一切要从小伙子在python学习网站上的一道练习题说起。题目如下:

简单说,就是打印一个文件夹下,所有文件名字,包括所有子文件夹中的文件。如果只是用 python 提供的内置模块,是非常容易。但是这题却限制了,不允许使用内置模块。
小伙子心想,这明显是进阶题目呀。虽然网站提供了提示功能,但小伙子还是打算自己尝试一下。
正常思路:
 行3:遍历获取到的路径行4:每个路径判断一下是否为文件夹,如果是文件,就打印行9:但是,如果是文件夹,再次调用题目提供的函数,再次遍历?
行3:遍历获取到的路径行4:每个路径判断一下是否为文件夹,如果是文件,就打印行9:但是,如果是文件夹,再次调用题目提供的函数,再次遍历?显然不行呀,每多一层子文件夹,就要写多一次 for 循环。但我无法确定到底有多少层子文件夹。
无奈之下,只能使用"提示"功能,得到的提示是"递归"。
递归经过一番资料查阅,小伙子终于知道问题出在哪。
 行7:既然确定是一个文件夹路径,那就再次调用函数 print all path把一个问题拆解成小问题,一个函数代表一个问题的解决方案。当函数中再次调用自身,即为递归
行7:既然确定是一个文件夹路径,那就再次调用函数 print all path把一个问题拆解成小问题,一个函数代表一个问题的解决方案。当函数中再次调用自身,即为递归小伙在自己电脑上验证一番,发现确实可以达到要求。自信满满上传到网站上,却提示:"调用栈溢出!"
这就是递归的缺点,太内卷(内耗严重)了。显然,这题目的目的不仅仅是学习递归思维,而是充分了解其优缺点。
递归的过程要了解优缺点,必须深入了解递归的流程。
假设目前文件夹的子文件夹深度有3层,那么调用流程如下图:
 可以看到,每当遇到有子文件夹,就会马上再次调用函数,进入下一层的调用
可以看到,每当遇到有子文件夹,就会马上再次调用函数,进入下一层的调用但是要注意,当执行到上图第三层的时候,前面的第一,二层的函数只是执行到一半而已,一个函数没有执行完毕,后续第三层函数执行结束后,要跳回去第二层继续执行。但是 python 怎么保存前面层的调用信息(每一层的变量数据,执行到哪一行等信息)?
这里的第三层只要没有文件夹,那么它自然不会再次调用函数,最后就会结束。这是递归的退出条件,必须保证递归存在退出条件,否则就是死循环
在 python 中,函数的调用信息保存在一个叫帧的东西里面,我以前就有相关文章讲解,相关链接放在文末
这就是调用栈发挥作用的时候。看下图:
 0层调用函数,先把当前层帧放入栈,然后执行1层代码
0层调用函数,先把当前层帧放入栈,然后执行1层代码 1层执行到行7,再次调用函数,此层放入栈
1层执行到行7,再次调用函数,此层放入栈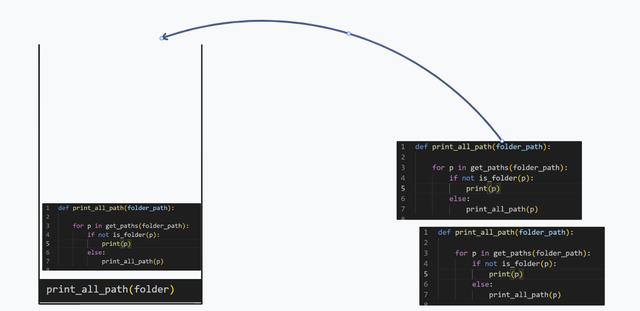
 03 层函数由于没有文件夹,所以没有调用函数,正常结束,销毁
03 层函数由于没有文件夹,所以没有调用函数,正常结束,销毁
 03 层销毁后,python 会从栈顶层取出帧,然后接着执行。如此类推,直到栈中没有东西,程序就会执行结束
03 层销毁后,python 会从栈顶层取出帧,然后接着执行。如此类推,直到栈中没有东西,程序就会执行结束这里我们需要关注的重点就是左边的容器
左边类似木桶的容器叫 栈。不用想复杂了,大家可以把它看成是遵守某些规则的 list往 栈 中放入一个东西, 只能从"木桶口"进入 ,一个个堆叠起来,不允许插队往 栈 中取出一个东西, 只能从"木桶口"最上面取所以,栈的规则可以简化成"先进后出"。首先进入的东西,反而比后来进入的东西,要靠后才能出去。那么,为什么说递归太"内卷"了?因为如果文件夹层级很深,那么调用栈就会堆积大量的调用信息,而调用栈的容量有限,很容易出现栈溢出。
小伙子了解到这些知识后,感觉到自己无法解决,只能查看提示——“模拟栈。用 list 保存,可存放容量比调用栈容量大得多”
用 list 模拟栈回到一开始的思路:
这是一个不确定结束条件的循环,不能使用确定性条件的 for 循环修改为无限循环
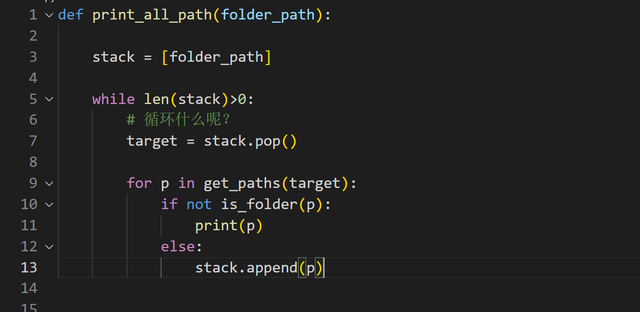 行3:创建一个 list,大家可以把它看作是待处理任务列表。显然第一个任务就是传进来的文件夹路径行5:使用 while 循环,条件是所有任务都处理完毕(任务列表为空)行7:循环里面,每次取出一个任务(文件夹路径),得到该文件夹中的所有路径行13:如果是文件夹路径,那就是一个新的任务,直接放进去任务列表中(stack)
行3:创建一个 list,大家可以把它看作是待处理任务列表。显然第一个任务就是传进来的文件夹路径行5:使用 while 循环,条件是所有任务都处理完毕(任务列表为空)行7:循环里面,每次取出一个任务(文件夹路径),得到该文件夹中的所有路径行13:如果是文件夹路径,那就是一个新的任务,直接放进去任务列表中(stack)小伙子非常满意,感觉自己的 python 水平大幅提升。但是题目竟然还没有结束。
题目提示:"恭喜你,解决了问题。不过,现在函数不能应对需求变化,只能打印路径。请把函数中对路径的处理代码移除,又能保证调用者可以灵活使用"
小伙子随便想一下,就可以想到3种实现方式:
用一个 list 保存结果,最后返回函数新增一个参数,是一个"可调用"的对象,让调用者定义处理函数用生成器返回结果生成器把一个函数变得通用,本质上就是把处理逻辑交给调用者。python 中使用 yield 返回生成器结果是最方便的。
 仅仅在打印路径的地方,修改为 yield p ,把路径"临时"返回
仅仅在打印路径的地方,修改为 yield p ,把路径"临时"返回调用者就像处理集合的方式,就可以执行自己的逻辑。

不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。
推荐文章:
