你有想过在 pandas 中直接使用 sql吗?我知道许多小伙伴已经知道一些库也可以做到这种体验,不过他们的性能太差劲了(基于sqlite,或其他服务端数据库)。
今天我要介绍另一个专用于数据分析的列式数据库,性能是其他同体验的库的1000倍以上。可以无缝接入 pandas ,做到了性能与使用体验同时提升。
这就是今天的主角,duckdb。
特点duckdb 是一个单机数据库,你大概率会用它与 sqlite 比较。
最明显的区别就是,duckdb 是一个分析数据管理系统,而 sqlite 是一个事务型关系数据库。
这意味着,如果你现在有一大堆数据处理任务,期间无须顾忌会有其他用户插入新数据或删除数据。那么 duckdb 就可以非常好应对这种场景。
对于我们这种 pandas 老用户,duckdb 支持 pandas 的 dataFrame 通用底层格式(parquet/arrow等)上并行运行查询,而且没有单独的导入步骤。这就是它能保持使用体验的同时,大幅提升查询性能的最大原因。
我们需要安装这些库
pip install pandas duckdb -U
先看一个例子,看看它是如何便捷与 dataframe 交互。
变量等于表名?首先,导入今天需要用到的库

我们有一大堆销售数据,加载其中一份数据看看:
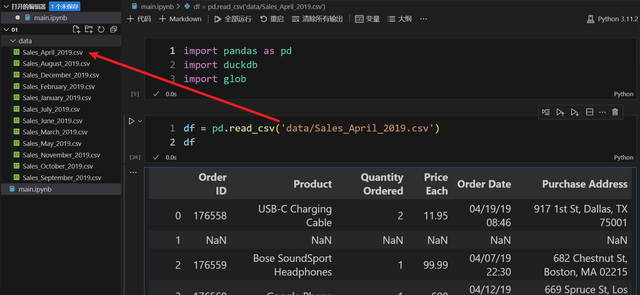
此时,希望使用 sql 做一些数据查询处理,你认为下面的 sql 简单吗?
 直接使用 dataframe 的变量名作为表名查询
直接使用 dataframe 的变量名作为表名查询这真的可以做到吗?加上一点点 duckdb 的调用即可:
 duckdb.query 做查询df,把查询结果转回 dataframe
duckdb.query 做查询df,把查询结果转回 dataframe也就是,可以直接使用当前环境下的变量作为表名。
我知道之前就有其他的库可以做到这种体验,但是必需强调,duckdb 是直接使用 dataframe 的内存数据(因为底层数据格式通用),因此,这个过程中的输入和输出数据的传输时间几乎可以忽略不计。
并且,这个过程中,duckdb比 pandas 更快处理数据(多线程),并且内存使用量也比 pandas 要低得多。
特别在一些需要分组的数据处理任务上,就算只使用单线程的 duckdb 也会比 pandas 的快两倍。如果是过滤+分组+列投影,会存在 5-8倍 的差异。
如果加上表连接,则可能会到 15倍 的差异。
如果使用其他的一些 pandas 使用 sql 的库,比如 pandasSql ,它比 duckdb 性能差距 1000倍 以上!
以上性能对比指标,均是 duckdb 官方说明,以后有机会实际操作对比。
性能方面,就"吹"到这里。但是,我说 duckdb 有极致的使用体验,不仅仅只是可以直接使用 dataframe 变量名作为表名写 sql 。而是它提供了许多 sql 引擎没有的优化语法体验。
sql 的一些语法小痛点,duckdb 也在努力解决现在我们需要加载所有的销售数据文件,如果使用 pandas 加载,则是这样子:
 行3:得到 data 目录下所有 csv 的文件路径行2:使用 pandas 加载
行3:得到 data 目录下所有 csv 的文件路径行2:使用 pandas 加载duckdb提供了许多方便的内置函数:
 行3:表名可以直接是本地的文件。同时还支持通配符
行3:表名可以直接是本地的文件。同时还支持通配符默认情况下,duckdb 会把 csv 的第一行也加入到记录中:

可以使用内置函数,通过参数设定一些加载规则:
 行4: read_csv_auto 可以设置具体加载文件时的设定
行4: read_csv_auto 可以设置具体加载文件时的设定不过,这个 header 参数其实是加载所有数据之后,再设置第一行为表头。所以会看到实际数据仍然有一些表头行:

我们可以直接在条件过滤中一步到位过滤掉无用的行:

此时,我们可以随时切换使用方式。
sql 中有一些语句在特定场景下,会显得"无意义"。比如我希望查询所有的列:

每次都写一句 select * ,有点麻烦。在 duckdb 里面,我们可以直接省略 select 语句。

有时候,我们希望排除某几列,可以这么写:
 行2:使用 * exclude ,里面指定你希望排除的列名即可。注意,因为有一些列名有空格,你需要用双引号或单引号包围
行2:使用 * exclude ,里面指定你希望排除的列名即可。注意,因为有一些列名有空格,你需要用双引号或单引号包围这些功能都得益于它基于的列式数据储存方式。
再看几个小小的 sql 体验改进。
别名用在过滤条件中:

自动识别分组列名:

它还有许多有意思的特性,如果希望我后续做更多的教学,评论区告诉我。
duckdb 是一个很有潜力的数据分析处理工具,结合 pandas 能否大幅提升我们的工作效率,值得大家尝试使用。
不要忘记一键三连。你的点赞、收藏、关注,是我创作的动力。
