导读:算法创新,如何解锁语义理解新高度?
2023年,大模型从年初卷到年末。无论是国内的百模大战格局,还是国外一超多强的新竞争态势,基础模型的能力依然是生成式AI的核心。
对于提升基础模型能力,OpenAI曾提出一个著名的Scaling Law,即模型的参数规模越大、投入的高质量数据越多、投入的算力越多,模型就越强大越智能。这一法则也被称之为伸缩法则或扩展定律。
然而,从算力、数据到算法,各个方面资源均受约束的情况,则是训练基础大模型时面临的常态。比如算力紧缺一卡难求,高质量数据严重不足等。那么,算法的创新能否扛起提升大模型精度的重任?
11月底,浪潮信息的千亿开源模型源2.0在算法创新方面为产业界探索了新的方向。
源2.0采用了一种新型的注意力算法结构LFA(局部注意力过滤增强机制,Localized Filtering-based Attention),对比传统Transformer架构下的注意力机制,LFA对自然语言的关联语义理解更精准,能够显著提升模型精度。
Train Loss是衡量模型精度的指标之一,数值越低意味着模型精度越好。基于 LFA 模型结构,102B的源 2.0模型训练 288B 的 Tokens,最终 Train Loss 为 1.18,相比245B的源 1.0模型,Train Loss 降低了 28%。
这意味着,源2.0打开了一扇新的大门,在无需大幅提升模型参数规模、计算量和内存开销的情况下,通过算法创新也可以实现模型精度的显著提升。

2017年谷歌推出的Transformer架构是当前大语言模型的基础架构,也是这一轮生成式AI浪潮的核心技术底座。虽然Transformer架构具有强大的泛化能力,但并非在所有场景下都有完美表现。对自然语言长序列的处理,以及对序列中的顺序信息的理解就是其短板之一。
Transformer架构中的注意力机制对输入的所有文字一视同仁,不会假设自然语言相邻词之间存在先验的语义关联。而在自然语言中,相邻词之间的语义关联是一个明显特征。
比如,“我想吃重庆火锅”这句话,重庆是修饰火锅的,这两个词之间有更强的依赖关系。
当把这句话丢给一个Transformer架构的大语言模型时,其注意力机制会首先进行分词,我/想/吃/重庆/火锅,即对所有token平均对待,而不会注意到相邻词之间是否存在更强的局部关系。
如果能将相邻词之间的语义关联引入大模型的注意力机制,将获得更精准的自然语言理解能力,从而提升大语言模型的精度。
源2.0研发团队首先尝试了常用的EMA算法。EMA(指数移动平均)是在处理时序数据时一种比较经典的考虑局部关系的算法。虽然EMA也能降低Train Loss值,改进模型精度,但会导致内存开销和计算耗时大幅增加,尤其是对千亿规模的模型来说,训练成本太大。
最终,源2.0研发团队采用了两组卷积+RMSNorm的方法,构建了LFA结构。也就是说,依然基于Transformer架构,但在自注意力层中引入了CNN捕捉相邻词的关系。

两组卷积中,卷积核为2,步长为1,然后再经过RMSNorm归一化。第二次卷积后,相邻词之间的关系又被传递到下一个词,相当于能够捕捉到三个相邻词之间的关系。
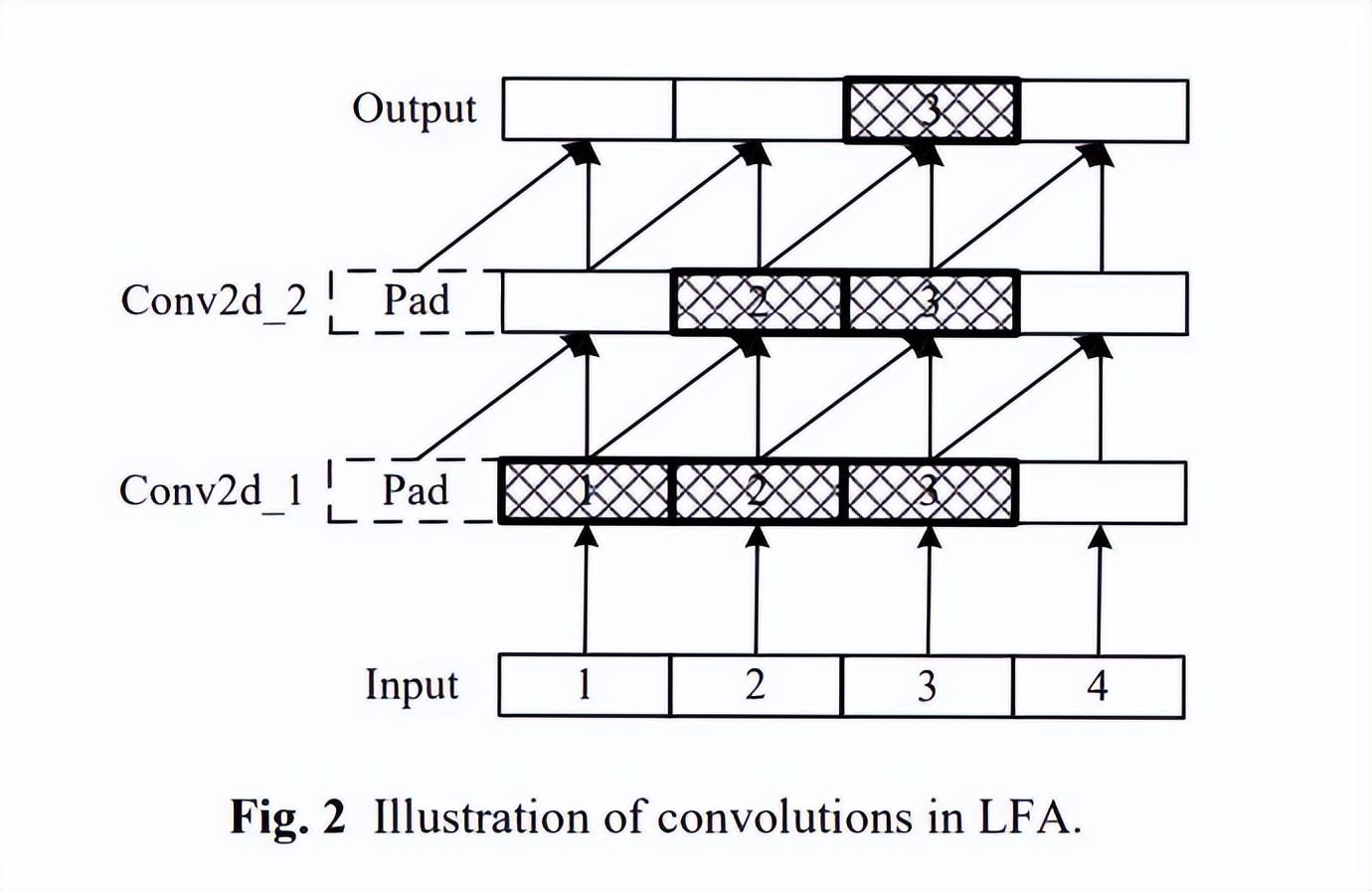
以“有只猫在吃东西”这句话为例,第二次卷积后,注意力机制能够覆盖三个相邻词之间的局部关系,如:(空格,有),((空格,有),只),((有,只),猫),((只,猫),在),((猫,在),吃),((在,吃),东西)。

从源2.0技术论文中的消融实验可以看出,basic是LLaMA结构即传统Transformer注意力机制,对比之下,LFA结构的模型可以将Train Loss值从1.251降低到1.2069,而模型参数和训练耗时的增加并不明显。

基于LFA结构的算法创新,源2.0探索出一个在有限算力资源、有限数据质量、有限参数规模的情况下,提升模型精度的新方向。
这种算法创新加上数据、算力层面的创新,也让源2.0在数理逻辑、代码生成、知识问答、中英文翻译、语义理解等方面的能力大幅提升,实现了对源1.0的全面超越。
在源2.0的技术论文中,浪潮信息公布了源2.0在多个权威评测中的表现,包括:面向代码生成任务的基准测试HumanEval、用于数学问题求解的测试GSM-8K、用来评估标准化考试的基准测试AGIEval、事实性问答测试 TruthfulQA等。
从测试结果看,源2.0在精准度方面全面超过了ChatGPT,并在某些测试上接近GPT4的水平。

在HumanEval评测集上,使用了SC(自洽性,Self-Consistency)方法的源2.0准确率达到77.4%。

在AGIEval测试中,源2.0已经可以对相当复杂的高考数学题进行完美解答。源2.0的回答,无论是推理思路、求解过程,还是符号计算和数值计算都非常准确。


“LFA事实上也代表着一个新的研究方向,我们可以沿着这个方向走下去,发现更多更好的局部性结构,来建模自然语言处理或者序列关系。”浪潮信息人工智能软件研发总监吴韶华表示。
以开源方式,聚焦基础模型能力迭代根据北京市经济和信息化局的数据,截止到2023年10月,单是中国国内公开的大模型数量,就已经达到了238个。当最初的粗放式发展过后,国内百模大战的格局必将走向逐渐收敛的阶段。
其中,有战略定力和技术实力能够持续迭代基础模型能力的企业并不多,浪潮信息就是其中之一。目前,浪潮信息在生成式AI领域的布局聚焦在基础模型能力的提升上,而且始终坚持开源路线。
在开源方面,源大模型坚持全面开源,包括开源API、基础模型参数和代码、训练数据集等。

图片来自摄图网
2021年9月推出的2457亿参数的源1.0模型是当时业界最大规模的大语言模型,模型发布后浪潮信息便推出了开源开放计划,目前已经赋能海量开发者基于源1.0进行应用创新。
2023年11月,源2.0基础大模型一经发布即开源,包括1026亿、518亿、21亿三种参数规模。通过算法、数据、算力三大维度的全面创新,源2.0实现了基础模型能力的大幅提升。
同时,源2.0还推出了开源共训计划,所有开发者都可以提出自己的场景需求,源大模型团队会开展相关的数据清洗/收集与模型训练,训练完成后的基础模型会持续开源到社区反馈给开发者,为开发者提供更好的模型基础能力支持。
“大模型开源,能够加速整个产业协同发展,这是它最本质的价值。产业要健康发展,不能说只有一家公司拥有一个非常领先的能力,其他人都没有办法提供类似的能力。生成式AI一定是一个多元化的生态。我们希望这个产业能够百花齐放,能够更加的丰富。” 浪潮信息高级副总裁刘军曾向媒体表示。
目前,能够超越Transformer的下一代模型结构会是什么样子,业界仍处于拆黑盒的探索阶段。
但换一个思路,前沿技术的发展从来不是突进式变化,而是连续演进的。在探索大模型算法结构的发展方向上,当下任何一个微小的技术改进都是尤为踏实的一步。从这点来看,源2.0的算法创新也为业界推开一扇新的大门。
END
本文为「智能进化论」原创作品。
