去年过年OpenAI整了一个大活,把AIGC方向的应用彻底跑通了,今年更是狠,直接发布了Sora,把视频从业者干得危机感都上来了。
AIGC让大家都开始意识到显卡大显存的重要性,去年甚至还有人改装2080改装22G显存版本的,但是显卡的算力依然还是跟不上,所以要想跑点好玩的,还是得上40系显卡。但是4060砍了显存,4090现在疯狂涨价,看下来反倒是一月份刚刚发布的4070 SUPER-12G是目前性价比最好的选择。
这次我搞的是索泰 GeForce RTX 4070 SUPER-12GB X-GAMING OC 欧泊白,12G的显存用起来足以应付大部分AIGC模型了,尤其是Stable Diffusion。
4070 SUPER-12G参数与性能盘点英伟达 RTX 4070 SUPER中期小改款显卡,SUPER后缀代表性能提升。
在NVIDIA的定义中,GeForce RTX SUPER系列的定位相当于版本进阶。与Ti系列作为不同数字型号之间产品线完善不同,SUPER就是冲着提升对应型号性能与性价比去的。在CES 2024上首次展出的GeForce RTX 4070 SUPER就是其中一个很好的例子,不仅带来更高的性价比,生成式AI创作上也得到进一步创新,战斗力十足。

GeForce RTX 4070 SUPER的厉害之处在于,它与GeForce RTX 4070 Ti相当接近,仅在GeForce RTX 4070 Ti的基础上减少2个TPC,即4个SM,最终拥有56组SM,7168个CUDA Core,224个第四代Tensor Core,56个第三代RT Core,224个纹理单元,80个ROP,并搭配192-bit 12GB GDDR6X。

RTX 40系列共有五种核心芯片,二级缓存容量分别是AD102 96MB、AD103 64MB、AD104 48MB、AD106/AD106 32MB。RTX 4070 SUPER的规格表,二级缓存容量变成了48MB,用上了AD102的所有缓存,增加了33%。

GeForce RTX 4070 SUPER所采用的AD104-350-A1已经非常接近于完全体的AD104,同时继承了所有AD102、AD103上的功能特性,包括对DirectX 12 Ultimate很好的支持,芯片面积达到294mm2,晶体管数量358亿个,采用台积电4N NVIDIA定制工艺,并围绕第三代RT Core,第四代Tensor Core以及大量核心所构建起来的芯片。
我们知道Ada Lovelace架构GPU中包含了若干个GPC(Graphics Processing Clusters,图形处理集群),GPC下包含若干个TPC(Texture Processing Clusters,纹理处理簇),再往下就是SM、CUDA、RT Core、Tensor Core等等。每个GPC之间包含的TPC数量相等,当GPU进行定位区分的时候再进行GPC、TPC的物理屏蔽实现。

完整的AD104包含5个GPC,每个GPC包含6组TPC,每组TPC包含2个流式多处理器(Streaming Multiprocessors,SM)。其中每个SM包含4个处理块,每个处理块包含1个64KB寄存器堆,1个L0指令缓存,1个Warp调度器,1个调度单元,4个加载/存储单元,1个特殊功能单元(Special Function Unit,SFU)用于执行超越函数指令(比如正弦、余弦、倒数、平方根等)和图形差值算法指令。
每个SM下的128个CUDA Core随处理块分成4组,每组CUDA由16个专门用于FP32的CUDA Core,16个可以在FP32和INT32之间切换的CUDA Core组成。同时每个SM还包含4个第四代Tensor Core,1个第三代RT Core,成为后续游戏实时光线追踪和DLSS 3.5性能提升的重要前提。

索泰 GeForce RTX 4070 SUPER-12GB X-GAMING OC 欧泊白的尺寸是303×121×61mm,三槽厚度,三风扇散热+热管散热,风扇支持智能启停,温度过低的时候就停转保证静音性。

标准的一个HDMI、三个DisplayPort接口。

16Pin供电接口。
所以大家要注意,ATX3.0的接口,老一点的电源是不支持的,比如我的电源是骨伽的GEX1000,1000W的电源供电肯定是够的,但是接口要买转接的。
本来40系采用ATX3.0接口的显卡一般都是附赠转接线的,但是如果你跟我一样有个性化装机需求,那你可以直接买一个转接线。
Stable Diffusion配置教程参数部分的盘点其实很虚,要落到实处,还是得上专业的软件。现在对大显存显卡需求比较旺盛的方面就是Stable Diffusion本地生成图这样的AIGC方向了,尤其是那些需要自己在家跑图的人,对高性价比支持AIGC的N卡需求量更是大。
stable diffusion的最低配置要求是NVIDIA独显4G的显存,内存至少要有8G,硬盘空间至少要有20G,建议的配置是NVIDIA独显8G的显存,内存至少要有12G,硬盘空间至少要有40G。
此处我解释一下为什么AIGC只支持N卡,首先AI的起源是需要CUDA加速的,NVIDIA在这方面布局了20年,所以学术界基本都是顺着NVIDIA提供的加速环境开发的AI模型,AMD和Intel的A系列显卡目前还没有大规模的AI开发环境,所以你要想跑市面上常用的AIGC模型的话,都只能选择N卡。
关于Stable Diffusion我整理了一下思维导图:
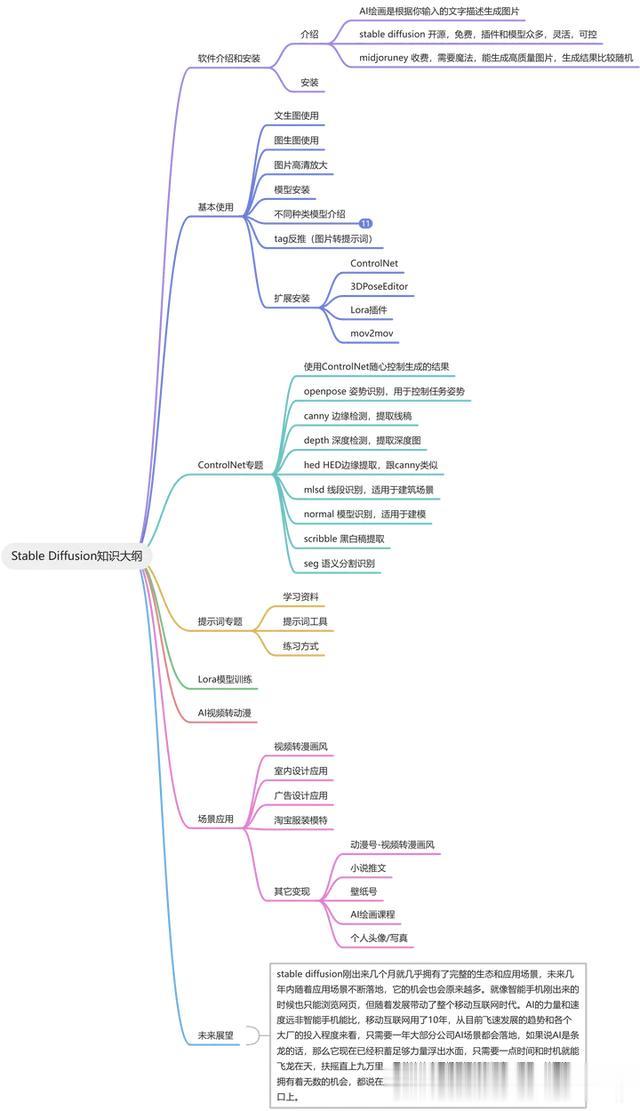
目前主流的跑图AI模型就是Stable Diffusion和Midjourney,但是Stable Diffusion是开源的模型,免费,支持本地化部署,Midjourney是在线模型,一方面网络受限制,另一方面数据放云上也受限制。
所以出于我的个人定制化和模型训练需求,我还是选了Stable Diffusion。
现在的Stable Diffusion几乎不需要用户从头去布置代码环境,再用spyder去编译了,已经有一键启动包的存在。
下载启动包之后直接双击“启动器运行依赖-dotnet-6.0.11.exe”来安装运行环境。

装完运行环境之后再解压压缩包”sd-webui-aki-v4.zip“

解压完成后进入文件夹,点击”A启动器.exe“就能直接打开启动器了。

打开启动器之后的界面就是这样的:

如果你想用更新版本的AI模型的话,可以直接去版本管理里面点一下一键更新。

扩展版的升级也是,直接去”版本管理“---”扩展“---”一键更新“里面点一下就能直接升级。

启动stable diffusion
点右下角的一键启动,它就会自动打开控制台,并且在浏览器页面自动打开stable diffusion页面。

启动成功之后的页面是这样的:

如果你的页面没有成功打开,那么你可以直接复制cmd控制台里面的地址直接到浏览器打开。

装完stable diffusion之后你还需要根据自己的需求去下载调整模型,这样才能跑出来符合你需求的图。

目前stable diffusion的模型主要的两个网站就是C站或者liblibAI,这里面已经有人跑完了大部分的模型,你直接下载下来调用就行。

比如我选的shiranui in Onmyoji的模型,直接点下载就行。

根据模型详情页面它是归属于Lora模型还是归属于别的什么模型的类目,把模型放到本地对应的目录里面去。
当然,这个一键快速启动器也是支持快捷打开模型文件夹的。
简单介绍一下不同的模型:Checkpoint,lora,VAE,Embedding,Hypernetwork。

Checkpoint是大模型的底模型,包含了很多场景素材,所以体积一般都会在2G到7G之间,别的模型都是在它的基础上做的一定的调参。

lora是微调的模型,主要用来定制人物,这个模型比较轻巧,并且训练比较高效。常见的模型大小是100MB。

VAE主要是用来美化图片色彩的模型,很多主模型都已经自带了。

Embedding主要是用来调教文本理解能力的,能让你的主模型识别某个指定的角色。所以它的大小也就几十KB。

Hypernetwork模型是最特殊的一个模型,主要用来定制画风风格,通过你自己的定制来产出特定的画风。
Stable Diffusion使用教程Stable Diffusion的使用主要分两类:一类是利用文字生成图片,另一类是利用图片生成图片。
文字生成图片就是我们常见的prompt提示词来生成图。
文字生成图片
文字生成图的教程比较简单,但是prompt也有自己的一套模式:
提示词就输入你想要画的东西,反向提示词你就输入你不想画的东西,提示框内只能输入英文,所有的符号都需要用英文半角,词语之间用半角逗号隔开。
一般来说,提示词里面越靠前的词汇权重会越高,比如car,1girl输出的就是一辆车旁边站着一个女孩子,而1girl,car输出的就是女孩的肖像,背景是半辆车。
Stable Diffusion的文本编码器会对一切文本都产生反应,不同词的反应敏感度也不一样,对于同一个含义的近义词也有不同的敏感度,但是并没有成型的规则,你需要自己反复去调整输出词汇排列才能大概输出你想要的图。
更详细的prompt调整我就不赘述了,大家自己玩的时候慢慢调整就行。
图片生成图片
Stable Diffusion用图片生成图片的功能很少有人用,但是还是有它一定的作用的。
AI 绘画的随机性导致我们使用大段的提示词来精确描述我们想要的画面内容,但毕竟文字能承载的信息量有限,即使我们写了一大段咒语,模型也未必能准确理解,不排除有时候还会出现前后语义冲突的情况。其实这个过程就像甲方给我们明确设计方向,除了重复沟通想要的画面内容外,有没有什么比口述更高效的沟通方式呢?这个时候,有经验的甲方会先去找几张目标风格的竞品图,让我们直接按照参考图的感觉走。

当然,如果仅仅是喂图功能,Stable Diffusion 的图生图板块并不值得我们单独花一篇文章来讲解,它的真正价值在于提供了丰富的操作工具将图像可控性提升到了新的层次。
我们先来回顾下平时使用文生图进行 AI 绘画的过程:编写提示词进行绘图,然后根据出图结果再不断优化提示词和各类参数进行抽奖,最终得到一张比较满意的图片。而图生图则是直接根据现有图片进行优化调整,因此图生图的操作过程可以简单理解成省去了前期文生图的抽奖过程,直接在现有图像约束的基础上进行的二次重绘。

在 Stable Diffusion 中,我们可以通过蒙版和局部重绘等功能来控制只对图像特定部分的区域进行重绘,并设置各类参数来控制重绘的效果。此外通过选择不同的绘图模型和调整图像尺寸,我们也能甚至还能实现画风转换、图像无损放大等更多玩法。相较于其他 AI 绘画工具,Stable Diffusion 中的图生图并非单纯的喂参考图,而是可以在现有图片的基础上通过人工干预来实现更加稳定可控的图像重绘。

①重绘幅度
重绘幅度可以说是图生图中最重要的参数,它的功能有点类似 Midjourney 中的 iw 参数。前面介绍图生图的原理是在原图基础上绘制一张新的图片,而重绘幅度就是用来控制在原图基础上重绘的发散性程度,数值越高,说明模型重绘过程中更加自由,绘制结果和原参考图的差异性越大,生成的图像也就更倾向于模型自身的绘图风格。
②重绘尺寸
故名思义,该参数用于设置重绘后的图像尺寸,可以分为直接设置图像宽高和设置图像缩放倍数 2 种调节方式。默认情况下重绘尺寸会自动带入当前参考图的宽高数值,而当我们拖动尺寸滑块时,可以直观的在参考图上预览重绘后的图像范围。
③缩放模式
很多时候我们的参考图和重绘后的图片尺寸并不一致,而缩放模式就是用来选择采用何种变形方式来处理图像。这里虽然提供了 4 个按钮,但是可以分为 2 类场景来使用。一种是图像长宽比发生变化时使用,这里提供了 3 种我们常见的处理方式:拉伸、裁剪、填充(由于汉译插件不同,在名称上存在一定差异)。另一种是图像长宽比例不变时使用,多数情况下用于图像等比放大。
换句话说,如果重绘后的图像尺寸和原图完全一样,这几种缩放模式使用起来并没有区别。

图生图和高清修复
如果有仔细观察的小伙伴应该已经发现了,图生图中并没有提供文生图中的高清修复选项,这是因为高清修复的本质就是进行了一次额外图生图操作,同样是先生成小图再进行放大,所以在图生图中想实现高清修复,只需将图像尺寸调大进行重绘即可,此外高清修复这一特性在图生图中有更多使用场景。
不知道大家平时是否发现过这样的现象,当人物在画面中占比越小,出图结果中出现脸部崩坏的情况就越常见,而当对人物脸部特写时很少出现崩坏情况。这是因为 Stable Diffusion 模型在逆向扩散的过程中对大区域的图像去噪处理会更加清晰,因此更擅长绘制画面中占比大的事物,通过利用这一点我们可以将图像中不清晰的小图截取出来进行放大重绘,然后再放回原图位置,即可有效修复局部变形的情况。
显卡性能分析
手里的4070 SUPER-12G主要还是拿来跑Stable Diffusion,所以我对比了一下40系不同的显卡跑Stable Diffusion的性能差异。
12G显存的4070 SUPER-12G真的是太优秀啦!跑Stable Diffusion的时候它的性能居然跟4070Ti相差无几,考虑到4070 SUPER-12G的售价比4070Ti便宜了不少,那我觉得这个卡的性价比真的香爆了。
看了看各个卡的性能和售价,我不得不感慨,老黄的刀法着实是相当精准的呢。

3DMARK Time Spy这个基础测试结果,4070 SUPER-12G跟各个显卡的性能差异排序跟Blender的测试结果一模一样,都是价格决定了性能。
3DMARK Time Spy Extreme的测试结果跟Time Spy的测试结果一模一样。

光线追踪(DXR)是微软主导开发的一种光线计算特效,与之前的特效相比,最大的区别在于大量引入实时追踪计算,让单一光源尽可能真实的去还原其效果。
最早发布实用化是源自NV的20系列RTX显卡,而2019年5月,图灵架构的GTX 16系列和上一代的10系列显卡也通过驱动更新支持。
到了30系和40系的显卡之后,基本上全系显卡都在支持光追了。
3D Mark DXR光追性能测试结果排序也是跟Time Spy的结果排序一样。
烤机功耗里面,4070 SUPER-12G的平均功耗大概是200W,如果你上14代以后的CPU的话,那么其实电源部分还是要选一个750W以上的电源的。
结语GeForce RTX 4070 SUPER距离GeForce RTX 4070 Ti基准测试相差性能只有4%到8%之间,同时GeForce RTX 4070 SUPER比GeForce RTX 4070快了15%到23%,GeForce RTX 4070 SUPER也比GeForce RTX 3070 Ti快了26%到40%。这意味着GeForce RTX 4070 SUPER实际性能表现高于RTX 3090,同时功耗只需要220W,效率非常高。
对于我这样需要跑大量AI工具的人来说,这个索泰 GeForce RTX 4070 SUPER-12GB X-GAMING OC 欧泊白的确是一个比较不错的选择。
可以这么说,GeForce RTX 4070 SUPER展示了SUPER系列所达到的性价比高度。特别是在NVIDIA软件与驱动不断升级和加持下,通过DLSS 3.5让游戏获得更好的画质和流畅体验,或者搭配TensorRT高质量的加速Stable Diffusion SDXL,再或者光线重构给D5渲染器带来实际使用时质的提升,这都是GeForce RTX 30系列以前GPU所无法比拟的。
