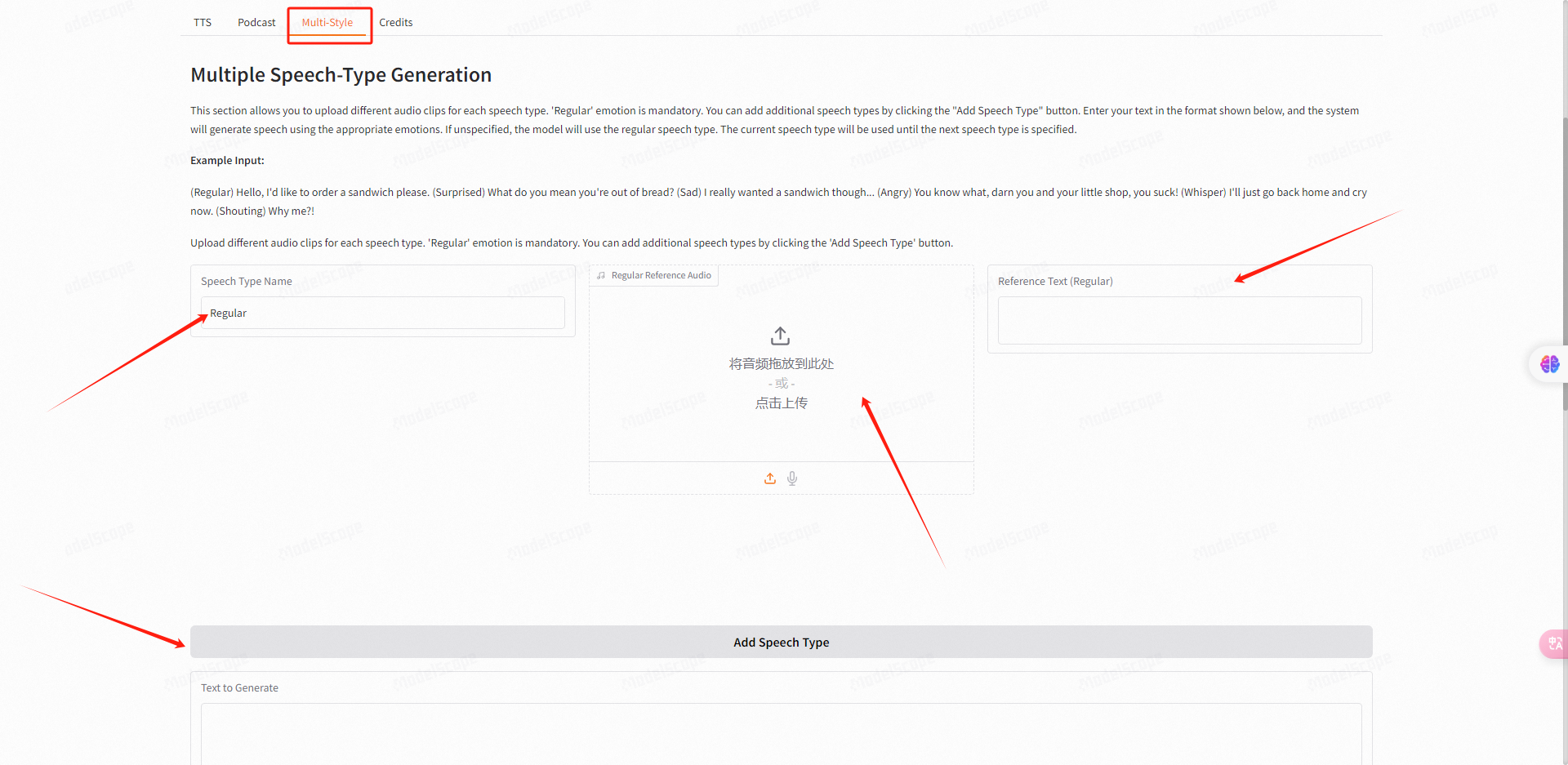
在情绪模式下,它可以为我们根据不同的情绪进行音频编辑。
只需点击下方的Add Speech Type按钮,我们就可以自己设置情绪类型,然后上传参考音频以及需要生成的文本内容。
全部设置完毕,点击语音生成按钮开始工作即可。
对这款新推出的TTS感兴趣的小伙伴可自行体验。
GitHub仓库:https://github.com/SWivid/F5-TTS
在线体验Demo: https://modelscope.cn/studios/modelscope/E2-F5-TTS
