在数据科学和分析中,理解高维数据集中的底层模式是至关重要的。t-SNE已成为高维数据可视化的有力工具。它通过将数据投射到
在不断发展的大型语言模型(LLMs)领域中,用于支持这些模型的工具和技术正以与模型本身一样快的速度进步。在这篇文章中,我
ORPO是一种新的微调技术,它将传统的监督微调和偏好对齐阶段结合到一个过程中。减少了训练所需的计算资源和时间。论文的实证
时间序列数据的特征工程是一种技术,用于从时间序列数据中提取信息或构造特征,这些特征可用于提高机器学习模型的性能。以下是一
关于检索增强生成(RAG)的文章已经有很多了,如果我们能创建出可训练的检索器,或者说整个RAG可以像微调大型语言模型(L
这篇文章将演示如何可视化PyTorch激活层。可视化激活,即模型内各层的输出,对于理解深度神经网络如何处理视觉信息至关重
现在有许多方法可以使大型语言模型(LLM)与人类偏好保持一致。以人类反馈为基础的强化学习(RLHF)是最早的方法之一,并
在我们周围的各个领域,从分子结构到社交网络,再到城市设计结构,到处都有相互关联的图数据。图神经网络(GNN)作为一种强大
在过去的几个月中,时间序列基础模型的发展速度一直在加快,每个月都能看到新模型的发布。从TimeGPT 开始,我们看到了
我们开始看4月的新论文了,这是来自北京大学人工智能研究所、北京大学智能科学与技术学院的研究人员发布的主奇异值和奇异向量适
1、哪种技术有助于减轻基于提示的学习中的偏见?A.微调 Fine-tuningB.数据增强 Data augmentat
在本篇文章,我们将详细讨论推测解码,这是一种可以将LLM推理速度提高约2 - 3倍而不降低任何准确性的方法。我们还将会介
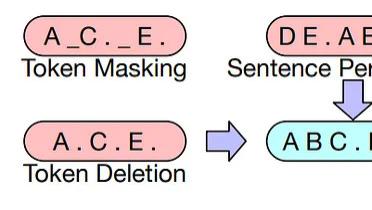
本文将介绍大语言模型中使用的不同令牌遮蔽技术,并比较它们的优点,以及使用Pytorch实现以了解它们的底层工作原理。令牌
如果你一直在关注大型语言模型的架构,你可能会在最新的模型和研究论文中看到“SwiGLU”这个词。SwiGLU可以说是在大
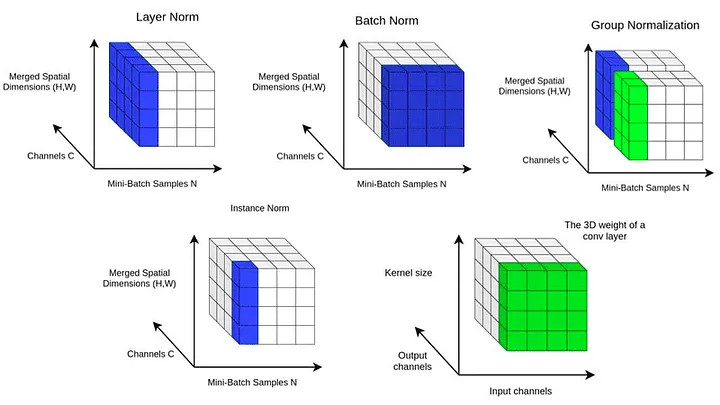
归一化层是深度神经网络体系结构中的关键,在训练过程中确保各层的输入分布一致,这对于高效和稳定的学习至关重要。归一化技术的
分组查询注意力 (Grouped Query Attention) 是一种在大型语言模型中的多查询注意力 (MQA) 和
自 2017 年发表“ Attention Is All You Need ”论文以来,Transformer 架构一直
这是3月26日新发的的论文,微软的研究人员简化的基于mamba的体系结构,并且将其同时应用在图像和时间序列中并且取得了良
大型语言模型(llm)已经变得越来越复杂,能够根据各种提示和问题生成人类质量的文本。但是他们的推理能力让仍然是个问题,与
由于Mixtral的发布,专家混合(MoE)架构在最近几个月变得流行起来。虽然Mixtral和其他MoE架构是从头开始预
签名:提供专业的人工智能知识,包括CV NLP 数据挖掘等