编辑:编辑部
【新智元导读】最近,强化学习领域的新会议——RLC在美国马萨诸塞大学召开第一届,颁布了7个组别的杰出论文奖项,并在公开发布的博文中表示,对审稿流程做出了诸多创新和改进。机器学习领域的这个新会值得关注!
首届强化学习会议(Reinforcement Learning Conference,RLC)在马萨诸塞大学阿默斯特分校举行,从8月9日持续到12日。

与典型的大型机器学习会议相比,RLC为强化学习为研究人员提供了一个小而专的场所,供他们来交流和分享相关研究成果。被RLC接收的论文将被发表在《强化学习期刊》上。
今天,RLC 2024杰出论文奖公布,今年的奖项包括七篇论文,每个类别一篇。
会议官方发布推特向所有获奖作者表示祝贺!

新会议,新评审
作为新生的会议,RLC可以承担一些令人兴奋的风险,并尝试解决学术社区中的一些顽疾,其中最关键的就是创建一个严格、高效但完全不同的审稿流程。
比如前段时间引起争议的NeuralPS审稿草率、标准不一致等问题,甚至让LeCun都下场关注。
组委会在官网表示,RLC的评审优先考虑方法论的严谨性,而非对论文重要性的感知。
此外,项目主席Martha White、Adam White和Feyral Behbahani三人提出了一种新的审稿流程,与典型的 NeurIPS/ICLR/ICML审核流程明显不同:
对论文正确性设定了很高的技术准入门槛评审意见「重质不重量」,专注于少量的高质量评论,低质量的评审意见将会被直接抛出;无论是否被接受,论文作者都会收到详细反馈审稿人不负责判断某种方法的新颖性或影响力,因为学术社区会自发「用参考文献投票」,他们只需判断研究的技术正确性,这会大大减轻审稿人的负担,从而提供更全面的评审意见每篇论文的评审都由高年级博士生和高级审稿人配对组成,前者关注技术正确性,后者复核评审意见并提供更高层次的视角;同时,博士生还能获得审稿方面的指导和成长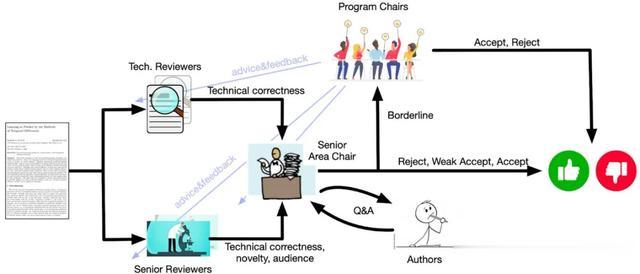
从这几个要点来看,RLC组委会很敏锐地捕捉到了当今AI顶会审稿的几个饱受诟病的痛点,包括审稿人负担过重、评审员标准参差不齐、评审意见过于模糊等等。
关于审稿流程的详细信息已经在官网发布。

https://rl-conference.cc/review_guidelines.html
这种改进的效果究竟如何?组委会又在官网发了一篇博文进行探讨和反思。

https://rl-conference.cc/blogs/review_process.html
为了给予每种类型的论文应有的认可、增强获奖论文的多样性,RLC组委会选择了分7个类别分别评奖,让那些在传统评审过程中容易被埋没的优秀研究脱颖而出。
此外,这样也可以将论文奖项与新颖性、影响力、高性能得分或论文主题分开,专注于挖掘在某个方面非常出色的论文,同时接受它们在其他方面可能存在不足。

这7个组别分别是:
强化学习研究中的实证方法强化学习研究支持工具强化学习应用强化学习中的经验资源强化学习中的开创性视野强化学习中的科学理解强化学习理论
根据会议幻灯片和官方博客的披露,杰出论文奖项的评审流程分为三个步骤:
阅读全部论文的摘要和meta-review(不仅限于评审人提名的论文), 从被接受的113篇论文中选出大约50篇进一步阅读评审意见以及论文本身的关键部分,将名单缩短至每个类别2~3篇具体考虑论文组别的划分通过在所有接受论文中筛选,可以让所有文章都有机会获得奖项认可,并考虑评审过程之外的其他建议,提高稳健性。
同时,作为新生的会议,RLC较小的体量也使得这种机制成为可能。
可喜的是,按照这个流程,评审委员会对每个组别的奖项都做出了一致的选择!

杰出论文奖
强化学习理论该组别的获奖论文由两位华人作者Wanqiao Xu和Shi Dong(董仕)和他们的导师共同完成。两位都是清华校友,且在斯坦福师出同门,博士导师为Benjamin Van Roy。
作者:W. Xu, S. Dong, B. Van Roy
机构:斯坦福大学、谷歌DeepMind

论文地址:https://rlj.cs.umass.edu/2024/papers/RLJ_RLC_2024_277.pdf
这篇论文为尚未得到充分研究的持续性强化学习问题开发了一种新的探索方法,将最初为片段式环境(episodic setting)设计的后验采样算法扩展到持续性环境(continuing setting)。
这种方法对现有方法进行了重新解释,即在每个时间步对策略进行重采样,而非仅在每个episode开始时。这种方法在高维状态空间中也有效。
智能体可以利用重采样概率动态调整其规划范围,从而更好地处理无限范围问题(infinite-horizon problem)。
这篇论文因其理论严谨性而脱颖而出,是首批将算法适用于持续性环境的论文之一,可能成为该领域更多研究的催化剂。
Wanqiao Xu
Xu是斯坦福大学的三年级博士生,本科曾就读于清华大学建筑系,之后转学至密歇根大学获得数学学士学位,同时辅修计算机科学。

她的研究兴趣主要在于强化学习,在复杂且不确定的环境中设计出可以高效决策的智能体,同时也关注语言模型RLHF微调的原则性方法。
Shi Dong(董仕)
董仕现在是谷歌DeepMind的研究科学家,此前,他曾担任微软知识与语言团队的高级研究员,曾与姚班校友、Zoom的现任GenAI 科学负责人Chenguang Zhu合作。
董仕博士毕业于斯坦福大学,博士阶段开发了一个用于强化学习研究的通用多功能框架,同时辅修了管理科学与工程的博士学位。
出于对自然语言的热爱,他现在致力于理解和释放强化学习在大语言模型(LLM)中的潜力。
就读博士前,Dong曾在斯坦福获得统计学硕士学位,本科就读于清华大学电子工程系,并前往巴黎中央理工学院进行过一年交换。
除了研究之外,Dong还是英国历史和文化的忠实粉丝。
 强化学习应用
强化学习应用作者:M. Vasco, T. Seno, K. Kawamoto, K. Subramanian, P. R. Wurman, P. Stone
机构:瑞典皇家理工学院、Sony AI

论文地址:https://rlj.cs.umass.edu/2024/papers/RLJ_RLC_2024_213.pdf
这篇论文首次展示了强化学习智能体在高保真赛车模拟器中,仅依靠局部特征,就能在执行时达到超过人类水平的表现。
此前,这只能通过依赖全局特征或特殊信息来实现,而这些在实际中是不可行的。
因此,这项工作意味着强化学习在自动驾驶赛车的应用方面取得了重大进展。
强化学习研究中的实证方法作者:K. Javed, A. Sharifnassab, R. S. Sutton
机构:阿尔伯塔大学

论文地址:https://rlj.cs.umass.edu/2024/papers/RLJ_RLC_2024_111.pdf
这篇论文提出了一种新的在线时序差分算法,用于解决强化学习中的预测问题,并在使用线性函数逼近时表现出强大的实证性能。
这篇论文的获奖理由是:实验的全面性、广度和深度。作者提供了超越常规的实证证据,展示了算法的工作原理。
比如,论文的实验包括消融所有相关组件、可视化每个像素的预测和分配的置信度、对所有基线进行广泛的超参数搜索等。
强化学习中的经验资源作者:A. Raffin, O. Sigaud, J. Kober, A. Albu-Schaeffer, J. Silvério, F. Stulp
机构:德国航空航天中心(DLR)、索邦大学、代尔夫特理工大学

论文地址:https://rlj.cs.umass.edu/2024/papers/RLJ_RLC_2024_18.pdf
这篇论文引入了一种简单、低成本的方法,挑战了强化学习中的常见实践——该方法在运动任务上可与最先进的深度强化学习算法竞争。
通过使用简单的振荡器生成周期性的关节运动,这种方法让四足机器人在模拟环境和迁移到现实世界时都有出色的表现,进一步突出了其实用性。
这篇论文提出了一个有趣的讨论,即使用深度强化学习时,成本、复杂性和通用性之间的权衡,使其为强化学习中的经验资源做出了有价值的贡献。
强化学习中的开创性视野作者:C. Cousins, K. Asadi, E. Lobo, M. Littman
机构:马萨诸塞大学、亚马逊、布朗大学

论文地址:https://rlj.cs.umass.edu/2024/papers/RLJ_RLC_2024_133.pdf
本文引入了一种新的公平强化学习框架,该框架允许通过福利函数(welfare function)编码不同的社会公平理想,而不是优化对公平性的特定定义。
这种框架可以让机器学习算法在就业、保险、面部识别等现实领域的决策应用中减少人为偏见,实现更好的公平性。
这篇论文因其清晰的阐述、动机和全面的理论结果而脱颖而出。文章在强化学习中的公平性方面的开创性视野为新的研究方向打开了大门,让社会和其他相关方就公平性的概念达成共识,而非由算法设计者决定。
强化学习中的科学理解作者:M. Suau, M. T. J. Spaan, F. A. Oliehoek
机构:代尔夫特理工大学

论文地址:https://rlj.cs.umass.edu/2024/papers/RLJ_RLC_2024_216.pdf
这篇论文加深了我们对强化学习智能体在测试时为何难以泛化到新场景的科学理解,为开发更稳健的强化学习算法提供了基础。
论文从因果关系的视角描述了策略混杂(policy confounding)现象,即在遵循特定轨迹时,强化学习智能体可能会基于虚假相关性(观察与奖励之间)学习行为,因为策略与数据是混淆的。
论文显示,基于策略的算法(on-policy algorithm)可以学习到由最优策略导出的轨迹的表征,但不一定能很好地泛化到新状态,使得智能体对环境动态变化不够稳健。
强化学习研究支持工具作者:D. Corsi, D. Camponogara, A. Farinelli
机构:加州大学尔湾分校、维罗纳大学

论文地址:https://rlj.cs.umass.edu/2024/papers/RLJ_RLC_2024_131.pdf
这篇论文使用真实世界数据开发了一个用于水域导航的模拟器,并将其作为强化学习算法的新基准。
由于复杂的流体动力学导致了不可预测和非平稳的动态,水域环境对强化学习算法构成了挑战。强化学习经常受益于设计新模拟器的工作,这些模拟器捕捉了受关注问题的不同方面,而该环境很可能成为其中之一。
为水域导航设计强化学习算法是一个新颖的应用,可能具有重要的实际意义,使这项工作对强化学习研究支持工具的发展做出了宝贵贡献。
参考资料:
https://rl-conference.cc/blogs/paper_awards.html
https://x.com/RL_Conference/status/1822428132739006703
