SAM2(Segment Anything 2)是Meta开发的一个新模型,可以对图像中的任何物体进行分割,而不局限于特
根据定义,声音去噪是从音频信号中去除不需要的噪音或干扰,以提高其质量和清晰度的过程。这涉及识别和隔离噪音成分(通常以不规
PyTorch提供了几种张量乘法的方法,每种方法都是不同的,并且有不同的应用。我们来详细介绍每个方法,并且详细解释这些函
以Vision Transformer (ViT)的发现为先导的基于transformer的架构在计算机视觉领域引发了一
精确分割在当今众多领域都是一项关键需求比如说自动驾驶汽车的训练、医学图像识别系统,以及通过卫星图像进行监测。 在许多其他
多元时间序列是一个在大学课程中经常未被提及的话题。但是现实世界的数据通常具有多个维度,所以需要多元时间序列分析技术。在这
大型语言模型(LLMs)通常因为体积过大而无法在消费级硬件上运行。这些模型可能包含数十亿个参数,通常需要配备大量显存的G
决策树是一种非参数的监督学习算法,可用于分类和回归。它使用类似树的结构来表示决策及其潜在结果。决策树易于理解和解释,并且
Adam(W)目前为训练LLM的主流优化器,但其内存开销较大,这是因为Adam优化器需要存储一阶动量m和二阶动量v,总内
选择正确的损失函数对于训练机器学习模型非常重要。不同的损失函数适用于不同类型的问题。本文将总结一些常见的损失函数,并附有
人工智能的世界正在经历一场革命,大型语言模型正处于这场革命的前沿,它们似乎每天都在变得更加强大。从BERT到GPT-3再
在本文中,我们将探讨各种特征选择方法和技术,用以在保持模型评分可接受的情况下减少特征数量。通过减少噪声和冗余信息,模型可
在分类问题中,一个常见的难题是决定输出为数字时各类别之间的切分点。例如,一个神经网络的输出是介于0到1之间的数字,比如0
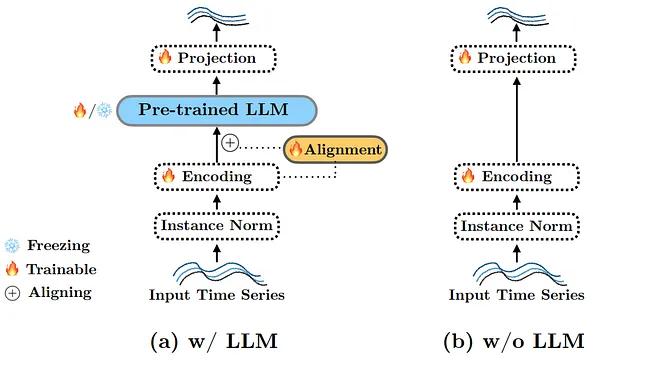
我们已经看到了语言模型的巨大进步,但时间序列任务,如预测呢?今天我们推荐一篇论文,对现有的语言模型和时间序列做了深入的研
DeepSeek-V2是一个强大的开源混合专家(MoE)语言模型,通过创新的Transformer架构实现了经济高效的训
VQ-VAE 是变分自编码器(VAE)的一种改进。这些模型可以用来学习有效的表示。本文将深入研究 VQ-VAE 之前,不
高斯过程其在回归任务中的应用我们都很熟悉了,但是我们一般介绍的都是针对单个任务的,也就是单个输出。本文我们将讨论扩展到多
扩散模型通常是一种生成式深度学习模型,它通过学习去噪过程来创建数据。扩散模型有许多变体,其中最流行的是条件文本模型,能够
TimesFM是一个为时间序列数据量身定制的大型预训练模型——一个无需大量再训练就能提供准确预测的模型。TimesFM有
在深度学习中,优化模型性能至关重要,特别是对于需要快速执行和实时推断的应用。而PyTorch在平衡动态图执行与高性能方面
签名:提供专业的人工智能知识,包括CV NLP 数据挖掘等