seed-vc 是一个基于 SEED-TTS 架构的开源的声音转换模型,能够实现零样本的声音转换,
即无需任何训练,它能够根据 1~30 秒的参考语音来克隆声音。
该技术在音频质量和音色相似性方面表现出色,且具有很高的研究和应用价值。
大家可在GitHub上找到该项目,并下载到本地部署使用。
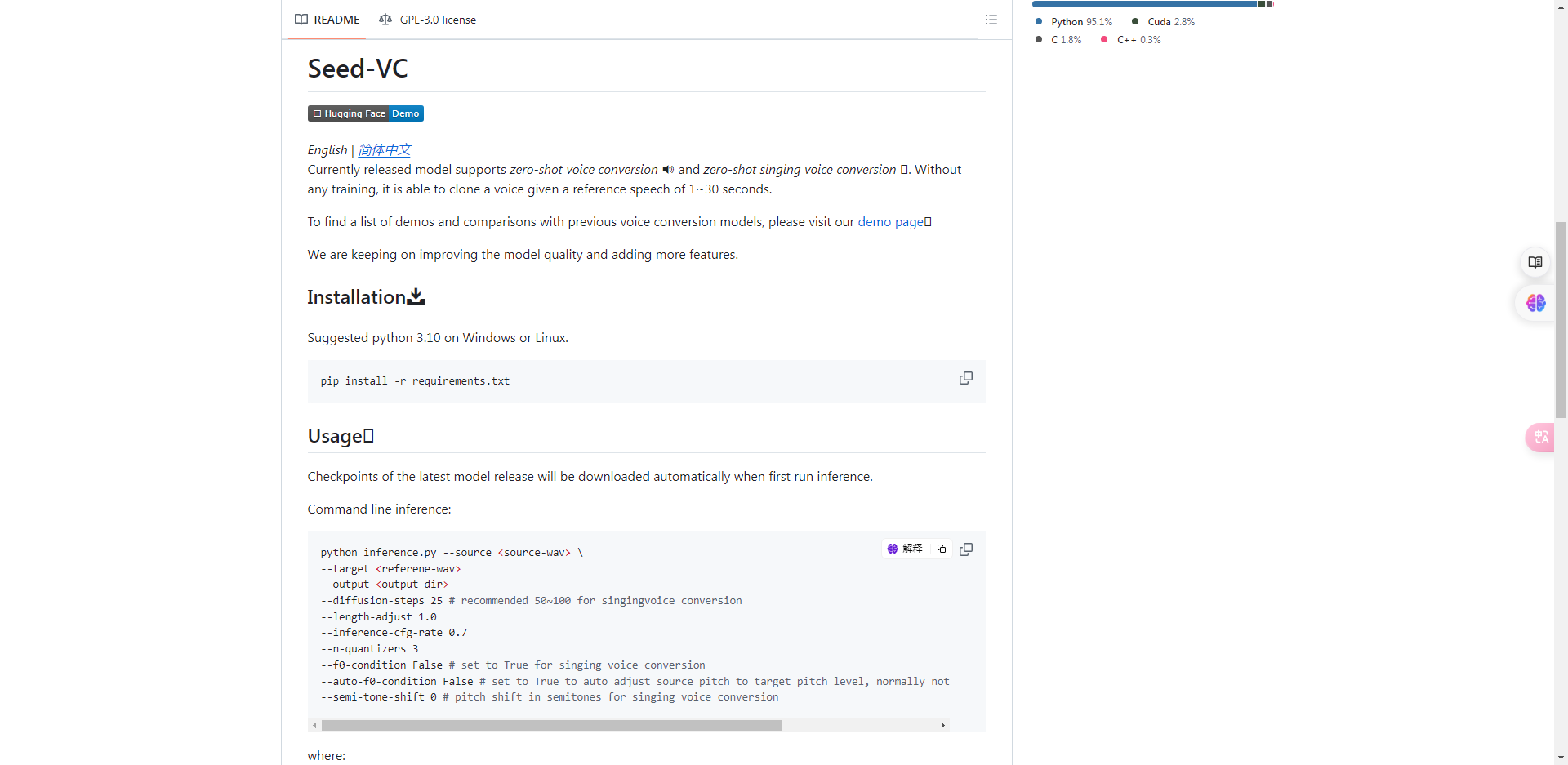
今天我们就基于Huggingface空间的演示,来实质性操作体验一下这款模型。

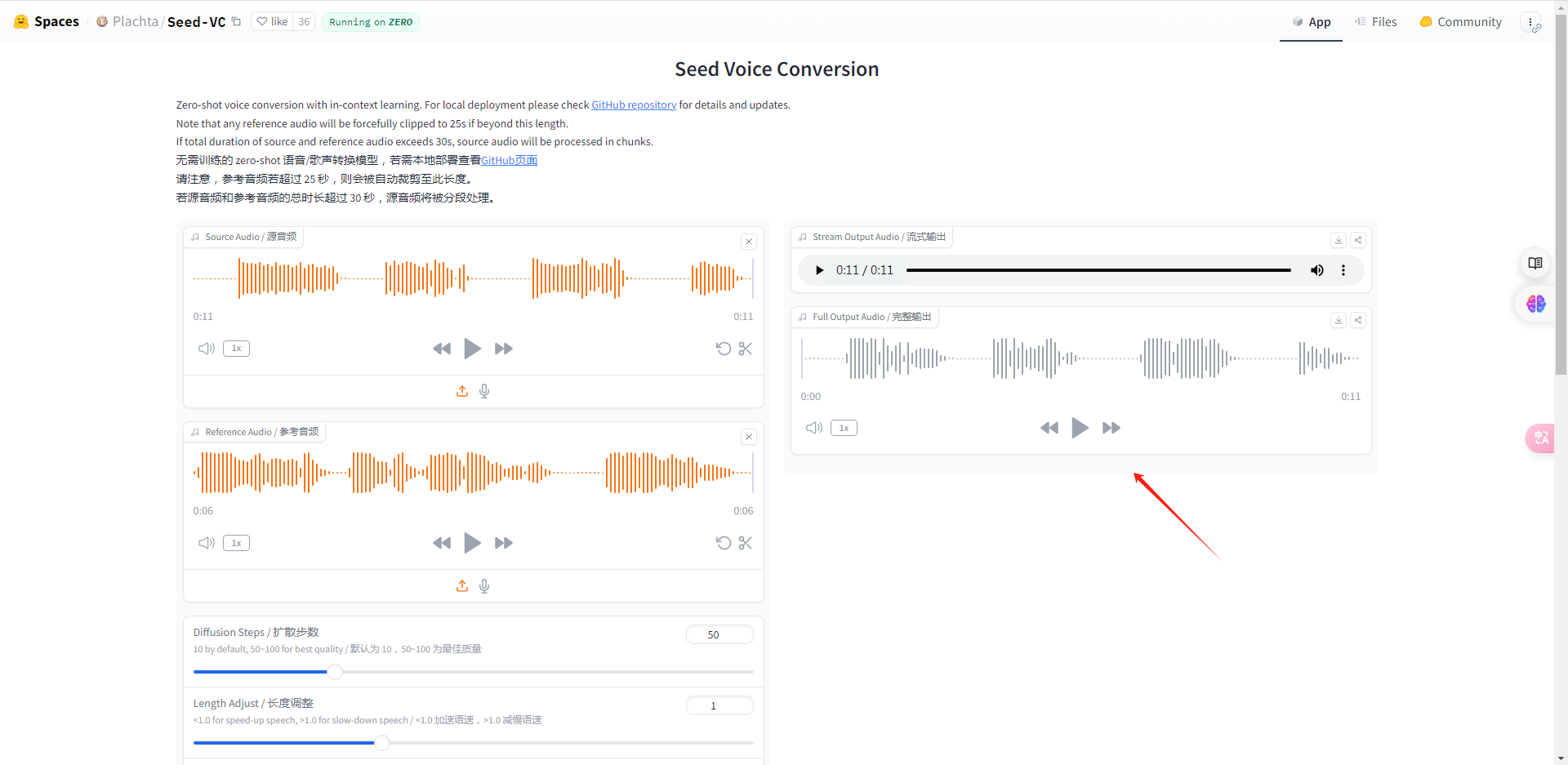
我们在左侧分别上传源音频以及参考音频,注意参考音频的时长要控制在25秒内,
如果大于25秒则会自动裁剪至此长度。
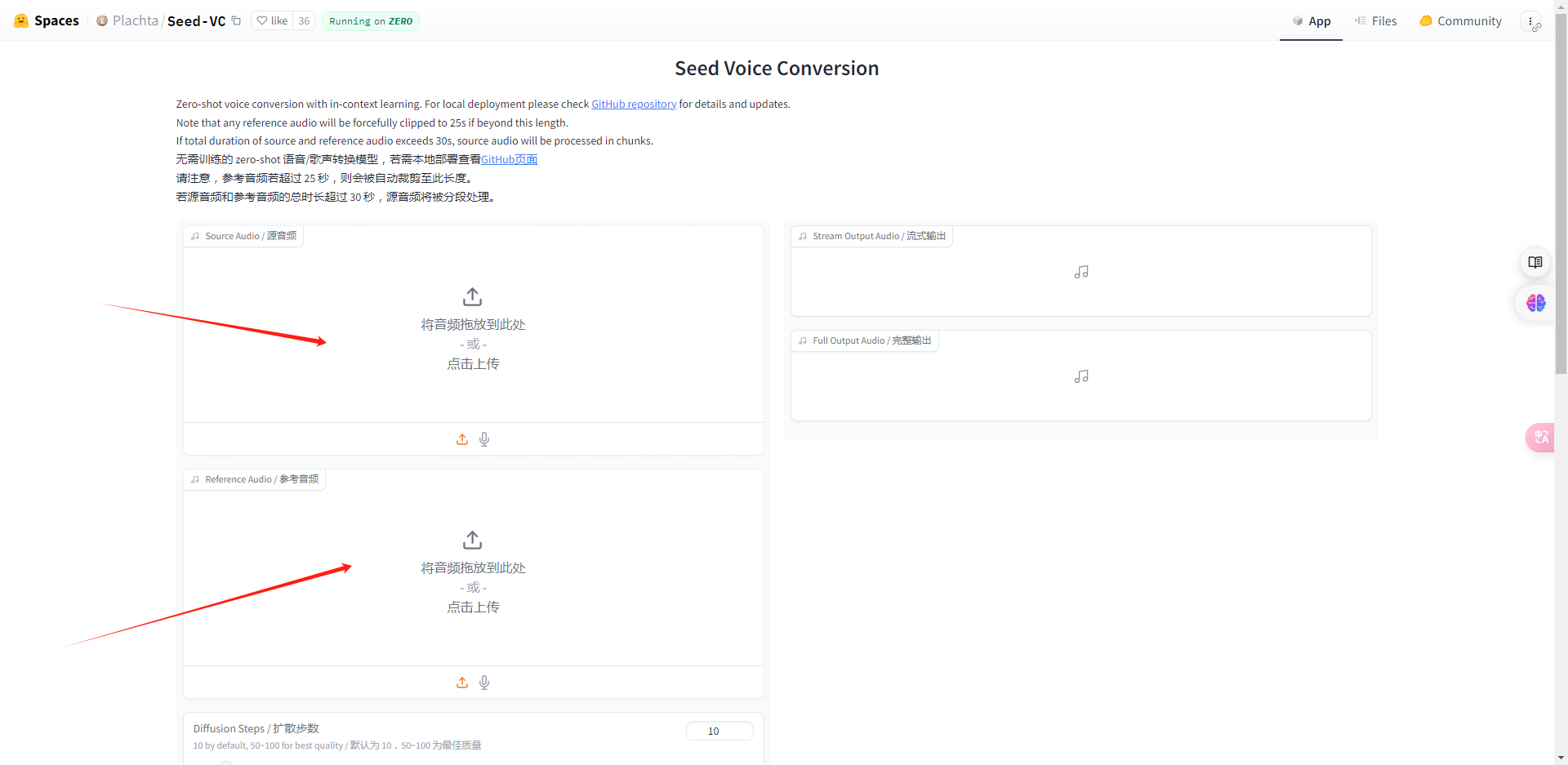
源音频就是拿它作为一个样本,下面的参考音频则是以源音频为参考对象,把它克隆到这个源音频上面。
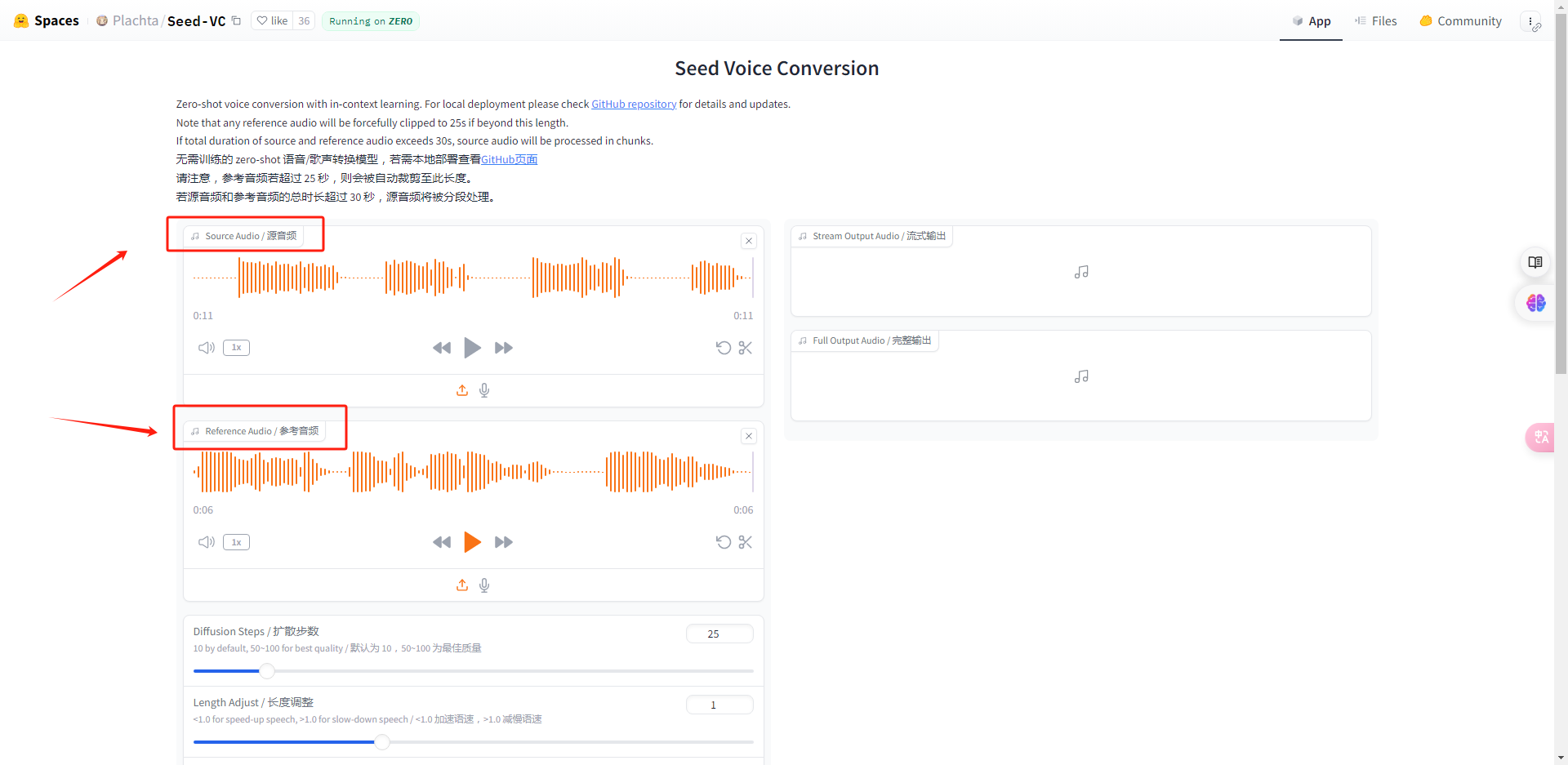
接下来我们来看它的参数设置。上方的扩散步数默认是25,但是一般把它调到50为最佳。
语速默认为1,属于正常语速不用调整。CFG默认0.7也不用动。
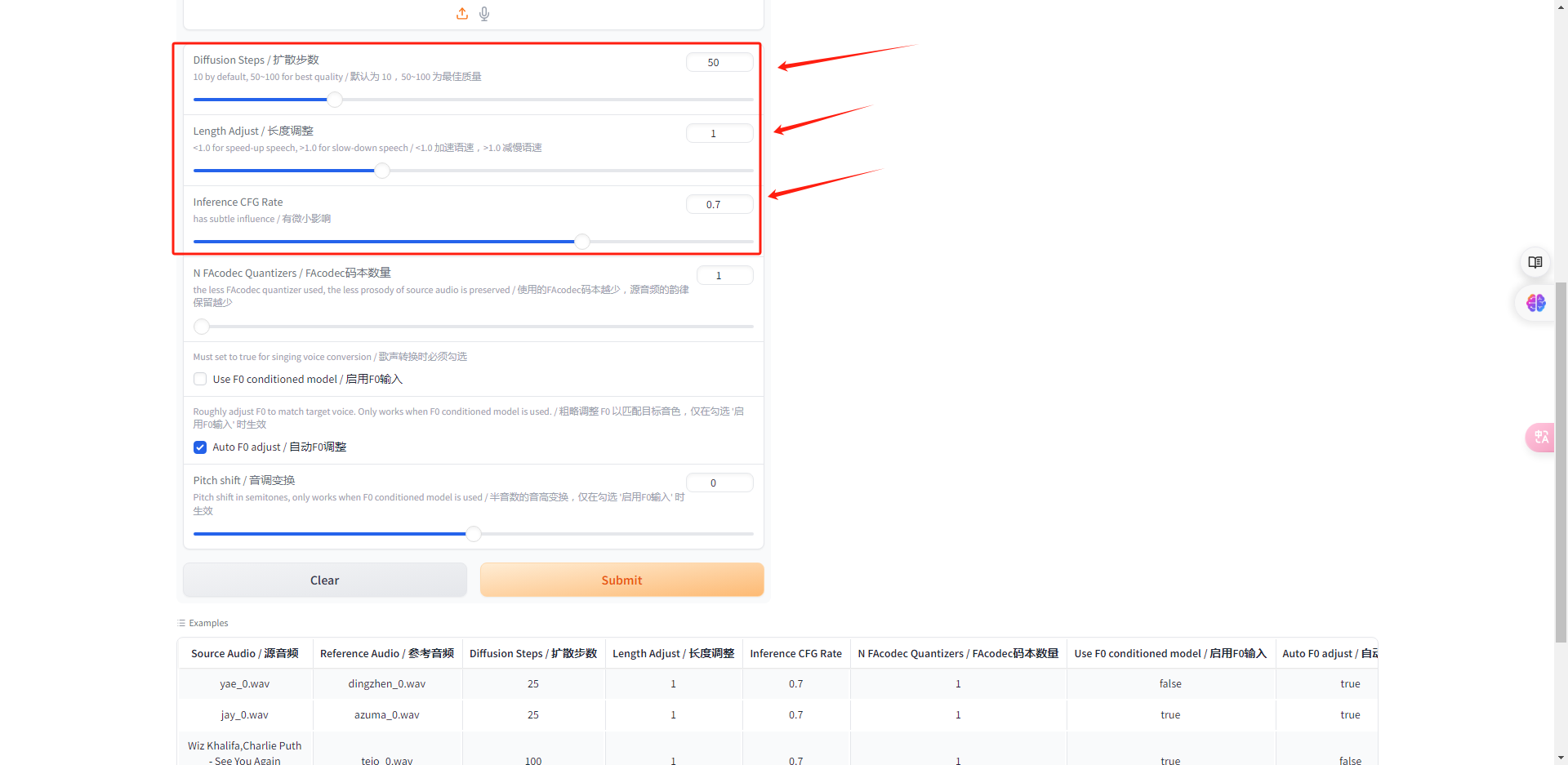
如果你是以声音为对象来克隆的话,下面的码本数量参数设置为1,其他保持不变。
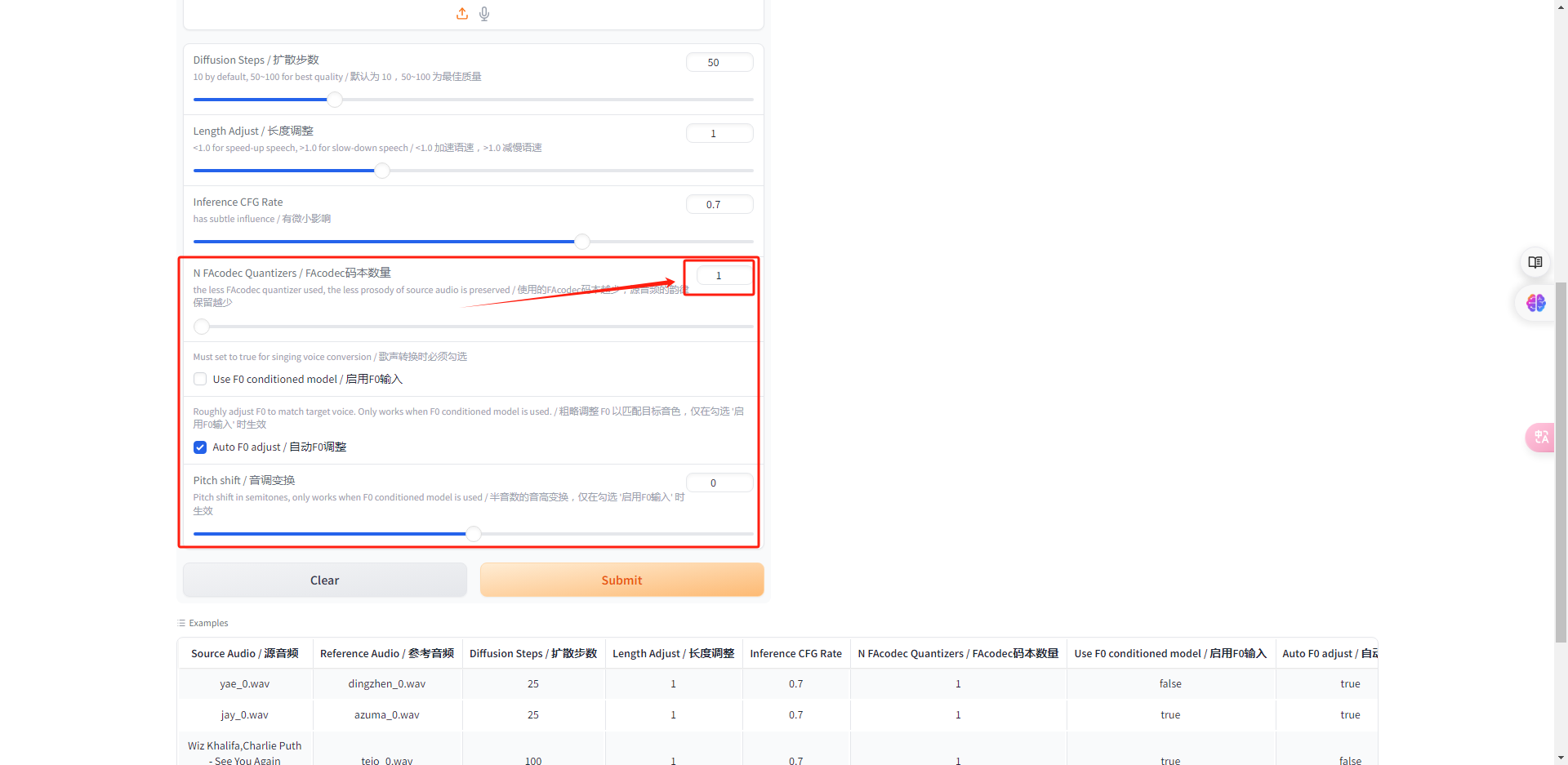
如果以歌声为参考克隆,那么就需要把码本数量参数值调整为最大,而且需要勾选F0输入选项。

该项目完全无需训练,而且对资源的占用率不是太高,4G就可以跑。转换速度也非常快。
seed-vc 适合语音技术研究者、声音合成工程师、以及对声音转换技术感兴趣的开发者。
它可以帮助他们进行声音转换技术的研究和开发,或者在语音合成、声音识别等领域进行应用。
对此模型感兴趣的小伙伴,可自行下载到本地部署或在线体验。
GitHub仓库:https://github.com/Plachtaa/seed-vc
HuggingFace在线地址: https://huggingface.co/spaces/Plachta/Seed-VC
